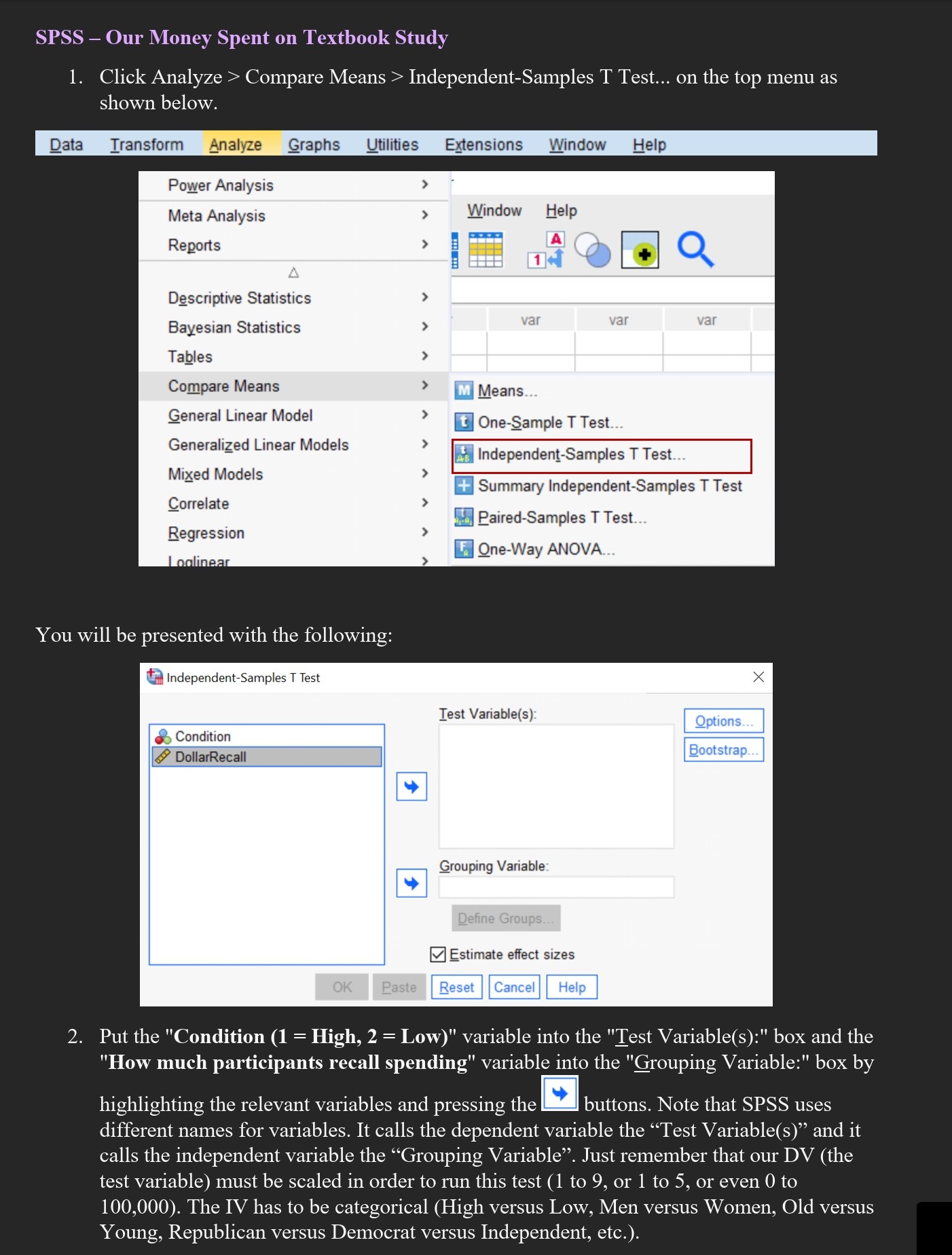
: took Stats I and Methods One at FIU and passed. But do you remember what you did, how you did it, and why you
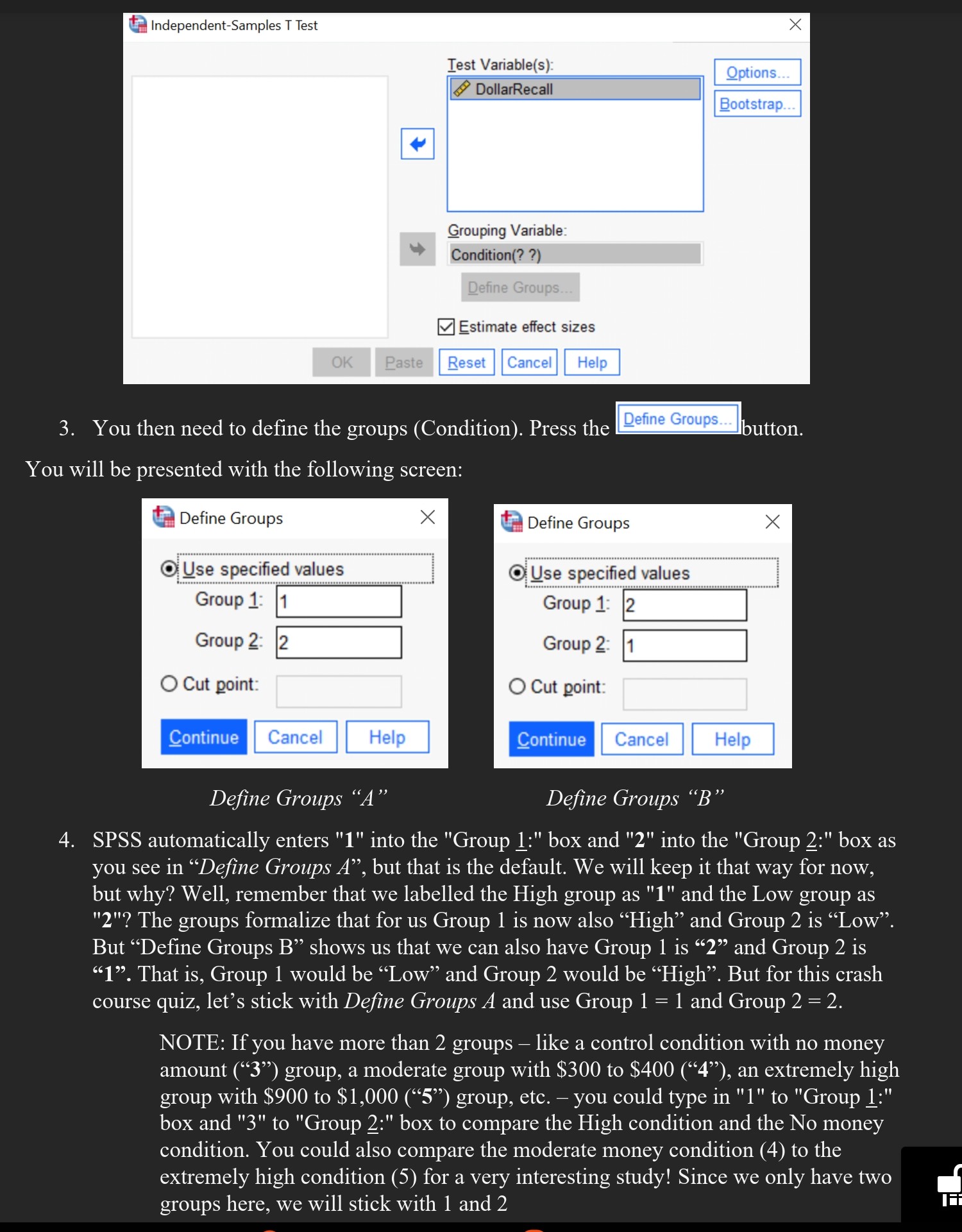
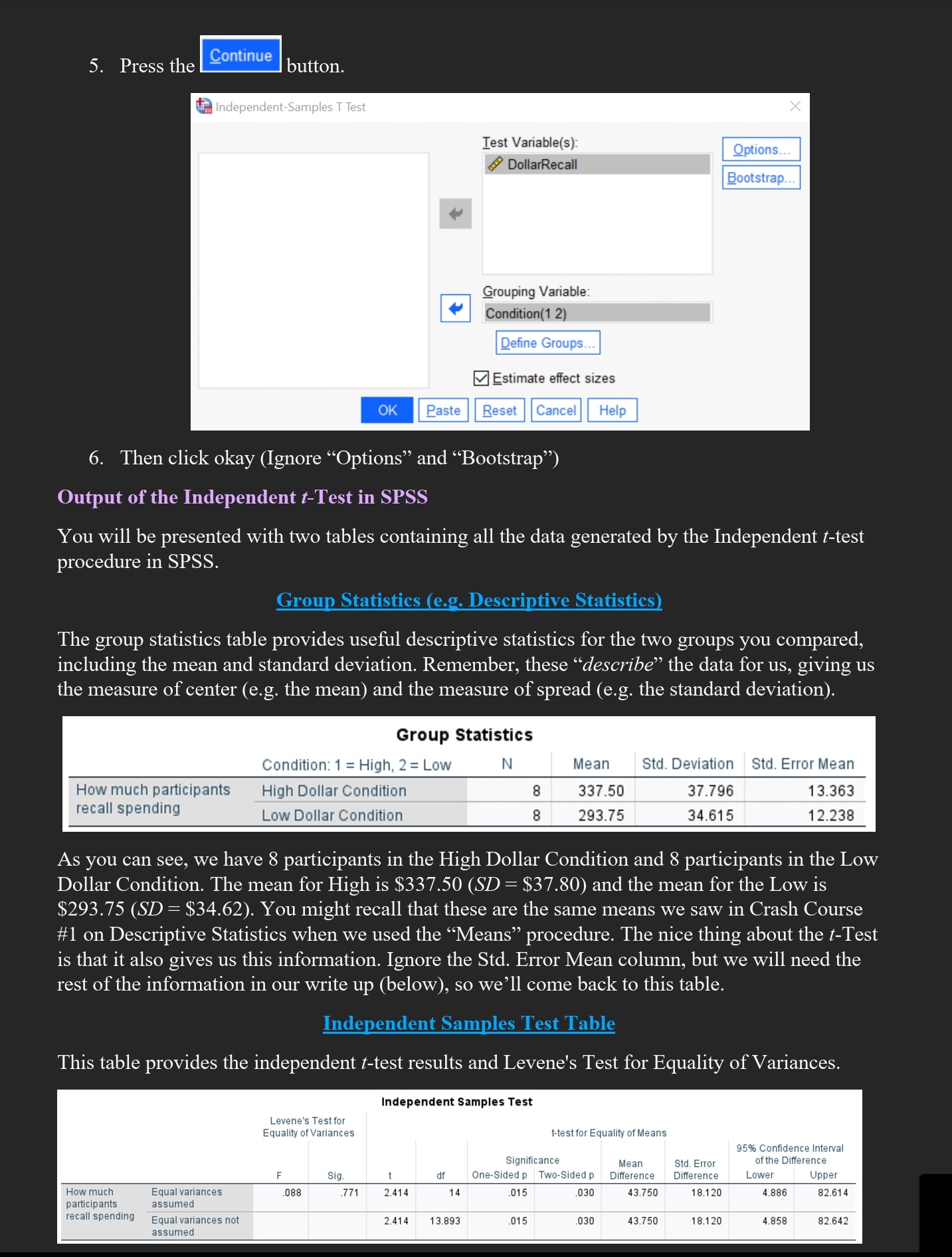
: took Stats I and Methods One at FIU and passed. But do you remember what you did, how you did it, and why you did it? If you need some basic statistic reminders for the #-Test, then this is the lecture for you! I am going to talk about a #-Test example in this document that corresponds to the example you saw in the Descriptive Statistics Crash Course (#1) where participants were asked to recall how much money they spent on textbook the prior semester. While all participants were the eleventh person to write their textbook money recall on a survey the researcher gave them, the researcher actually completed the first ten slots, manipulating the amount prior \"participants\" recalled spending to be either high ($350 to $450) or low ($250 to $350). The researcher predicted that participants who saw high dollar amounts from the first ten participants would recall spending more money on textbooks themselves than participants who saw low dollar amounts from the first ten participants (demonstrating a conformity effect). The good news 1is that this mini-lecture will sum up the basics of the #-Test for you as we look at this study, though you can find additional information about the #-Test in your textbooks. On the final page are several questions based on this crash course. Answer these questions, and then go into your \"Crash Course in Statistics The t-Test Quiz #2\" in your Canvas assessments menu and copy over your answer. Each Crash Course Quiz counts 5 points. How, when, and why do a +-Test? Before we get to the textbook money example, let me give you some basic information about the #-Test. The -Test is used to compare two means to see if they differ significantly from one another. In this analysis, we need several pieces of information: the means for each group and the #-Test information itself. Do you recall what a mean 1s? It is the average score. That is, you add up all of the scores and divide by the number of total scores to arrive at the average. Since a t-Test looks at two different conditions, this implies that you have two means: one for each condition. The means and standard deviation (as you saw in your first crash course quiz) are descriptive statistics. That is, they help describe the data. The #-Test information itself is a test of inferential statistics. That is, we infer significant differences between the two groups. When writing it out, you will see a very common layout for the #-Test, something like: #(14) = 2.61, p = .021. The tells you this is a -Test. The 14 tells us our degrees of freedom (more on that in your lecture material). The 2.61 is the actual number for the r-Test. The p indicates whether it is significant (if it is less than .05, then it is significant). We run a #-Test only under certain conditions. First, our dependent variable (the variable we measure) must be continuous / scaled. That is, the DV has to be along a scale. For example, it can be an attitude (\"On a scale of 1 to 9, how angry are you?\"), a time frame (\"How quickly did the salesperson help the customer on a scale of zero seconds to a thousand seconds?\"), or a dollar amount (\"How much do you recall spending on textbooks last semester?). We call these interval or ratio scales, and they allow us to run a #-Test. In comparison, we CANNOT run a #-Test on categorical data. That is, if we have a yes / no question (\"Are you lonely: Yes or No\") or a category based question (\"What is your favorite food: hamburgers, pizza, salad, or tacos?\"), then we cannot run a t-Test. These latter questions are based more on choice of option rather than an actual rating scale, and thus we cannot use a #-Test on them. Second, we run a #-Test when we have two conditions to compare. That 1s, we compare the mean from Condition A to the mean from Condition B. If our #-Test 1s significant (p , or the symbol for Sigma, means \"the sum of\". Thus ) A4 1s the sum of the scores for Condition A. That is, 350 + 400 + 375 + 350 + 300 + 325 + 300 + 300 = 2700. There are eight scores here, so we divide 2700 / 8 = 337.5, giving us our mean of $337.50 for Condition A { lon). We do the same thing for Condition B (Low Dollar Condition), giving us a mean of $293.75 (2350 / 8 = 293.75). For the first part of our analysis, we compare the means. As you see, $293.75 in the Low Dollar Condition is less money than the $337.50 in High Dollar Condition. Eyeballing this, it looks like participants recall spending more money on books if they see other people reporting a high amount than if they see other people reporting a low amount. Thus the means for the High versus Low Dollar Conditions support our prediction, but we are not done yet. Just because the means seem to differ doesn't mean they do differ. To make that assessment, we run the #-Test and look at the p value to see 1f p <.05. we can do this by hand you did in stats i and methods one or take the easy road let spss calculate it for us. am going to but keep mind that still have interpret what tells next section open run an independent samples use screenshots from as go feel free these analyses yourself. just set up your file like mine also included canvas if prefer that. called a short data so recommend setting own using values table above give basics here refer other sources figure out some of info get not covered lecture levene test normality e t b our money spent on textbook study click analyze> Compare Means > Independent-Samples T Test... on the top menu as shown below. Data Transform Analyze Graphs Ulilities Extensions Window Help Power Analysis Meta Analysis Window Help Reports | m 1 3 _ EI Q Descriptive Statistics Bayesian Statistics Tables Compare Means L Means General Linear Model @ One-Sample T Test... Generalized Linear Models eiac o Ed Summary Independent-Samples T Test E Paired-Samples T Test LAl One-Way ANOVA Correlate Regression You will be presented with the following: d'_-] Independent-Samples T Test Test Variable(s) &> Condition & DollarRecall 2. Put the "Condition (1 = High, 2 = Low)" variable into the "Test Variable(s):" box and the "How much participants recall spending" variable into the "Grouping Variable:" box by highlighting the relevant variables and pressing the buttons. Note that SPSS uses different names for variables. It calls the dependent variable the \"Test Variable(s)\" and it calls the independent variable the \"Grouping Variable\". Just remember that our DV (the test variable) must be scaled in order to run this test (1 to 9, or 1 to 5, or even 0 to 100,000). The IV has to be categorical (High versus Low, Men versus Women, Old versus Young, Republican versus Democrat versus Independent, etc.). t Independent-Samples T Test Test Variable(s) Grouping Variable Condition(? ?) Estimate effect sizes 3. You then need to define the groups (Condition). Press the You will be presented with the following screen: Q Define Groups Group 2: |2 Group 2 O Cut point: O Cut point [OGLIGIER | Cance Define Groups \"A\" Define Groups \"B\" 4. SPSS automatically enters "1" into the "Group 1:" box and "2" into the "Group 2:" box as you see in \"Define Groups A\5. Press the Continue button. Independent-Samples T Test X Test Variable(s): Options. DollarRecall Bootstrap.. Grouping Variable: + Condition(1 2) Define Groups.. Estimate effect sizes OK Paste Reset Cancel Help 6. Then click okay (Ignore "Options" and "Bootstrap") Output of the Independent t-Test in SPSS You will be presented with two tables containing all the data generated by the Independent t-test procedure in SPSS. Group Statistics (e.g. Descriptive Statistics) The group statistics table provides useful descriptive statistics for the two groups you compared, including the mean and standard deviation. Remember, these "describe" the data for us, giving us the measure of center (e.g. the mean) and the measure of spread (e.g. the standard deviation). Group Statistics Condition: 1 = High, 2 = Low N Mean Std. Deviation Std. Error Mean How much participants High Dollar Condition 8 337.50 37.796 13.363 recall spending Low Dollar Condition 8 293.75 34.615 12.238 As you can see, we have 8 participants in the High Dollar Condition and 8 participants in the Low Dollar Condition. The mean for High is $337.50 (SD = $37.80) and the mean for the Low is $293.75 (SD = $34.62). You might recall that these are the same means we saw in Crash Course #1 on Descriptive Statistics when we used the "Means" procedure. The nice thing about the t-Test is that it also gives us this information. Ignore the Std. Error Mean column, but we will need the rest of the information in our write up (below), so we'll come back to this table. Independent Samples Test Table This table provides the independent t-test results and Levene's Test for Equality of Variances. Independent Samples Test Levene's Test for Equality of Variances t-test for Equality of Means 95% Confidence Interval Significance Mean Std. Error of the Difference Sig df One-Sided p 1 p Two-Sided p Difference Difference Lower Upper How much Equal variances .088 .771 2.414 14 . 015 .030 43.750 18.120 4.886 82.614 participants assumed recall spending Equal variances not 2.414 13.893 015 .030 43.750 18.120 4.858 82.642 assumedWe will talk about Levene's test later in the lecture, but I want to ignore it for now. Let me make the output a bit larger so we can interpret it properly. I'll remove several unneeded columns at the end of the table that we don't really need. Independent Samples Test Levene's Test for Equality of Variances t-test for Equality of Means How much Equal variances 1 . 2414 participants assumed recall spending Equal variances not 2414 13893 assumed Above is the important information we will need for our 7-Test (outlined in the red box). We will use the equal variances assumed row (it doesn't differ much from equal variances not assumed anyway, but I prefer to use the df that has a whole number). What we do now is write it up. For the write up, we need both of our tables the descriptive table (with our means and standard deviations) as well as our independent samples 7-Test table. Let me repost the descriptives table below (the \"group statistics\"). The important info is in the green box. Group Statistics Condition: 1 = High, 2 = Low N Mean Std. Deviation ] Std. Error Mean How much participants High Dollar Condition 337.50 37.796 recall spending Low Dollar Condition 293.75 34615 Reporting the output of the independent #-Test We report the statistics n this format: #(degrees of freedom[df]) = t-value, p = significance level. In our case this would be: #(14) = 2.41, p = 0.03, and our means/SDs would be M = 337.50, SD = 37.80 for the High Dollar Condition and M = 293.75, $D = 34.62 for the Low Dollar Condition. We report the results as follows (including $ since we are dealing with money): We ran an independent samples #-Test with Dollar Condition (High versus Low) as our independent variable and how much participants recalled spending (in $) as our dependent variable. The #-Test was significant, #(14) = 2.41, p = .03. Participants recalled spending more money on textbooks in the High Dollar Condition (M = $337.50, SD = $37.80) than in the Low Dollar Condition (M = $293.75, SD = $34.62). Note #1: According to the 7t Edition of the APA publication manual you should use exact p values. Here, p = .03 (rather than p
Step by Step Solution
There are 3 Steps involved in it
Step: 1
Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2
Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance