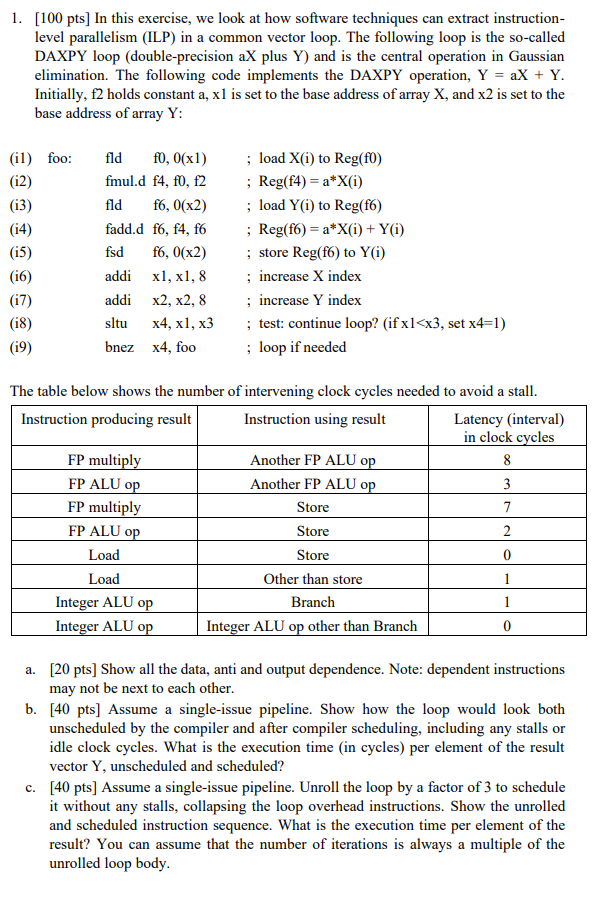
1. [100 pts] In this exercise, we look at how software techniques can extract instructionlevel parallelism (ILP) in a common vector loop. The following loop is the so-called DAXPY loop (double-precision aX plus Y) and is the central operation in Gaussian elimination. The following code implements the DAXPY operation, Y=aX+Y. Initially, f2 holds constant a,x1 is set to the base address of array X, and x2 is set to the base address of array Y: The table below shows the number of intervening clock cycles needed to avoid a stall. a. [20 pts] Show all the data, anti and output dependence. Note: dependent instructions may not be next to each other. b. [40 pts] Assume a single-issue pipeline. Show how the loop would look both unscheduled by the compiler and after compiler scheduling, including any stalls or idle clock cycles. What is the execution time (in cycles) per element of the result vector Y, unscheduled and scheduled? c. [40 pts] Assume a single-issue pipeline. Unroll the loop by a factor of 3 to schedule it without any stalls, collapsing the loop overhead instructions. Show the unrolled and scheduled instruction sequence. What is the execution time per element of the result? You can assume that the number of iterations is always a multiple of the unrolled loop body. 1. [100 pts] In this exercise, we look at how software techniques can extract instructionlevel parallelism (ILP) in a common vector loop. The following loop is the so-called DAXPY loop (double-precision aX plus Y) and is the central operation in Gaussian elimination. The following code implements the DAXPY operation, Y=aX+Y. Initially, f2 holds constant a,x1 is set to the base address of array X, and x2 is set to the base address of array Y: The table below shows the number of intervening clock cycles needed to avoid a stall. a. [20 pts] Show all the data, anti and output dependence. Note: dependent instructions may not be next to each other. b. [40 pts] Assume a single-issue pipeline. Show how the loop would look both unscheduled by the compiler and after compiler scheduling, including any stalls or idle clock cycles. What is the execution time (in cycles) per element of the result vector Y, unscheduled and scheduled? c. [40 pts] Assume a single-issue pipeline. Unroll the loop by a factor of 3 to schedule it without any stalls, collapsing the loop overhead instructions. Show the unrolled and scheduled instruction sequence. What is the execution time per element of the result? You can assume that the number of iterations is always a multiple of the unrolled loop body




