

Question
The PX 2 is designed to accelerate deep learning or deep neural network algorithms with GPU's. The following figure is an example of deep neural
The PX 2 is designed to accelerate "deep learning" or "deep neural network" algorithms with GPU's. The following figure is an example of deep neural network, where data are received by the input layer from the left, processed through 3 hidden layers, and finally delivered to the output layer to produce the results. Each circle represents a functional node which receives multiple input data from the previous layer, computes a result with a function, and deliver the result to the nodes in the next layer. 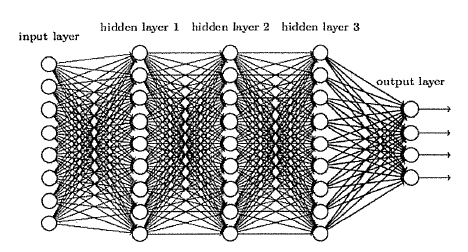
A. Please explain why GPU may be useful for accelerating such an algorithm?
B. Can the deep neural network shown above be implemented by a pipelined datapath? Draw a picture to show how the pipelined data path works.
C. How would pipelining affect the performance, in terms of throughput and latency?
D. As opposed to Nvidia's GPU approach, do you think it is a good idea to design a chip entirely for deep learning? What would be the advantages and disadvantages?
E. For a very large deep neural network, we may want to accelerate it with multiple machines by partitioning the input data. Suppose we have two machines connected with Ethernet, and each machine receives half of the input data. For simplicity, assume every layer has N nodes and each node sends its output data (1 floating point number) to every node in the next layer. How many floating point numbers need to be exchanged between the two machines for one set of input data?
F. Following the previous question, suppose each node takes Ananoseconds to complete its function, each machine has Q processor cores, and the Ethernet has 10Gbps duplex bandwidth (i.e. each direction can transfer at l0Gbitslsec). Please estimate the speedup of the execution time with two machines. (Ignore the network delay and the other overhead in this case)
G. Following the previous question, if we have P machines instead of 2 machines, please estimate the limit of speedup of the execution time, as P approaches infinity.
H. Based on the above, please discuss how you would design system architectures for small, medium, and large deep neural network for best cost-performance? You may use CPUs, GPU, custom-designed chips, FPGA, clusters, etc.
input layer hidden laycr 1 hidden lnyer 2 hidden layer 3 output layerStep by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
Databases And Information Systems 1 International Baltic Conference Dbandis 2020 Tallinn Estonia June 19 2020 Proceedings
Authors: Tarmo Robal ,Hele-Mai Haav ,Jaan Penjam ,Raimundas Matulevicius
1st Edition
303057671X, 978-3030576714