

Question
This is the shorten dataset of Ford vehicle trips in Omaha, Nebraska, sorted by trip_start time. The full size one contains 20,000+ rows of data.
This is the shorten dataset of Ford vehicle trips in Omaha, Nebraska, sorted by trip_start time. The full size one contains 20,000+ rows of data. With that in mind, write a Python program that:
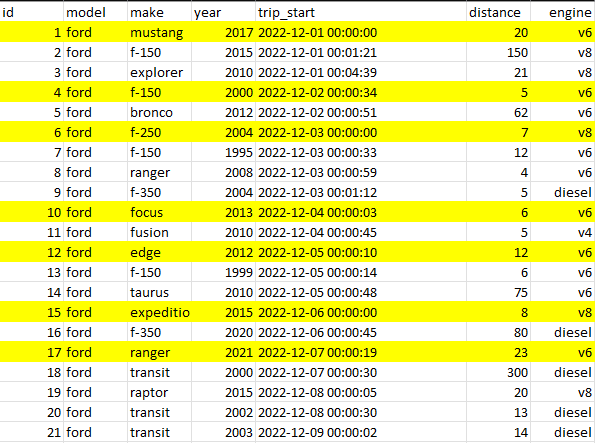
Read the first ride of the day from the data stream, which is the earliest trip_start of the day, and return the year of the vehicle in the first week. Because we only want the first week, only 12-01 to 12-07 should be counted, anything past that should be disregard.
Requirements:
- Use streaming computation methods, with other techniques like MapReduce.
- The data can only be iterated once using yield.
- There can only be 7 elements in your container, for 7 output elements.
Hint:
- You can use ___ = df.values.tolist() to transform the file to a list of lists
- Since the dataset has already been sorted by trip_start, you can just read the first row based on the date section of trip_start.
Final output:
2017
2000
2004
2013
2012
2015
2021
Step by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
Beginning C# 2005 Databases
Authors: Karli Watson
1st Edition
0470044063, 978-0470044063