

This exercise shows that in a simple regression model, adding a dummy variable for missing data on
Question:
This exercise shows that in a simple regression model, adding a dummy variable for missing data on the explanatory variable produces a consistent estimator of the slope coefficient if the “missingness” is unrelated to both the unobservable and observable factors affecting y. Let m be a variable such that m = 1 if we do not observe x and m 5 0 if we observe x. We assume that y is always observed. The population model is
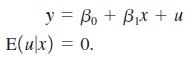
(i) Provide an interpretation of the stronger assumption
E(u|x,m) = 0.
In particular, what kind of missing data schemes would cause this assumption to fail?
(ii) Show that we can always write
(iii) Let (xi, yi, mi): i = 1, . . . , n be random draws from the population, where xi is missing when mi = 1. Explain the nature of the variable zi = (1 – mi)xi. In particular, what does this variable equal when xi is missing?
(iv) Let r = P(m = 1) and assume that m and x are independent. Show that
Cov[(1 – m)x,mx] = – ρ(1 – ρ)µx,
where µx = E(x). What does this imply about estimating β1 from the regression yi on zi, i = 1, . . . , n?
(v) If m and x are independent, it can be shown that
mx = δ0 + δ1m + v,
where v is uncorrelated with m and z = (1 – m)x. Explain why this makes m a suitable proxy variable for mx. What does this mean about the coefficient on zi in the regression
yi on zi, mi, i = 1, . . . , n?
(vi) Suppose for a population of children, y is a standardized test score, obtained from school records, and x is family income, which is reported voluntarily by families (and so some families do not report their income). Is it realistic to assume m and x are independent? Explain.
Step by Step Answer:
i The stronger assumption Euxm 0 means that the error term u in the population model y Eux 0 Bo Bx u ...View the full answer



Introductory Econometrics A Modern Approach
ISBN: 9781337558860
7th Edition
Authors: Jeffrey Wooldridge
