

Question
Ann needs to build a text categorization system for spam detection. She has a set of e-mails for which she has the correct category (i.e.,
Ann needs to build a text categorization system for spam detection. She has a set of e-mails for which she has the correct category (i.e., spam or good e-mail). With those text samples, she can analyze the distributions of the terms in both categories.
To summarize the information, Ann generates a set of contingency table, one for each term. Her training set contains of n=600 e-mails in which the word free appears in total in 110 e-mails. More precisely, the term free appears in 100 spam e-mails and 10 times in good e-mails. We can summarize the information in the following table.
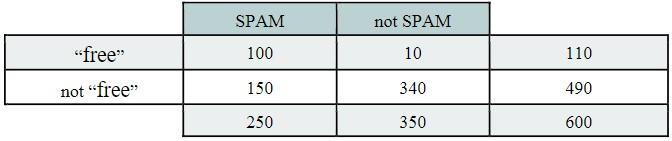
To evaluate the discriminative power of each term before building a nave Bayes model, Ann suggests computing the pointwise mutual information (PMI). For Ann, this term selection strategy seems a good one because she saw this description in many books, and scientific articles. So, she will use this approach to select the 100 most appropriate terms. a) How can she estimate the following four probabilities? P[free], P[SPAM], P[free appearing in category SPAM], and P[free | SPAM] Give clearly the values used to estimation these probabilities. b) She has another term: system with the following contingency table. When comparing the PMI values for the terms free and system for the category SPAM, do you think that one is (or both are) good discriminator for this category? Justify your answer.
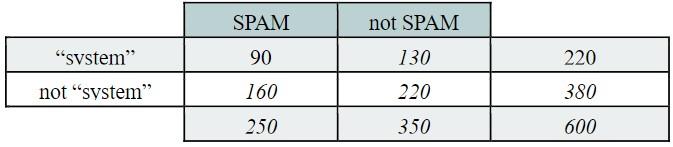
c) For John, the pointwise mutual information measure is stupid because the value in the numerator (or P[tk,ci]) is equal to the value in the denominator (or P[tk] P[ci]). Every educated person knows that the estimation of P[tk,ci] = P[tk] P[ci].Is Johns argument always correct? Always incorrect? Sometimes correct, sometimes incorrect? Justify your answer. d) For this application, which preprocessing do you propose to apply to the raw text before obtaining the contingency table for each term? Justify your choice.
\begin{tabular}{|c|c|c|c|} \cline { 2 - 4 } \multicolumn{1}{c|}{} & SPAM & not SPAM & \multicolumn{1}{c|}{} \\ \hline "free" & 100 & 10 & 110 \\ \hline not "free" & 150 & 340 & 490 \\ \hline \multicolumn{1}{c|}{} & 250 & 350 & 600 \\ \hline \end{tabular} \begin{tabular}{|c|c|c|c|} \cline { 2 - 3 } \multicolumn{1}{c|}{} & SPAM & not SPAM & \multicolumn{1}{|c}{} \\ \hline "svstem" & 90 & 130 & 220 \\ \hline not "svstem" & 160 & 220 & 380 \\ \hline \multirow{2}{*}{} & 250 & 350 & 600 \\ \cline { 2 - 3 } & & & \end{tabular}Step by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
Database Processing Fundamentals Design And Implementation
Authors: David M. Kroenke
5th Edition
B000CSIH5A, 978-0023668814