

Answered step by step
Verified Expert Solution
Question
1 Approved Answer
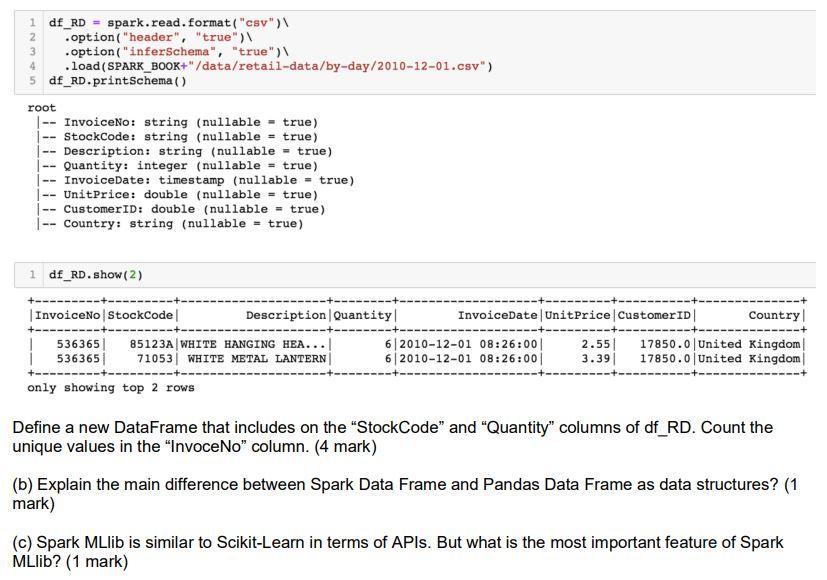
(6) PySpark and Spark MLlib (6 marks) (a) Assume the following Data Frame is defined in the PySpark shell. Write down your codes in PySpark

Step by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
Database And Expert Systems Applications 24th International Conference Dexa 2013 Prague Czech Republic August 2013 Proceedings Part 1 Lncs 8055
Authors: Hendrik Decker ,Lenka Lhotska ,Sebastian Link ,Josef Basl ,A Min Tjoa
2013 Edition
3642402844, 978-3642402845