

Question
and here are hash-table-v1.c and hash-table-v2.c codes... please read the instruction thoroughly and edit the files... - hash-table-v1.c #include hash-table-base.h #include #include #include #include struct

and here are hash-table-v1.c and hash-table-v2.c codes...
please read the instruction thoroughly and edit the files...
- hash-table-v1.c
#include "hash-table-base.h"
#include
struct list_entry { const char *key; uint32_t value; SLIST_ENTRY(list_entry) pointers; };
SLIST_HEAD(list_head, list_entry);
struct hash_table_entry { struct list_head list_head; };
struct hash_table_v1 { struct hash_table_entry entries[HASH_TABLE_CAPACITY]; };
struct hash_table_v1 *hash_table_v1_create() { struct hash_table_v1 *hash_table = calloc(1, sizeof(struct hash_table_v1)); assert(hash_table != NULL); for (size_t i = 0; i entries[i]; SLIST_INIT(&entry->list_head); } return hash_table; }
static struct hash_table_entry *get_hash_table_entry(struct hash_table_v1 *hash_table, const char *key) { assert(key != NULL); uint32_t index = bernstein_hash(key) % HASH_TABLE_CAPACITY; struct hash_table_entry *entry = &hash_table->entries[index]; return entry; }
static struct list_entry *get_list_entry(struct hash_table_v1 *hash_table, const char *key, struct list_head *list_head) { assert(key != NULL);
struct list_entry *entry = NULL; SLIST_FOREACH(entry, list_head, pointers) { if (strcmp(entry->key, key) == 0) { return entry; } } return NULL; }
bool hash_table_v1_contains(struct hash_table_v1 *hash_table, const char *key) { struct hash_table_entry *hash_table_entry = get_hash_table_entry(hash_table, key); struct list_head *list_head = &hash_table_entry->list_head; struct list_entry *list_entry = get_list_entry(hash_table, key, list_head); return list_entry != NULL; }
void hash_table_v1_add_entry(struct hash_table_v1 *hash_table, const char *key, uint32_t value) { struct hash_table_entry *hash_table_entry = get_hash_table_entry(hash_table, key); struct list_head *list_head = &hash_table_entry->list_head; struct list_entry *list_entry = get_list_entry(hash_table, key, list_head);
/* Update the value if it already exists */ if (list_entry != NULL) { list_entry->value = value; return; }
list_entry = calloc(1, sizeof(struct list_entry)); list_entry->key = key; list_entry->value = value; SLIST_INSERT_HEAD(list_head, list_entry, pointers); }
uint32_t hash_table_v1_get_value(struct hash_table_v1 *hash_table, const char *key) { struct hash_table_entry *hash_table_entry = get_hash_table_entry(hash_table, key); struct list_head *list_head = &hash_table_entry->list_head; struct list_entry *list_entry = get_list_entry(hash_table, key, list_head); assert(list_entry != NULL); return list_entry->value; }
void hash_table_v1_destroy(struct hash_table_v1 *hash_table) { for (size_t i = 0; i entries[i]; struct list_head *list_head = &entry->list_head; struct list_entry *list_entry = NULL; while (!SLIST_EMPTY(list_head)) { list_entry = SLIST_FIRST(list_head); SLIST_REMOVE_HEAD(list_head, pointers); free(list_entry); } } free(hash_table); }
- hash-table-v2.c
#include "hash-table-base.h"
#include
struct list_entry { const char *key; uint32_t value; SLIST_ENTRY(list_entry) pointers; };
SLIST_HEAD(list_head, list_entry);
struct hash_table_entry { struct list_head list_head; };
struct hash_table_v2 { struct hash_table_entry entries[HASH_TABLE_CAPACITY]; };
struct hash_table_v2 *hash_table_v2_create() { struct hash_table_v2 *hash_table = calloc(1, sizeof(struct hash_table_v2)); assert(hash_table != NULL); for (size_t i = 0; i entries[i]; SLIST_INIT(&entry->list_head); } return hash_table; }
static struct hash_table_entry *get_hash_table_entry(struct hash_table_v2 *hash_table, const char *key) { assert(key != NULL); uint32_t index = bernstein_hash(key) % HASH_TABLE_CAPACITY; struct hash_table_entry *entry = &hash_table->entries[index]; return entry; }
static struct list_entry *get_list_entry(struct hash_table_v2 *hash_table, const char *key, struct list_head *list_head) { assert(key != NULL);
struct list_entry *entry = NULL; SLIST_FOREACH(entry, list_head, pointers) { if (strcmp(entry->key, key) == 0) { return entry; } } return NULL; }
bool hash_table_v2_contains(struct hash_table_v2 *hash_table, const char *key) { struct hash_table_entry *hash_table_entry = get_hash_table_entry(hash_table, key); struct list_head *list_head = &hash_table_entry->list_head; struct list_entry *list_entry = get_list_entry(hash_table, key, list_head); return list_entry != NULL; }
void hash_table_v2_add_entry(struct hash_table_v2 *hash_table, const char *key, uint32_t value) { struct hash_table_entry *hash_table_entry = get_hash_table_entry(hash_table, key); struct list_head *list_head = &hash_table_entry->list_head; struct list_entry *list_entry = get_list_entry(hash_table, key, list_head);
/* Update the value if it already exists */ if (list_entry != NULL) { list_entry->value = value; return; }
list_entry = calloc(1, sizeof(struct list_entry)); list_entry->key = key; list_entry->value = value; SLIST_INSERT_HEAD(list_head, list_entry, pointers); }
uint32_t hash_table_v2_get_value(struct hash_table_v2 *hash_table, const char *key) { struct hash_table_entry *hash_table_entry = get_hash_table_entry(hash_table, key); struct list_head *list_head = &hash_table_entry->list_head; struct list_entry *list_entry = get_list_entry(hash_table, key, list_head); assert(list_entry != NULL); return list_entry->value; }
void hash_table_v2_destroy(struct hash_table_v2 *hash_table) { for (size_t i = 0; i entries[i]; struct list_head *list_head = &entry->list_head; struct list_entry *list_entry = NULL; while (!SLIST_EMPTY(list_head)) { list_entry = SLIST_FIRST(list_head); SLIST_REMOVE_HEAD(list_head, pointers); free(list_entry); } } free(hash_table); }
PLEASE read the instructions thoroughly so that we both would not have to redo this again...
Solutions that would not work is no use at all.
Thank you, by all means, in advance
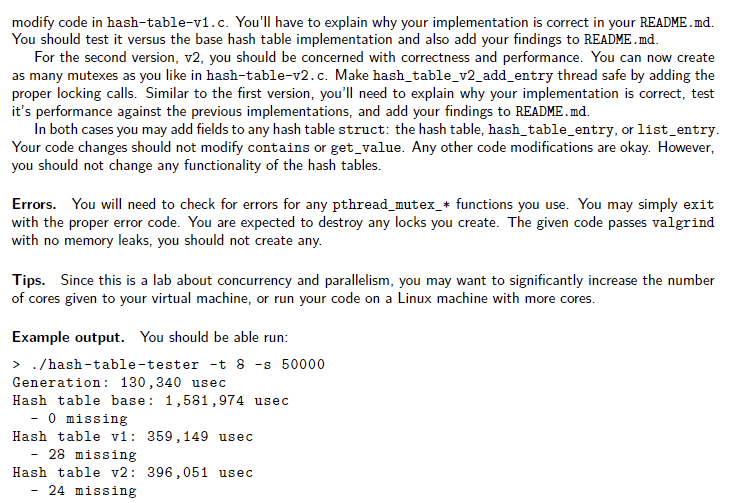
In this lab you'll be making a hash table implementation safe to use concurrently. You'll be given a serial hash table implementation, and two additional hash table implementations to modify. You're expected to implement two locking strategies and compare them with the base implementation. The hash table implementation uses separate chaining to resolve collisions. Each cell of the hash table is a singly linked list of key/value pairs. You are not to change the algorithm, only add mutex locks. Note that this is basically the implementation of Java concurrent hash tables, except they have an optimization that doesn't create a linked list if there's only one entry at a hash location. Additional APls. Similar to Lab 2, the base implementation uses a linked list, but instead of TAILQ, it uses SLIST. You should note that the SLIST_ functions modify the pointers field of struct list_entry. For your implementation you should only use pthread_mutex_t, and the associated init/lock/unlock/destroy functions. You will have to add the proper \#include yourself. Starting the lab. - Download the lab3.tar file from BruinLearn. - Move the downloaded tarball into your virtual machine. - Untar the tarball by running: tar -xvf lab3.tar command. - Go into the untarred directory(lab3 directory) by running: cd lab3, then you can begin the lab. You should be able to run make in the lab3 directory to create a hash-table-tester executable, and then make clean to remove all binary files. The executable takes two command link arguments: -t changes the number of threads to use (default 4), and -s changes the number of hash table entries to add per thread (default 25,000 ). For example you can run: ./hash-table-tester -t 8 -s 50000. Files to modify. You should only be modifying hash-table-v1.c, hash-table-v2.c, and README.md in the lab3 directory. Tester Code. The tester code generates consistent entries in serial such that every run with the same t and s flags will receive the same data. All hash tables have room for 4096 entries, so for any sufficiently large number of additions, there will be collisions. The tester code runs the base hash table in serial for timing comparsions, and the other two versions with the specified number of threads. For each version it reports the number of s per implementation. It then runs a sanity check, in serial, that each hash table contains all the elements it put in. By default your hash tables should run - t times faster (assuming you have that number of cores). However, you should have missing entries (we made it fail faster!). Correct implementations should at least have no entries missing in the hash table. However, just because you have no entries missing, you still may have issues with your implementation (concurrent programming is significantly harder). Your task. Using only pthread_mutex_*, you should create two thread safe versions of the hash table "add entry" functions. You only have to add locking calls to hash_table_v1_add_entry and hash_table_v2_add_entry, all other functions are called serially, mainly for sanity checks. By default there is a data race finding and adding entries to the list. You'll need to fill in your README. md completely. Most sections are what you expect from previous labs, however there is more to add for this lab (explained below). For the first version, v1, you should only be concerned with correctness. Create a single mutex, only for v1, and make hash_table_v1_add_entry thread safe by adding the proper locking calls. Remember, you should only modify code in hash-table-v1. c. You'll have to explain why your implementation is correct in your README. md. You should test it versus the base hash table implementation and also add your findings to README.md. For the second version, v2, you should be concerned with correctness and performance. You can now create as many mutexes as you like in hash-table-v2.c. Make hash_table_v2_add_entry thread safe by adding the proper locking calls. Similar to the first version, you'll need to explain why your implementation is correct, test it's performance against the previous implementations, and add your findings to README.md. In both cases you may add fields to any hash table struct: the hash table, hash_table_entry, or list_entry. Your code changes should not modify contains or get_value. Any other code modifications are okay. However, you should not change any functionality of the hash tes. Errors. You will need to check for errors for any pthread_mutex_* functions you use. You may simply exit with the proper error code. You are expected to destroy any locks you create. The given code passes valgrind with no memory leaks, you should not create any. Tips. Since this is a lab about concurrency and parallelism, you may want to significantly increase the number of cores given to your virtual machine, or run your code on a Linux machine with more cores. Example output. You should be able run: >./hash-table-tester -t 8 -s 50000 Generation: 130,340 usec Hash table base: 1,581, 974 usec - 0 missing Hash table v1: 359,149 usec - 28 missing Hash table v2: 396,051 usec - 24 missingStep by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
Advances In Databases And Information Systems 25th European Conference Adbis 2021 Tartu Estonia August 24 26 2021 Proceedings Lncs 12843
Authors: Ladjel Bellatreche ,Marlon Dumas ,Panagiotis Karras ,Raimundas Matulevicius
1st Edition
3030824713, 978-3030824716