

Question
Assignment 13 Bloom Filter Define a minimum of two hash functions. You only need to use simple hash functions. In the lecture, I used two
Assignment 13 Bloom Filter
Define a minimum of two hash functions. You only need to use simple hash functions. In the lecture, I used two simple hash funtions from here (Links to an external site.)Links to an external site..
Complete the implementation of the BloomFilter Class.
Use the test driver (application) starter from the course github.
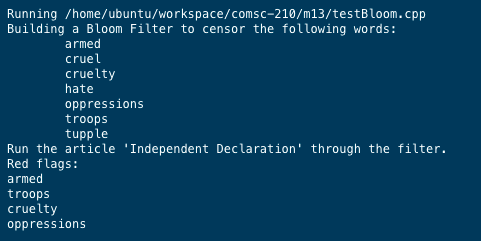
Here is a sample test run with no false positive detection using the set of 7 censored words with 2 hash functions and 2^10 (1024) bits filter on the starter tester:
Additional hash functions can be added to the bloom filter. You may find them at eternallyconfuzzled(Links to an external site.)Links to an external site. with good explanations or google it for more.
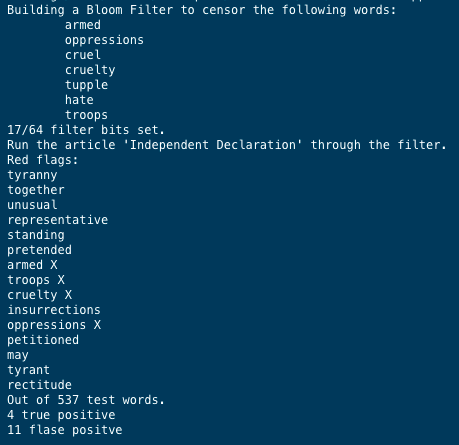
Here is another sample test run with false positive detections using the set of 7 censored words with 3 (added fvn from eternallyconfuzzled) hash functions and 2^6 (64) bits filter on the starter tester:
Run the program on 5 larger (more test words) but different documents,
Analyze the test run result on the Bloom Filter Calcualtor (Links to an external site.)Links to an external site. or this Calculator (Links to an external site.)Links to an external site. to validate this program confirms the false positive probability curve!
Run the program and use the calcualtor:

in parallel to the DoI, apply the test to a smaller file of 20-30 words at the same time.
try different sets of censor words
try more (3-7) hash functions
Test cases
Run the same test case on both the Bloom Filter program and the Bloom Filter Calculator
To test the Bloom Filter on its False positive stats based on your test data set to compare between your finding from the test data sets (minimum of 3 sets) that you used on the program and the online Bloom Filter calculator. The Declaration of Independence was provided in the example.
Submit
Please generate probability Stats:
The stats on the false positive probability from your program running test cases using as many different n, m, k as possible.
The stats on the false positive probability from the online Bloom Filter calculator use the same test cases that you did above.
Please provide your explanation on the illustrated stats between the test run on your bloom filter vs the calculator output in your words.
testBloomfilter.cpp
#include
#include
#include
#include
#include
#include
#include
using namespace std;
using HashFunction = function
class BloomFilter {
unsigned int numberOfCells;
bool* cell;
vector
public:
BloomFilter(unsigned int n, vector
: numberOfCells(n), hashFunctions(f) {
cell = new bool[n]();
}
~BloomFilter()
{ free(cell); cell = nullptr; }
void addX(string const& str)
{ for(auto x:hashFunctions)
cell[(x)(str) % numberOfCells] = true; }
bool searchX(string const& str) {
bool strInSet = true;
for (auto x:hashFunctions) {
if (cell[(x)(str) % numberOfCells] == false) {
strInSet = false; break; } }
return strInSet; }
};
unsigned int djb2(string str) {
unsigned int hash = 5381;
for(auto x:str)
hash = ((hash
return hash;
}
unsigned int sdbm(string str) {
unsigned int hash = 0;
for(auto x:str)
hash = x + (hash
return hash;
}
unsigned int fnv(string str) {
unsigned int hash = 2166136261;
for(auto x:str)
hash = (hash * 16777619) ^ x;
return hash;
}
int main() {
vector
hashFunctions.push_back(djb2);
hashFunctions.push_back(sdbm);
hashFunctions.push_back(fnv);
BloomFilter bf(128, hashFunctions);
cout
// insert words into the filter
unordered_set
"armed", "cruel", "cruelty", "hate", "oppressions", "troops", "tupple" });
for(auto x:censors) {
bf.addX(x); cout
cout
// input a sample text file
ifstream file;
file.open("DeclarationOfIndependence.txt");
if(file.fail())
{ cout
string line, word;
vector
cout
int true_pos=0, false_pos=0;
while(!file.eof()) {
while (getline(file, line)) {
stringstream ss(line);
while (ss >> word) {
word.erase(std::remove_if(word.begin(), word.end(),
[](char& c){return !isalnum(c);}), word.end());
if (word != "") {
for(auto &x:word) x = tolower(x);
if(bf.searchX(word)) { // all positive cases
if(censors.find(word) != censors.end())
{cout
else
{cout
}}}}}}
Running /home/ubuntu/workspace/comsc-210/m13/testBloom.cpp Building a Bloom Filter to censor the following words: armed cruel cruelty hate oppressions troops tupple Run the article 'Independent Declaration' through the filter. Red flags: armed troops cruelty oppressions Running /home/ubuntu/workspace/comsc-210/m13/testBloom.cpp Building a Bloom Filter to censor the following words: armed cruel cruelty hate oppressions troops tupple Run the article 'Independent Declaration' through the filter. Red flags: armed troops cruelty oppressionsStep by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
The Accidental Data Scientist
Authors: Amy Affelt
1st Edition
1573877077, 9781573877077