

Question
There are two parts to this problem I need help on: 1) Create dataframe called happy_final and display the shape 2) Drop all nulls and
There are two parts to this problem I need help on:
1) Create dataframe called happy_final and display the shape
2) Drop all nulls and display the dataframe info
Please see the iimage for problem 4 (has two parts)
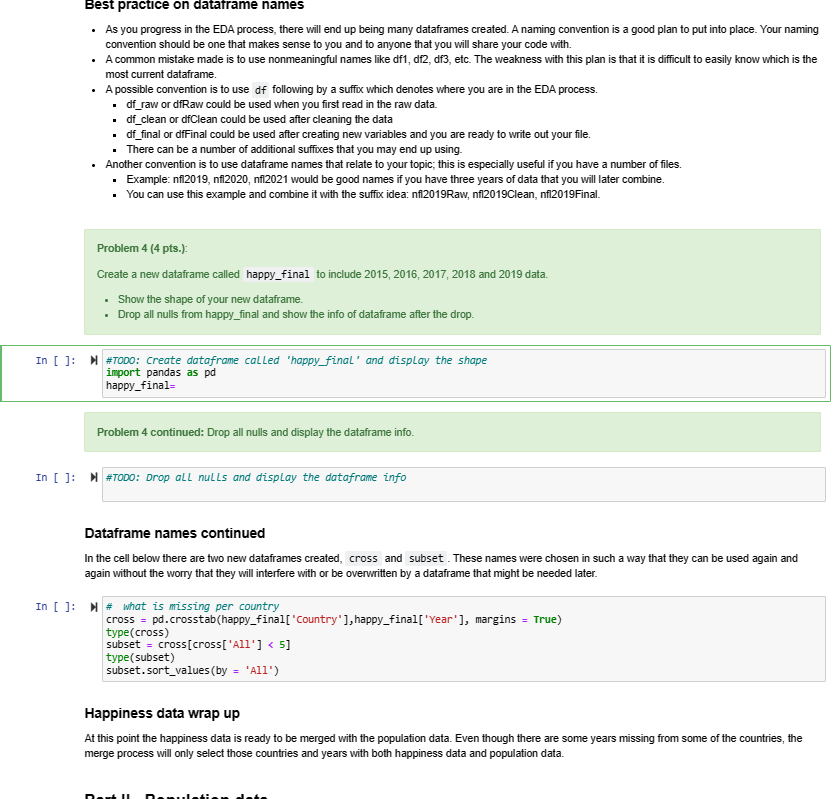
- As you progress in the EDA process, there will end up being many dataframes created. A naming convention is a good plan to put into place. Your naming convention should be one that makes sense to you and to anyone that you will share your code with. - A common mistake made is to use nonmeaningful names like df1, df2, df3, etc. The weakness with this plan is that it is difficult to easily know which is the most current dataframe. - A possible convention is to use df following by a suffix which denotes where you are in the EDA process. - df_raw or dfRaw could be used when you first read in the raw data. - df_clean or dfClean could be used after cleaning the data - dfffinal or dffinal could be used after creating new variables and you are ready to write out your file. - There can be a number of additional suffices that you may end up using. - Another convention is to use dataframe names that relate to your topic; this is especially useful if you have a number of files. - Example: nfl2019, nfl2020, nfl2021 would be good names if you have three years of data that you will later combine. - You can use this example and combine it with the suffix idea: nfl2019Raw, nfl2019Clean, nfl2019Final. Problem 4 (4 pts.): Create a new dataframe called happy_final to include 2015, 2016, 2017, 2018 and 2019 data. - Show the shape of your new dataframe. - Drop all nulls from happy_final and show the info of dataframe after the drop. Problem 4 continued: Drop all nulls and display the dataframe info. Dataframe names continued In the cell below there are two new dataframes created, cross and subset. These names were chosen in such a way that they can be used again and again without the worry that they will interfere with or be overwritten by a dataframe that might be needed later. M what is missing per country cross = pd.crosstab(happy_final['Country'], happy_final['Year'], margins = True) type(cross) subset = cross[cross['Al1']
Step by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
Intelligent Information And Database Systems 6th Asian Conference Aciids 2014 Bangkok Thailand April 7 9 2014 Proceedings Part I 9 2014 Proceedings Part 1 Lnai 8397
Authors: Ngoc-Thanh Nguyen ,Boonwat Attachoo ,Bogdan Trawinski ,Kulwadee Somboonviwat
2014th Edition
3319054759, 978-3319054759