

Question
The Problem There are lots of ways to try to compare the similarity of documents. One way is to focus on the character n-grams that
The Problem
There are lots of ways to try to compare the similarity of documents. One way is to focus on the character n-grams that occur in two tracts of text.
n-grams and text comparison
The n-grams found in a text consists of every sequence of n characters. We are going to record the bigrams found in every word (space separated element) and use the counts from two documents to find their similarity.
Consider the sample sentence fragment:
"the rat race" In order, the bigrams (n=2) would be: th, he, ra, at, ra, ac, ce.
Overall the counts would be th:1, he:1, ra:2, at:1, ce:1. If we take all the spaces out of the sentence to get theratrace, the tri-grams (n=3) would be:
the her era rat atr tra rac ace
Using this information, we could measure the similarity of two documents based on the bigram profile: the list of bigrams and their counts. One (not great) measure is https://en.wikipedia.org/wiki/Cosine_similarity#Ochiai_coefficient . Essentially this would be:
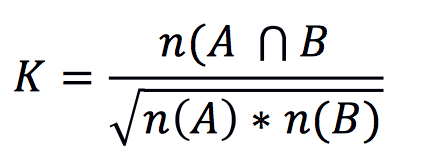
Where n is the number of elements in the two quantities A and B. The measure ranges from 0.0 1.0 . We are going to measure this coefficient for various n-grams of provided documents.
Basic Premise
You are going to build a map
Your Tasks
Complete the Project 7 by writing code for the following functions. Details of type for the functions can be found in functions.h (provided for you, see details below). The
map_to_string : returns a single string of the map
vector_to_string : returns a single string of the argument vector
separated elements. No comma at the end! This vector is convenient for sorting, (can't sort a map) as
you'll see below, see test cases
clean_string : for the provided string argument returns a new string where the only
contents are alphabetic characters in lower case of the argument string
generate_ngrams : for the provided argument string, generates all the ngrams of a given n for
that string. Returns a vector
vector of ngrams, could have repeats).
process_line : does the following
o calls clean_string to clean up the provided string argument o calls generate_ngrams on the string (n is provided as an argument) o records the frequency of the ngrams in the argument map
pair_frequency_greaterthan : takes in two pairs and returns whether the first pair is greaterthan the second pair based on the .second of both pairs.
top_n : return a vector
pair_string_lessthan : takes in two pair and returns whether the first pair is lessthan the second pair based on the .first of both pairs.
ochiai : calculates the ochiai value for the two argument maps. If you use set_intersection to find the intersection set, then pair_string_lessthan is useful.
Test Cases
Test cases are provided in the subdirectory test of the project directory (because it is getting confusing), at least one for each function . However! It is time you start writing your own tests. The tests I provide are not complete, and we are free to write extra tests for grading purposes. Do a good job and test your code. Just because you pass the one (probably simple) test does not necessarily mean your code is fine. Think about your own testing!!!!
Assignment Notes
You are given the following files:
main.cpp This file includes the main function where the test cases will be run.
Do not modify this file.
functions.h This file is the header file for your functions.cpp file. Do not
modify this file.
input#.txt These four text files will be used to run the test cases.
correct_output_#.txt These text files will be used to grade your output based on the
corresponding input files. Be sure that your output matches these text files exactly to
get credit for the test cases.
You will write only functions.cpp and compile that file using functions.h and
main.cpp in the same directory (as you have done in the lab). You are only turning in
functions.cpp for the project.
Comparing outputs: You can use redirected output to compare the output of your program to
the correct output. Use redirected output and the diff command in the Unix terminal to accomplish this:
Run your executable on the desired input file. Lets assume youre testing input1.txt, the first test case. Redirect the output using the following line when in your proj06 directory: ./a.out output1.txt
Now your output is in the file output1.txt. Compare output1.txt to correct_output1.txt using the following line: diff output1.txt correct_output1.txt
If the two files match, nothing will be output to the terminal. Otherwise, diff will print the two outputs.
main.cpp:
#includeusing std::cout; using std::cin; using std::endl; using std::boolalpha; #include using std::setprecision; #include
Step by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started