

Question
A clustering technique called Unique Neighborhood Set Parameter Independent Density-Based Clustering with Outlier Detection (PIDC-O) is applied on a dataset having 450 records and two
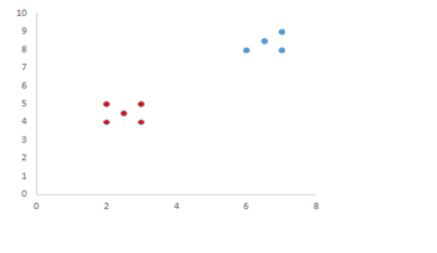
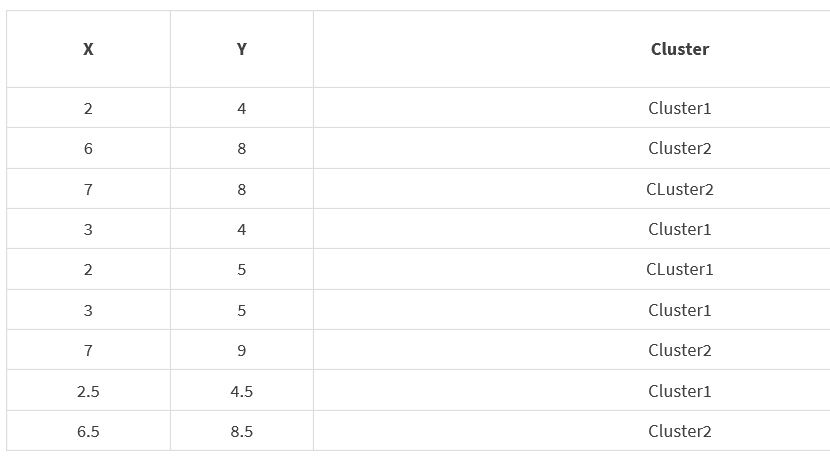 A clustering technique called "Unique Neighborhood Set Parameter Independent Density-Based Clustering with Outlier Detection" (PIDC-O) is applied on a dataset having 450 records and two attributes (X, Y). The number of clusters produced by PIDC-O from the dataset is four namely Cluster1, Cluster2, Cluster3 and Cluster4. A text file (cluster.txt) that contains the clusters will be uploaded into the subject interact site soon. For better understanding, the structure of the text file is discussed using the table below. X Y Cluster 2 4 Cluster1 6 8 Cluster2 7 8 CLuster2 3 4 Cluster1 2 5 CLuster1 3 5 Cluster1 7 9 Cluster2 2.5 4.5 Cluster1 6.5 8.5 Cluster2 The number of records in the above table is nine, the number of attributes is two (X,Y) and the number of clusters is two (Cluster1, Cluster2) whereas the cluster.txt in the subject interact site will have 450 records, two attributes (X,Y) and four clusters (Cluster1, Cluster2, Cluster3, Cluster4). The sample output on the above table is shown below. Write a Java Graphical User Interface (GUI) program that will read the cluster.txt file and will display the records of the clusters in cluster.txt file in GUI. The records in a particular will be displayed using a single colour. Add legend for each cluster in the GUI, so that the clusters can be easily identified.
A clustering technique called "Unique Neighborhood Set Parameter Independent Density-Based Clustering with Outlier Detection" (PIDC-O) is applied on a dataset having 450 records and two attributes (X, Y). The number of clusters produced by PIDC-O from the dataset is four namely Cluster1, Cluster2, Cluster3 and Cluster4. A text file (cluster.txt) that contains the clusters will be uploaded into the subject interact site soon. For better understanding, the structure of the text file is discussed using the table below. X Y Cluster 2 4 Cluster1 6 8 Cluster2 7 8 CLuster2 3 4 Cluster1 2 5 CLuster1 3 5 Cluster1 7 9 Cluster2 2.5 4.5 Cluster1 6.5 8.5 Cluster2 The number of records in the above table is nine, the number of attributes is two (X,Y) and the number of clusters is two (Cluster1, Cluster2) whereas the cluster.txt in the subject interact site will have 450 records, two attributes (X,Y) and four clusters (Cluster1, Cluster2, Cluster3, Cluster4). The sample output on the above table is shown below. Write a Java Graphical User Interface (GUI) program that will read the cluster.txt file and will display the records of the clusters in cluster.txt file in GUI. The records in a particular will be displayed using a single colour. Add legend for each cluster in the GUI, so that the clusters can be easily identified.
Step by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
Temporal Databases Research And Practice Lncs 1399
Authors: Opher Etzion ,Sushil Jajodia ,Suryanarayana Sripada
1st Edition
3540645195, 978-3540645191