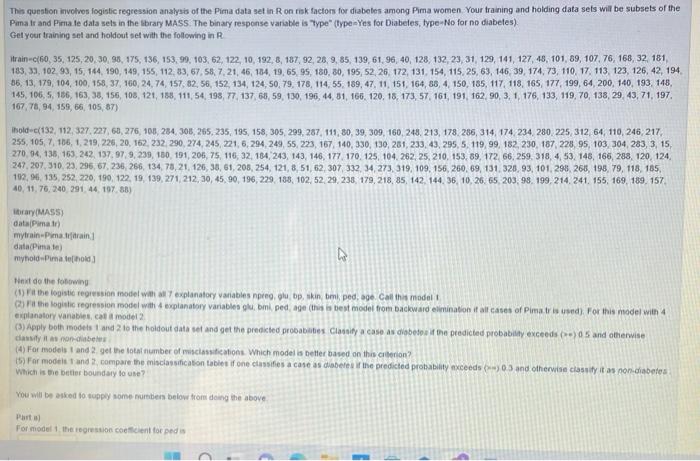
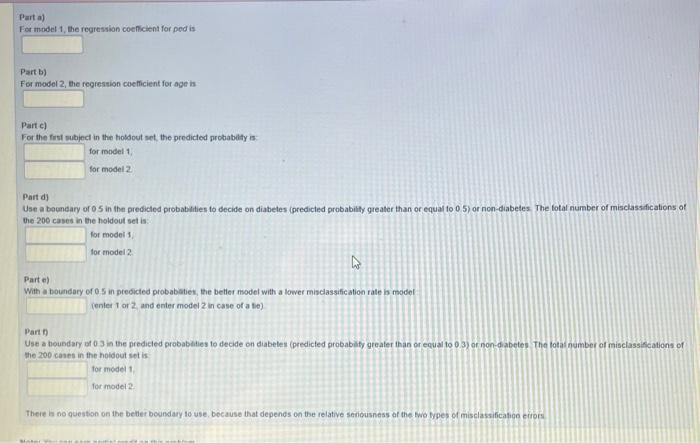
This question involves logistic regression analysis of the Pima data set in Ron risk factors for diabetes among Pima women. Your training and holding data sets will be subsets of the Pima lr and Pima le data sets in the library MASS. The binary response variable is type" (typewYes for Diabetes, type-No for no diabetes) Get your training set and holdout set with the following in R train-C{6035, 125, 20,30, 98, 175, 136, 153, 99, 103, 62, 122, 10, 192, 8, 187, 92, 28, 9,85, 139, 61, 96, 40, 128, 132, 23, 31, 129, 141, 127, 48, 101, 89, 107, 76, 168, 32, 181 183.33, 102.93, 15, 164, 190, 149, 155, 112, 83, 67,58,721, 46, 184, 19,65 95, 180, 80, 195, 52, 26. 172, 131, 154, 115, 25, 63, 146, 39, 174, 73, 110, 17. 113, 123, 126, 42, 194 36, 13, 179, 104, 100, 158, 37, 160, 24, 74, 157, 82, 56, 152, 134, 124, 50, 79, 178, 114, 55, 189, 47, 11, 151, 164,88 4 150, 185, 117, 118, 165, 177, 199, 64,200, 140, 193 148. 145, 106, 5, 186, 163, 38, 156, 108, 121, 158, 111, 54, 198, 77, 137, 68, 59, 130, 196, 44, 31, 166, 120, 15, 173, 57, 161, 191, 162.90, 3, 1, 176, 133, 119,70,138, 29, 43, 71, 197. 167, 78, 94, 159, 66, 105, 87) Tholde(132.112.327.227.60, 275, 100, 284, 305, 265, 235, 195, 158, 305,299, 287, 111, 80, 39, 309, 160, 248, 213, 178 266, 314, 174 234, 280 225, 312, 64, 110, 246, 217, 255, 105.7 166, 1, 219,225,20, 162 232 290,274, 245, 221, 6, 294, 249, 55, 223, 167, 140, 330, 130, 281, 233, 43, 295, 5, 119, 99, 182, 230, 187, 228 95, 103 304 283, 3, 15, 270 04, 136, 163 242. 137.979, 239, 180, 191, 206, 75, 116, 32, 184, 243, 143, 146, 177, 170, 125, 104. 262,25, 210, 153, 69, 172 66,259, 318, 4, 53, 148, 166, 283, 120, 124 247,207,310,23,296, 67, 236, 266, 134, 78,21, 126, 38, 61, 208, 254, 121, 8, 51, 62, 307, 332, 34,273, 319, 109, 156, 260, 69, 131,32893, 101.298, 268, 198, 79, 118, 185 192, , 135, 252, 220, 190, 122, 19, 139, 271, 212, 30, 45.90, 196, 229 188, 102, 5229, 238, 179, 218, 85, 142, 144, 36, 10, 26. 65 203, 98, 199, 214, 241, 155, 169, 189. 157 40, 11, 76,240, 29144, 197, 38) ibrary(MASS) Gatima in mytrainPima train 1 data Pimate myhold-Pimafehold) Het do the following (1) the logistic regression model with all explanatory variables preo, glup skin, om pedage. Call the model Pathologic regression model with explanatory variables glu, bmi pedage (this is best model from backward elimination it all cases of Pimar is used). For this model with 4 explanatory vanabis, cal model 2 (3) Apply both models and to the holtout data set and get the predicted probabies Classify a case as diabetes the predicted probabilly exceeds and otherwise dassy it non diabetes (4) For models 1 and 2 get the total number of ristications which model is better based on this creion? 15) For models and compare the misclassification table if one classifies a case as diabetes the predicted probabilly exceeds and otherwise classify it as non diabetes Which is the better boundary to use? You will be asked to supply some nunten below trom doing the above Part For model the regression coeficient for pedia Parta) For model 1, the regression coefficient for pod is Part 1) For model 2, the regression coefficient for age is Parte) For the first subject in the holdout set the predicted probability is for model 1 for model 2 Part ) Use a boundary or 05 in the predicted probabilities to decide on diabetes (predicted probability greater than or equal to 0 5) or non-diabetes. The total number of misclassifications of the 200 cases in the holdout setis for model for model 2 m Parte) With a boundary of 5 in predicted probabilities, the better model with a lower misclassification rate is model center 1 or 2 and enter model 2 in case of a te) / Part Use a boundary of 0 3 in the predicted probabaties to decide on diabetes (predicted probability greater than or equal to o 3) or non diabetes The total number of misclassifications of the 200 coses in the holdout setis for model 1 for model 2 There is no question on the better boundary so use, because that depends on the relative seriousness of the two types of misclassifications