

Answered step by step
Verified Expert Solution
Question
1 Approved Answer
Why the holdout method for model selection suggests to separate the data into three parts: a training set, a validation set, and a test
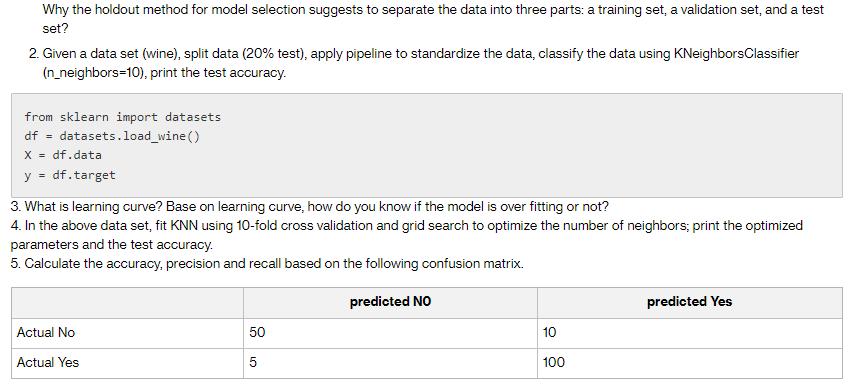
Why the holdout method for model selection suggests to separate the data into three parts: a training set, a validation set, and a test set? 2. Given a data set (wine), split data (20% test), apply pipeline to standardize the data, classify the data using KNeighbors Classifier (n_neighbors=10), print the test accuracy. from sklearn import datasets df = datasets. load_wine () X = df.data y = df.target 3. What is learning curve? Base on learning curve, how do you know if the model is over fitting or not? 4. In the above data set, fit KNN using 10-fold cross validation and grid search to optimize the number of neighbors; print the optimized parameters and the test accuracy. 5. Calculate the accuracy, precision and recall based on the following confusion matrix. Actual No Actual Yes 50 predicted NO 10 100 predicted Yes
Step by Step Solution
There are 3 Steps involved in it
Step: 1
1 The holdout method for model selection suggests to separate the data into three parts a training s...
Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
Essentials Of Business Analytics
Authors: Jeffrey Camm, James Cochran, Michael Fry, Jeffrey Ohlmann, David Anderson, Dennis Sweeney, Thomas Williams
1st Edition
128518727X, 978-1337360135, 978-1285187273