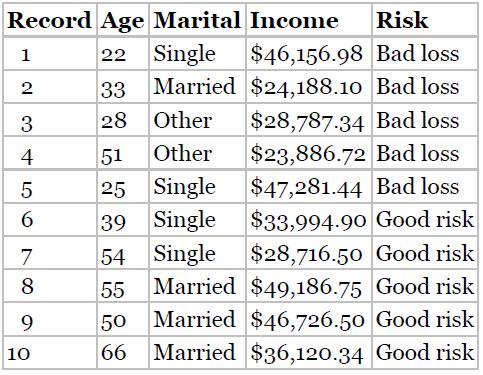
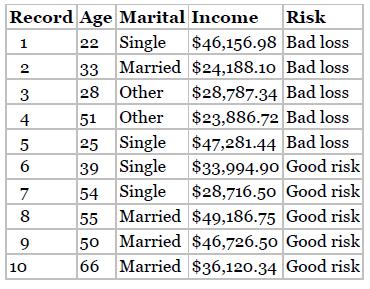
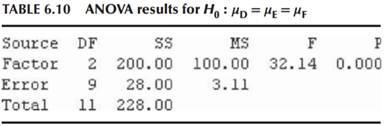
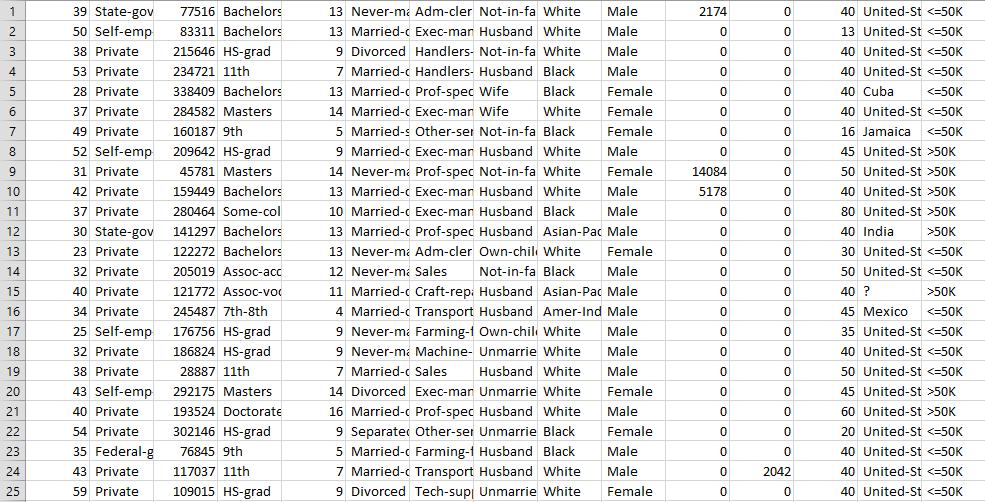
Discovering Knowledge In Data An Introduction To Data Mining 2nd Edition Daniel T. Larose, Chantal D. Larose - Solutions
Discover comprehensive support for "Discovering Knowledge In Data: An Introduction To Data Mining, 2nd Edition" by Daniel T. Larose and Chantal D. Larose with our extensive resources. Access the answers key and solutions pdf featuring detailed step-by-step answers to all the questions and solved problems. Our solution manual and instructor manual provide invaluable insights into the textbook, ensuring a thorough understanding of each chapter. Enhance your learning with the test bank and chapter solutions, available for free download. Whether you're looking for online answers or a detailed guide, our resources are designed to meet your needs efficiently.