

Question
(a) The K-means algorithm with Euclidean distances is a very popular and widely used method for data clustering. What is the basic assumption on the
(a) The K-means algorithm with Euclidean distances is a very popular and widely used method for data clustering. What is the basic assumption on the distribution of the data in this K-means clustering?
(b) Answer the following questions in the context of the K-means algorithm.
What are the inputs? Which parameters are usually specified by the user?
What objective function does the K-means algorithm minimise?
(c) You are given a one-dimensional dataset, D = {0, 1, 1, 2, 3, 4, 4, 4, 5}. Compute the kernel density estimate at x = 2 and x = 4 with the bandwidth of 2 using the following triangle kernel:
K(u) = (1 - lu|)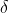 (|u| =
(|u| =
where 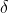 is the function
is the function
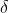 (|u| =10|u|=otherwise
(|u| =10|u|=otherwise
Justify your answers.
(d) Why do we want to use "weak" learners such as decision stumps when using the method of boosting?
Step by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
Mastering Apache Cassandra 3 X An Expert Guide To Improving Database Scalability And Availability Without Compromising Performance
Authors: Aaron Ploetz ,Tejaswi Malepati ,Nishant Neeraj
3rd Edition
1789131499, 978-1789131499