

Answered step by step
Verified Expert Solution
Question
1 Approved Answer
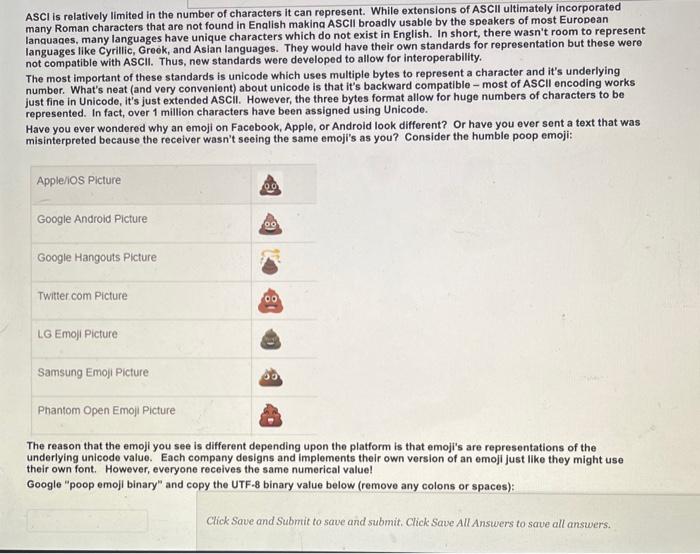
ASCI is relatively limited in the number of characters it can represent. While extensions of ASCII ultimately incorporated many Roman characters that are not found
Step by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
Relational Database And SQL
Authors: Lucy Scott
3rd Edition
1087899699, 978-1087899695