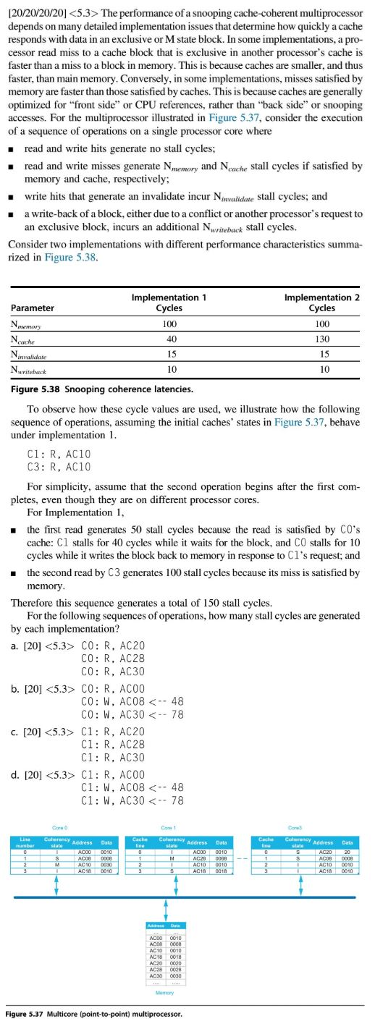
[20/20/20/20] The performance of a snooping cache-coherent multiprocessor depends on many detailed implementation issues that determine how quickly a cache responds with data in an exclusive or Mstate block. In some implementations, a pro- cessor read miss to a cache block that is exclusive in another processor's cache is faster than a miss to a block in memory. This is because caches are smaller, and thus faster, than main memory. Conversely, in some implementations, misses satisfied by memory are faster than those satisfied by caches. This is because caches are generally optimized for front side" or CPU references, rather than "back side" or snooping accesses. For the multiprocessor illustrated in Figure 5.37, consider the execution of a sequence of operations on a single processor core where . read and write hits generate no stall cycles; read and write misses generate Newry and Nache stall cycles if satisfied by memory and cache, respectively; .write hits that generate an invalidate incur Navaldate stall cycles, and a write-back of a block, either due to a conflict or another processor's request to an exclusive block, incurs an additional NWritebuk stall cycles. Consider two implementations with different performance characteristics summa- rized in Figure 5.38. Implementation 1 Implementation 2 Cycles Parameter Cycles Nabase Net Figure 5.38 Snooping coherence latencies. To observe how these cycle values are used, we illustrate how the following sequence of operations, assuming the initial caches' states in Figure 5.37, behave under implementation 1. C1: R. AC10 C3: R. AC10 For simplicity, assume that the second operation begins after the first com- pletes, even though they are on different processor cores. For Implementation 1, the first read generates 50 stall cycles because the read is satisfied by CO's cache: C1 stalls for 40 cycles while it waits for the block, and CO stalls for 10 cycles while it writes the block back to memory in response to C1's request; and - the second read by C3 generates 100 stall cycles because its miss is satisfied by memory. Therefore this sequence generates a total of 150 stall cycles. For the following sequences of operations, how many stall cycles are generated by each implementation? a. [20] CO: R. AC20 CO: R. AC28 CO: R.AC30 b. [20] CO: R. ACCO CO: W. AC08 C1:R, AC20 Cl: R. AC28 C1: R.AC30 d. [20] C1: R. AC00 C1: W, AC0B The performance of a snooping cache-coherent multiprocessor depends on many detailed implementation issues that determine how quickly a cache responds with data in an exclusive or Mstate block. In some implementations, a pro- cessor read miss to a cache block that is exclusive in another processor's cache is faster than a miss to a block in memory. This is because caches are smaller, and thus faster, than main memory. Conversely, in some implementations, misses satisfied by memory are faster than those satisfied by caches. This is because caches are generally optimized for front side" or CPU references, rather than "back side" or snooping accesses. For the multiprocessor illustrated in Figure 5.37, consider the execution of a sequence of operations on a single processor core where . read and write hits generate no stall cycles; read and write misses generate Newry and Nache stall cycles if satisfied by memory and cache, respectively; .write hits that generate an invalidate incur Navaldate stall cycles, and a write-back of a block, either due to a conflict or another processor's request to an exclusive block, incurs an additional NWritebuk stall cycles. Consider two implementations with different performance characteristics summa- rized in Figure 5.38. Implementation 1 Implementation 2 Cycles Parameter Cycles Nabase Net Figure 5.38 Snooping coherence latencies. To observe how these cycle values are used, we illustrate how the following sequence of operations, assuming the initial caches' states in Figure 5.37, behave under implementation 1. C1: R. AC10 C3: R. AC10 For simplicity, assume that the second operation begins after the first com- pletes, even though they are on different processor cores. For Implementation 1, the first read generates 50 stall cycles because the read is satisfied by CO's cache: C1 stalls for 40 cycles while it waits for the block, and CO stalls for 10 cycles while it writes the block back to memory in response to C1's request; and - the second read by C3 generates 100 stall cycles because its miss is satisfied by memory. Therefore this sequence generates a total of 150 stall cycles. For the following sequences of operations, how many stall cycles are generated by each implementation? a. [20] CO: R. AC20 CO: R. AC28 CO: R.AC30 b. [20] CO: R. ACCO CO: W. AC08 C1:R, AC20 Cl: R. AC28 C1: R.AC30 d. [20] C1: R. AC00 C1: W, AC0B




