

Question: We saw that our measurements of the prefix-sum function psum1 (Figure 5.1) yield a CPE of 9.00 on a machine where the basic operation to
We saw that our measurements of the prefix-sum function psum1 (Figure 5.1) yield a CPE of 9.00 on a machine where the basic operation to be performed, floating point addition, has a latency of just 3 clock cycles. Let us try to understand why our function performs so poorly.
The following is the assembly code for the inner loop of the function:
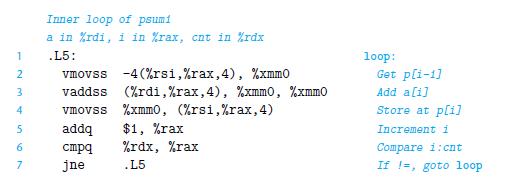
Perform an analysis similar to those shown for combine3 (Figure 5.14) and for write_read (Figure 5.36) to diagram the data dependencies created by this loop, and hence the critical path that forms as the computation proceeds. Explain why the CPE is so high.
Figure 5.1

Figure 5.14
![%xmmo mul %xmmo load %rax %rdx cmp jne (a) add %rdx data [/] %xmmo load mul %xmmo (b) %rdx add %rdx](https://dsd5zvtm8ll6.cloudfront.net/images/question_images/1698/2/2/0/2696538c8ed04f871698220267917.jpg)
Figure 5.36
1 2 3 4 5 6 7 Inner loop of psumi a in %rdi, i in %rax, cnt in %rdx .L5: vmovss -4(%rsi,%rax, 4), %xmmo vaddss (%rdi,%rax, 4), %xmm0, %xmmo vmovss %xmm0, (%rsi,%rax, 4) $1, %rax addq cmpq %rdx, %rax jne .L5 loop: Get p[i-1] Add a[i] Store at p[i] Increment i Compare i:cnt If , goto loop
Step by Step Solution
3.37 Rating (147 Votes )
There are 3 Steps involved in it
We can see that this function has a writeread dependency ... View full answer

Get step-by-step solutions from verified subject matter experts