

Question: General-purpose processes are optimized for general-purpose computing. That is, they are optimized for behavior that is generally found across a large number of applications. However,
General-purpose processes are optimized for general-purpose computing. That is, they are optimized for behavior that is generally found across a large number of applications. However, once the domain is restricted somewhat, the behavior that is found across a large number of the target applications may be different from general-purpose applications. One such application is deep learning or neural networks. Deep learning can be applied to many different applications, but the fundamental building block of inference—using the learned information to make decisions—is the same across them all. Inference operations are largely parallel, so they are currently performed on graphics processing units, which are specialized more toward this type of computation, and not to inference in particular. In a quest for more performance per watt, Google has created a custom chip using tensor processing units to accelerate inference operations in deep learning.1 This approach can be used for speech recognition and image recognition, for example. This problem explores the trade-offs between this process,
a general-purpose processor (Haswell E5-2699 v3) and a GPU (NVIDIA K80), in terms of performance and cooling. If heat is not removed from the computer efficiently, the fans will blow hot air back onto the computer, not cold air.
Note: The differences are more than processor—on-chip memory and DRAMalso come into play. Therefore statistics are at a system level, not a chip level.
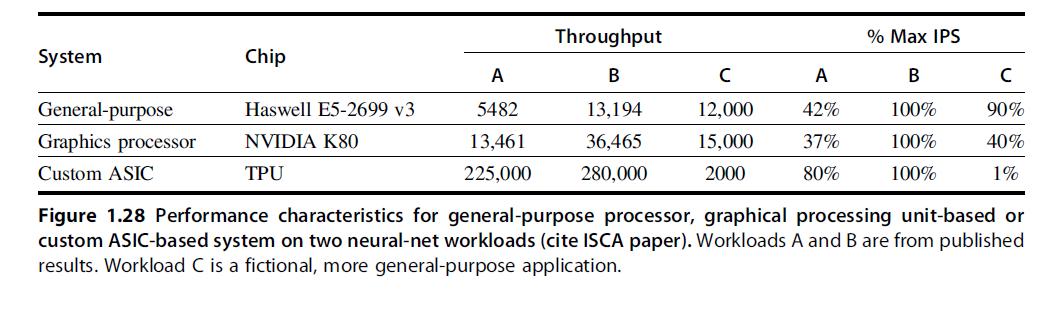
a. If Google’s data center spends 70% of its time on workload A and 30% of its time on workload B when running GPUs, what is the speedup of the TPU system over the GPU system?
b. If Google’s data center spends 70% of its time on workload A and 30% of its time on workload B when running GPUs, what percentage of Max IPS does it achieve for each of the three systems?
c. Building on (b), assuming that the power scales linearly from idle to busy power as IPS grows from 0% to 100%, what is the performance per watt of the TPU system over the GPU system?
d. If another data center spends 40% of its time on workload A, 10%
of its time on workload B, and 50% of its time on workload C, what are the speedups of the GPU and TPU systems over the general-purpose system?
e. A cooling door for a rack costs $4000 and dissipates 14 kW (into the room; additional cost is required to get it out of the room). How many Haswell-, NVIDIA-, or Tensor-based servers can you cool with one cooling door, assuming TDP in Figures 1.27 and 1.28?
f. Typical server farms can dissipate a maximum of 200 Wper square foot. Given that a server rack requires 11 square feet (including front and back clearance), how many servers from part
(e) can be placed on a single rack, and how many cooling doors are required?
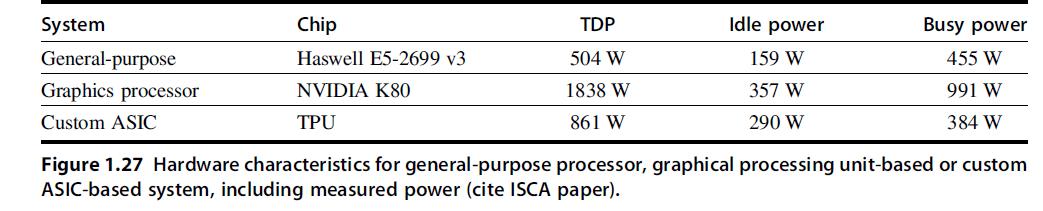
System General-purpose Graphics processor Custom ASIC Chip Haswell E5-2699 v3 NVIDIA K80 TPU TDP 504 W 1838 W 861 W Idle power 159 W 357 W 290 W Busy power 455 W 991 W 384 W Figure 1.27 Hardware characteristics for general-purpose processor, graphical processing unit-based or custom ASIC-based system, including measured power (cite ISCA paper).
Step by Step Solution
3.42 Rating (155 Votes )
There are 3 Steps involved in it
a Workload A speedup 22500013461167 Workload B speedup 2... View full answer

Get step-by-step solutions from verified subject matter experts