

Question
The first screenshot shows how the program we are working with works. The second screenshot shows the example required for the problem. If you could

The first screenshot shows how the program we are working with works.
The second screenshot shows the example required for the problem.
If you could add the following functions with the given name and parameters. Then write docstring comments for each function. Write tests functions as well if possible. Much appreciated :D
Note: Solve this problem without the use of the Counter Module.
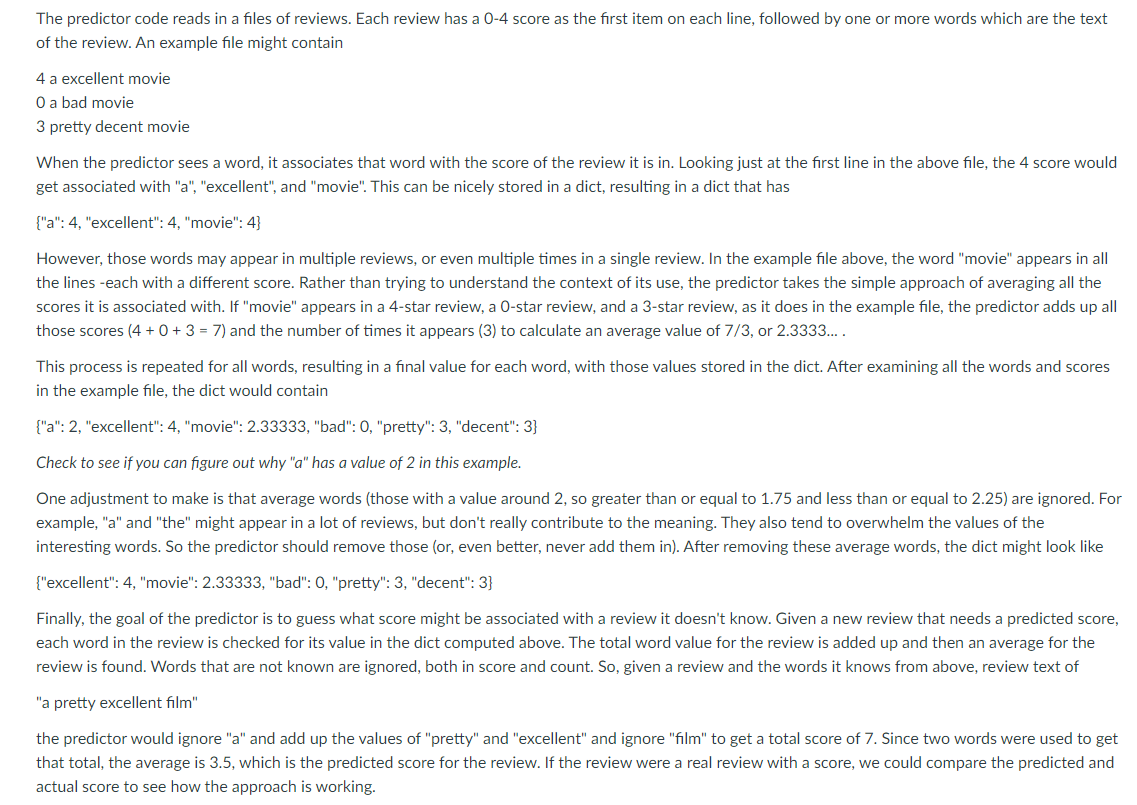
Here is an outline of how the program is structured. . We get the lines from a file of movie reviews. Next, we count up how many times each word appears in all the reviews. This makes a dict of words and their counts. . We add up the total value for every word in all the reviews. This makes a dict of words and their total value. Using the total value dict and word count dict, we make a dict with words and their average value. At this point we have turned the reviews into a bunch of words and their average values. This can now be used for predicting scores. . We can look at each real review, and ignoring its score, predict a score. Then we can compare the real review score with its predicted score. Finally, ask a user for an example review and predict a score. The predictor code reads in a files of reviews. Each review has a 0-4 score as the first item on each line, followed by one or more words which are the text of the review. An example file might contain 4 a excellent movie O a bad movie 3 pretty decent movie When the predictor sees a word, it associates that word with the score of the review it is in. Looking just at the first line in the above file, the 4 score would get associated with "a", "excellent", and "movie". This can be nicely stored in a dict, resulting in a dict that has {"a": 4, "excellent": 4, "movie": 41 However, those words may appear in multiple reviews, or even multiple times in a single review. In the example file above, the word "movie" appears in all the lines -each with a different score. Rather than trying to understand the context of its use, the predictor takes the simple approach of averaging all the scores it is associated with. If "movie" appears in a 4-star review, a 0-star review, and a 3-star review, as it does in the example file, the predictor adds up all those scores (4 +0+ 3 = 7) and the number of times it appears (3) to calculate an average value of 7/3, or 2.3333.... This process is repeated for all words, resulting in a final value for each word, with those values stored in the dict. After examining all the words and scores in the example file, the dict would contain {"a": 2, "excellent": 4, "movie": 2.33333, "bad": 0, "pretty": 3, "decent":3} Check to see if you can figure out why "a" has a value of 2 in this example. One adjustment to make is that average words (those with a value around 2, so greater than or equal to 1.75 and less than or equal to 2.25) are ignored. For example, "a" and "the" might appear in a lot of reviews, but don't really contribute to the meaning. They also tend to overwhelm the values of the interesting words. So the predictor should remove those (or, even better, never add them in). After removing these average words, the dict might look like {"excellent": 4, "movie": 2.33333, "bad": 0, "pretty": 3, "decent":3} Finally, the goal of the predictor is to guess what score might be associated with a review it doesn't know. Given a new review that needs a predicted score, each word in the review is checked for its value in the dict computed above. The total word value for the review is added up and then an average for the review is found. Words that are not known are ignored, both in score and count. So, given a review and the words it knows from above, review text of "a pretty excellent film" the predictor would ignore "a" and add up the values of "pretty" and "excellent" and ignore "film" to get a total score of 7. Since two words were used to get that total, the average is 3.5, which is the predicted score for the review. If the review were a real review with a score, we could compare the predicted and actual score to see how the approach is working. 2. Function name: make_word_total_value_dict_from_lines Parameter: A list of lowercase string values. Each string must start with a number and then have words following. Return value: A dict with every word from the list as keys and the total value of the word (as described above) as the value. See the given example. Comment: You will want to get the starting number from the review and then look at the remaining words. Recall the split method described in class. Here is an outline of how the program is structured. . We get the lines from a file of movie reviews. Next, we count up how many times each word appears in all the reviews. This makes a dict of words and their counts. . We add up the total value for every word in all the reviews. This makes a dict of words and their total value. Using the total value dict and word count dict, we make a dict with words and their average value. At this point we have turned the reviews into a bunch of words and their average values. This can now be used for predicting scores. . We can look at each real review, and ignoring its score, predict a score. Then we can compare the real review score with its predicted score. Finally, ask a user for an example review and predict a score. The predictor code reads in a files of reviews. Each review has a 0-4 score as the first item on each line, followed by one or more words which are the text of the review. An example file might contain 4 a excellent movie O a bad movie 3 pretty decent movie When the predictor sees a word, it associates that word with the score of the review it is in. Looking just at the first line in the above file, the 4 score would get associated with "a", "excellent", and "movie". This can be nicely stored in a dict, resulting in a dict that has {"a": 4, "excellent": 4, "movie": 41 However, those words may appear in multiple reviews, or even multiple times in a single review. In the example file above, the word "movie" appears in all the lines -each with a different score. Rather than trying to understand the context of its use, the predictor takes the simple approach of averaging all the scores it is associated with. If "movie" appears in a 4-star review, a 0-star review, and a 3-star review, as it does in the example file, the predictor adds up all those scores (4 +0+ 3 = 7) and the number of times it appears (3) to calculate an average value of 7/3, or 2.3333.... This process is repeated for all words, resulting in a final value for each word, with those values stored in the dict. After examining all the words and scores in the example file, the dict would contain {"a": 2, "excellent": 4, "movie": 2.33333, "bad": 0, "pretty": 3, "decent":3} Check to see if you can figure out why "a" has a value of 2 in this example. One adjustment to make is that average words (those with a value around 2, so greater than or equal to 1.75 and less than or equal to 2.25) are ignored. For example, "a" and "the" might appear in a lot of reviews, but don't really contribute to the meaning. They also tend to overwhelm the values of the interesting words. So the predictor should remove those (or, even better, never add them in). After removing these average words, the dict might look like {"excellent": 4, "movie": 2.33333, "bad": 0, "pretty": 3, "decent":3} Finally, the goal of the predictor is to guess what score might be associated with a review it doesn't know. Given a new review that needs a predicted score, each word in the review is checked for its value in the dict computed above. The total word value for the review is added up and then an average for the review is found. Words that are not known are ignored, both in score and count. So, given a review and the words it knows from above, review text of "a pretty excellent film" the predictor would ignore "a" and add up the values of "pretty" and "excellent" and ignore "film" to get a total score of 7. Since two words were used to get that total, the average is 3.5, which is the predicted score for the review. If the review were a real review with a score, we could compare the predicted and actual score to see how the approach is working. 2. Function name: make_word_total_value_dict_from_lines Parameter: A list of lowercase string values. Each string must start with a number and then have words following. Return value: A dict with every word from the list as keys and the total value of the word (as described above) as the value. See the given example. Comment: You will want to get the starting number from the review and then look at the remaining words. Recall the split method described in classStep by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
Auditing And Assurance Services
Authors: Alvin Arens, Randal J. Elder
14th Global Edition
0273755013, 978-0273755012