

Question: the first picture is a guide. the second picture is the set of questions with A meaning true and B meaning false. An example of
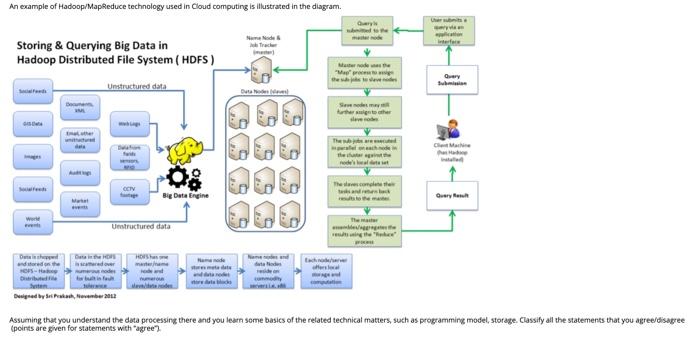


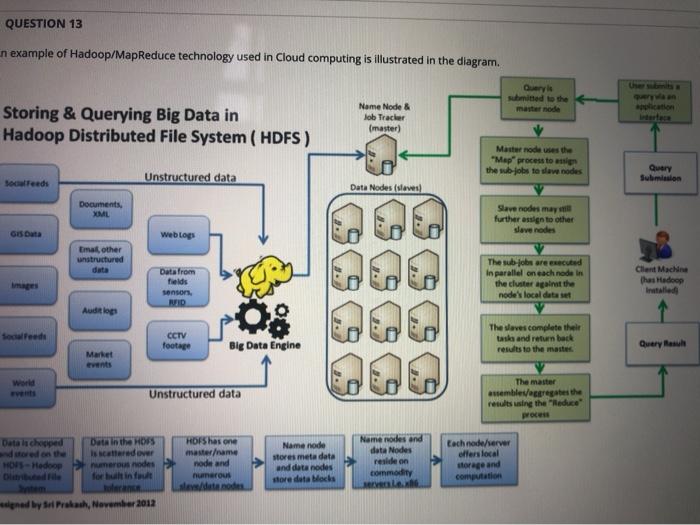
An example of Hadoop/MapReduce technology used in cloud computing is illustrated in the diagram. Storing & Querying Big Data in Hadoop Distributed File System (HDFS) Mode Mae'r te to view Query Unstructured data Send me The wel de the . 08 CON The concerte Big Data Engine www Urastructured data | Each Designed by SP, Member 2012 Assuming that you understand the data processing there and you learn some basics of the related technical matters such as programming model, storage Cassify all the statements that you agree/disagree (points are given for statements with "agree A. MapReduce is designed for processing large volumes of data in parallel by dividing the work into a A. Agree set of independent tasks. B. Disagree The correct sequence of data flow is input-mapper-combiner-reducer-output. The correct sequence of data flow is input-mapper-assigner-reducer-output MapReduce is the data processing layer of Hadoop. MapReduce is an open-source data warehouse system for querying and analyzing large datasets stored in Hadoop files. MapReduce provides resource management. v If a number of reducers are set to O, reduce-only jobs take place. v If a number of reducers are set to O, map-only jobs take place. v If a number of reducers are set to 0, reducer output will be the final output. Reducer maps input key/value pairs to a set of intermediate key/value pairs. The number of maps is usually driven by the total size of inputs. The number of maps is usually driven by the total size of tasks. HDFS is designed for processing large volumes of data in parallel by dividing the work into a set of Independent tasks. node and Name node ore metadata and data nodes more data blocks forbu fault residen comodity offerstoc horas and We node Designed by Sri Pras, Nevember 2012 Assuming that you understand the data processing there and you learn some basics of the related technicalm (points are given for statements with "agree"). Av MapReduce is designed for processing large volumes of data in parallel by dividing the work into a A. Ag set of independent tasks B. Dis The correct sequence of data flow is input-mapper-combiner-reducer-output. The correct sequence of data flow is input-mapper-assigner-reducer-output MapReduce is the data processing layer of Hadoop. MapReduce is an open-source data warehouse system for querying and analyzing large datasets stored in Hadoop files MapReduce provides resource management If a number of reducers are set to 0, reduce-only jobs take place. If a number of reducers are set to O, map-only jobs take place. If a number of reducers are set to 0, reducer output will be the final output. Reducer maps input key/value pairs to a set of intermediate key/value pairs. The number of maps is usually driven by the total size of inputs. The number of maps is usually driven by the total size of tasks. HDFS is designed for processing large volumes of data in parallel by dividing the work into a set of Independent tasks QUESTION 14 Which is false for both Hadoop and Spark? QUESTION 13 n example of Hadoop/MapReduce technology used in Cloud computing is illustrated in the diagram. Quy master node Storing & Querying Big Data in Hadoop Distributed File System (HDFS) Name Node & lob Tracker (master) Master ode uses the "Map process to en the wb jobs to save nodes Query Submission Doceeds Unstructured data Data Nodes (slaves) Documents, Slave nodes may further assign to other slave nodes Gusta Weblogs mat, other unstructured Data from fields sensor, NVID The sub jobs are executed In parallel on each node in the cluster against the node local data Client Machine thas Hadoop Installed Audit logo Socialfeede CCTV footage Big Data Engine The waves complete thel tasks and return back results to the master Query Resul Market World Unstructured data The master assemblea regates the retults using the Reduce Data chooped HOFS has one Data in the HD is scattered over odes for furt Name modes and data Nodes residen Hedoor Name node stoves metadata and data nodes sore deta Mocks node and numerous sedat node Eachnode/server offers local orage and computation ned by Bal Prabach, November 2012
Step by Step Solution
There are 3 Steps involved in it

Get step-by-step solutions from verified subject matter experts