

Question
% This script contains the codes for the spike sorting problem using time-domain features. % Edit this script to design your own algorithm for feature


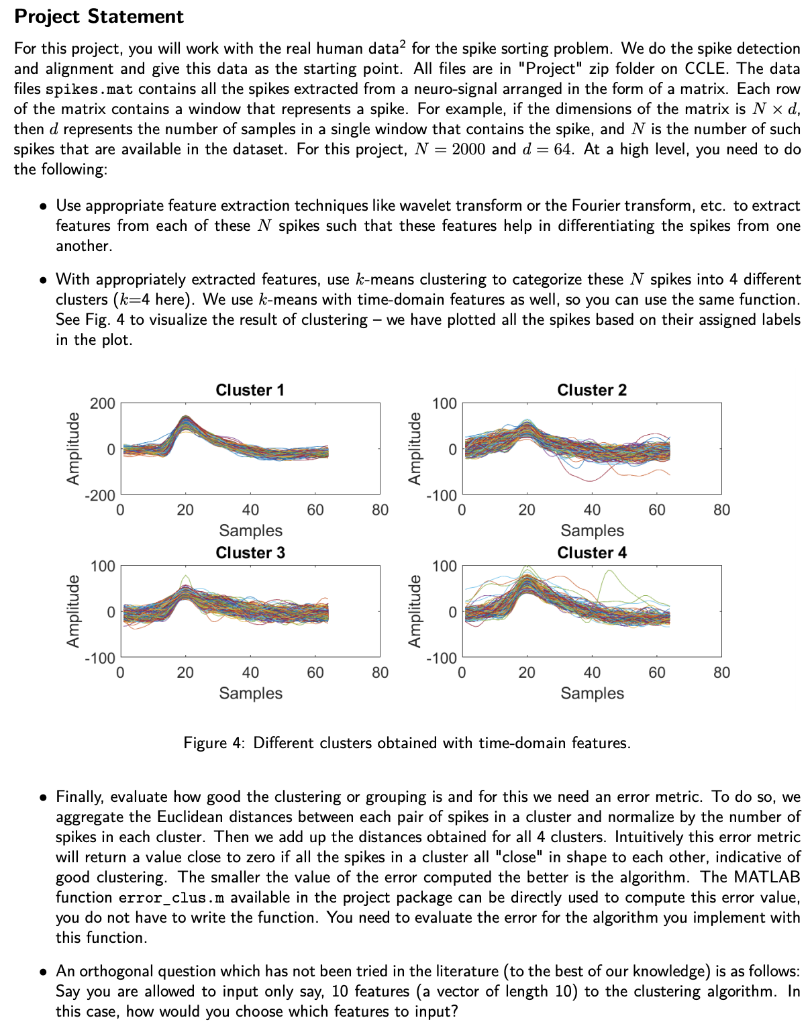
% This script contains the codes for the spike sorting problem using time-domain features. % Edit this script to design your own algorithm for feature extraction and then compare the error with the baseline error obtained using time-domain features.
% Load the spike data that is mentioned in the project description. % Loading will create a variable "spikes" of dimension Nxd (2000x64). % N = number of spike data % d = window size that contains the spike load spikes.mat
N = 2000; %total number of spikes to cluster
spike_data = spikes; %% each row is one spike
no_clus = 4; % set number of clusters
max_iter = 10; % number of iteration runs to find the average error
error_time = 0;
for iter = [1:max_iter] % Perform k-mean clustering directly on the available data without any feature extraction. idx = kmeans(spike_data,no_clus); %% assigns cluster number to each data point
for i = 1:no_clus %%% collect spikes of same cluster and plot subplot(2,2,i); plot(spike_data(idx==i,:)'); xlabel('Samples'); ylabel('Amplitude'); title(['Cluster ' num2str(i)]); % Calling the error_clus function to compute the error (in terms of euclidean distance) between all the spikes that are clustered in one group. error_time = error_time + error_clus(spike_data(idx==i,:)); end end
error_time = error_time/max_iter; % avg of errors scross max_iter runs disp(['Error time = ' num2str(error_time)]); % prints the value in error_time to command line
%% error_features = 0; for iter = 1:max_iter
%% Insert your code here for feature extraction and aggregate the errors over iterations
end
error_features = error_features/max_iter; % avg of errors scross max_iter runs disp(['Error for the proposed technique = ' num2str(error_features)]); % prints the error to command line
1. Download the file "Project.zip" from CCLE, and extract it to a specified folder. This file contains the files error_clus.m, spikes.mat and spike_sort.m. You are allowed to ONLY edit the spike_sort.m file for the project. 2. In spike_sort.m, we have implemented clustering with time-domain features, go through the commented code and understand what we do. Note that using time-domain features is equivalent to not using a feature extraction step. This is the baseline we compare against, and we hope to do better with sophisticated feature extraction techniques. You can use this code snippet as a reference to design your algorithm with a feature extraction step. 3. In the space provided in spike_sort.m, write your own code for feature extraction clustering, run it and compare the error obtained with time-domain features vs. the error obtained with your feature extraction technique. Note that to compute the error, we perform 10 runs of the clustering algorithm and take the average of errors obtained in these 10 cases, we do this since there is an inherent randomness with clustering. You need to try out different feature extraction techniques and report the errors for a few of these. Hint for wavelets: For wavelet features, you can use the function vavedec(.). Some possible choices for wavelets to use are 'haar', 'db2' to 'db4', 'sym2' to 'sym4' etc. Play around with the parameters for wavedec(.) in case you decide to use this. (ii) Feature extraction Clustering: Having obtained N spikes (which are each a M-length vector), we need to group the spikes into clusters based on their shapes. A clustering algorithm (here we use k-means clustering) is used to accomplish this. When the N-spikes are fed as inputs to this algorithm, it assigns one of k labels to each spike; spikes assigned the same label should ideally have similar shapes A naive way to feed the spikes as inputs to the clustering algorithm is to just feed them as M-length vectors obtained from the spike detection; these are called the time-domain features of the spikes. This may, however, not always work well since it may be difficult for an algorithm to "learn" the shape of spikes from the time-domain features; unlike a human, a machine can not always easily identify visual patterns in the Therefore, instead of just feeding the time-domain features as inputs to the clustering algorithm, we transform the data into another domain and feed the transformed data as inputs to the clustering process. This step is called the feature extraction step since it determines what features of the data are relevant for clustering As an example, one could first compute the DFT of the M-length vectors and use these as the inputs for clustering. Another example is that one could compute the Discrete Wavelet transform (DWT) of the M-length vectors and use these as inputs. The reason is that essential information about spike shapes are captured "better" by these transformed features as compared to time-domain features As an example, we have implemented the clustering with time-domain features. Your job is to try out other features that do a better job with clustering. Two potential options are the use of DFT and DWT. You do not have to implement either FFT or DWT, but rather use the in-built MATLAB implementations and try out different hyperparameters (like what resolution you want use in case of FFT or what wavelets and levels you want to use for DWT) to see which one works best Summary: You are given N spikes (each of which are M-length vectors in time domain). The objective is to extract the features of these spikes using various transforms or combinations thereof to see which features work best for clustering Project Statement For this project, you will work with the real human data2 for the spike sorting problem. We do the spike detection and alignment and give this data as the starting point. All files are in "Project" zip folder on CCLE. The data files spikes.mat contains all the spikes extracted from a neuro-signal arranged in the form of a matrix. Each row of the matrix contains a window that represents a spike. For example, if the dimensions of the matrix is N x d then d represents the number of samples in a single window that contains the spike, and N is the number of such spikes that are available in the dataset. For this project, N 2000 and d - 64. At a high level, you need to do the following: Use appropriate feature extraction techniques like wavelet transform or the Fourier transform, etc. to extract features from each of these N spikes such that these features help in differentiating the spikes from one another With appropriately extracted features, use k-means clustering to categorize these N spikes into 4 different clusters (k-4 here). We use k-means with time-domain features as well, so you can use the same function See Fig. 4 to visualize the result of clustering we have plotted all the spikes based on their assigned labels in the plot Cluster 1 Cluster 2 200 100 -200 100 20 40 Samples Cluster 3 60 80 20 40 Samples Cluster 4 60 80 100 100 -100 -100 20 40 Samples 60 80 20 40 Samples 60 80 Figure 4: Different clusters obtained with time-domain features . Finally, evaluate how good the clustering or grouping is and for this we need an error metric. To do so, we aggregate the Euclidean distances between each pair of spikes in a cluster and normalize by the number of spikes in each cluster. Then we add up the distances obtained for all 4 clusters. Intuitively this error metric will return a value close to zero if all the spikes in a cluster all "close" in shape to each other, indicative of good clustering. The smaller the value of the error computed the better is the algorithm. The MATLAB function error clus.m available in the project package can be directly used to compute this error value, you do not have to write the function. You need to evaluate the error for the algorithm you implement with this function An orthogonal question which has not been tried in the literature (to the best of our knowledge) is as follows Say you are allowed to input only say, 10 features (a vector of length 10) to the clustering algorithm. In this case, how would you choose which features to input? 1. Download the file "Project.zip" from CCLE, and extract it to a specified folder. This file contains the files error_clus.m, spikes.mat and spike_sort.m. You are allowed to ONLY edit the spike_sort.m file for the project. 2. In spike_sort.m, we have implemented clustering with time-domain features, go through the commented code and understand what we do. Note that using time-domain features is equivalent to not using a feature extraction step. This is the baseline we compare against, and we hope to do better with sophisticated feature extraction techniques. You can use this code snippet as a reference to design your algorithm with a feature extraction step. 3. In the space provided in spike_sort.m, write your own code for feature extraction clustering, run it and compare the error obtained with time-domain features vs. the error obtained with your feature extraction technique. Note that to compute the error, we perform 10 runs of the clustering algorithm and take the average of errors obtained in these 10 cases, we do this since there is an inherent randomness with clustering. You need to try out different feature extraction techniques and report the errors for a few of these. Hint for wavelets: For wavelet features, you can use the function vavedec(.). Some possible choices for wavelets to use are 'haar', 'db2' to 'db4', 'sym2' to 'sym4' etc. Play around with the parameters for wavedec(.) in case you decide to use this. (ii) Feature extraction Clustering: Having obtained N spikes (which are each a M-length vector), we need to group the spikes into clusters based on their shapes. A clustering algorithm (here we use k-means clustering) is used to accomplish this. When the N-spikes are fed as inputs to this algorithm, it assigns one of k labels to each spike; spikes assigned the same label should ideally have similar shapes A naive way to feed the spikes as inputs to the clustering algorithm is to just feed them as M-length vectors obtained from the spike detection; these are called the time-domain features of the spikes. This may, however, not always work well since it may be difficult for an algorithm to "learn" the shape of spikes from the time-domain features; unlike a human, a machine can not always easily identify visual patterns in the Therefore, instead of just feeding the time-domain features as inputs to the clustering algorithm, we transform the data into another domain and feed the transformed data as inputs to the clustering process. This step is called the feature extraction step since it determines what features of the data are relevant for clustering As an example, one could first compute the DFT of the M-length vectors and use these as the inputs for clustering. Another example is that one could compute the Discrete Wavelet transform (DWT) of the M-length vectors and use these as inputs. The reason is that essential information about spike shapes are captured "better" by these transformed features as compared to time-domain features As an example, we have implemented the clustering with time-domain features. Your job is to try out other features that do a better job with clustering. Two potential options are the use of DFT and DWT. You do not have to implement either FFT or DWT, but rather use the in-built MATLAB implementations and try out different hyperparameters (like what resolution you want use in case of FFT or what wavelets and levels you want to use for DWT) to see which one works best Summary: You are given N spikes (each of which are M-length vectors in time domain). The objective is to extract the features of these spikes using various transforms or combinations thereof to see which features work best for clustering Project Statement For this project, you will work with the real human data2 for the spike sorting problem. We do the spike detection and alignment and give this data as the starting point. All files are in "Project" zip folder on CCLE. The data files spikes.mat contains all the spikes extracted from a neuro-signal arranged in the form of a matrix. Each row of the matrix contains a window that represents a spike. For example, if the dimensions of the matrix is N x d then d represents the number of samples in a single window that contains the spike, and N is the number of such spikes that are available in the dataset. For this project, N 2000 and d - 64. At a high level, you need to do the following: Use appropriate feature extraction techniques like wavelet transform or the Fourier transform, etc. to extract features from each of these N spikes such that these features help in differentiating the spikes from one another With appropriately extracted features, use k-means clustering to categorize these N spikes into 4 different clusters (k-4 here). We use k-means with time-domain features as well, so you can use the same function See Fig. 4 to visualize the result of clustering we have plotted all the spikes based on their assigned labels in the plot Cluster 1 Cluster 2 200 100 -200 100 20 40 Samples Cluster 3 60 80 20 40 Samples Cluster 4 60 80 100 100 -100 -100 20 40 Samples 60 80 20 40 Samples 60 80 Figure 4: Different clusters obtained with time-domain features . Finally, evaluate how good the clustering or grouping is and for this we need an error metric. To do so, we aggregate the Euclidean distances between each pair of spikes in a cluster and normalize by the number of spikes in each cluster. Then we add up the distances obtained for all 4 clusters. Intuitively this error metric will return a value close to zero if all the spikes in a cluster all "close" in shape to each other, indicative of good clustering. The smaller the value of the error computed the better is the algorithm. The MATLAB function error clus.m available in the project package can be directly used to compute this error value, you do not have to write the function. You need to evaluate the error for the algorithm you implement with this function An orthogonal question which has not been tried in the literature (to the best of our knowledge) is as follows Say you are allowed to input only say, 10 features (a vector of length 10) to the clustering algorithm. In this case, how would you choose which features to inputStep by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
Beyond Big Data Using Social MDM To Drive Deep Customer Insight
Authors: Martin Oberhofer, Eberhard Hechler
1st Edition
0133509796, 9780133509793