

Answered step by step
Verified Expert Solution
Question
1 Approved Answer
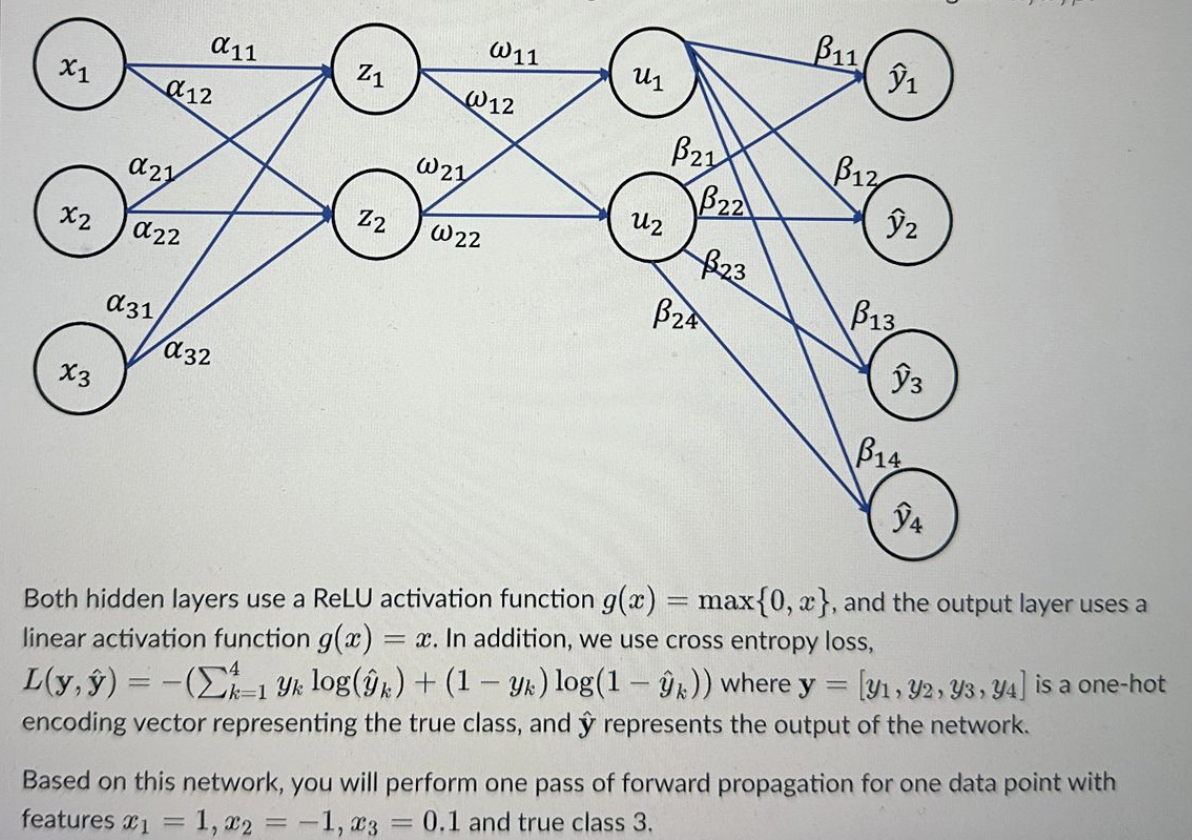
Both hidden layers use a ReLU activation function g ( x ) = max { 0 , x } , and the output layer uses
Both hidden layers use a ReLU activation function max and the output layer uses a
linear activation function In addition, we use cross entropy loss,
hathat where is a onehot
encoding vector representing the true class, and hat represents the output of the network.
Based on this network, you will perform one pass of forward propagation for one data point with
features and true class
Step by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
Database Theory And Application International Conference DTA 2009 Held As Part Of The Future Generation Information Technology Conference FGIT In Computer And Information Science 64
Authors: Dominik Slezak ,Yanchun Zhang
2009th Edition
3642105823, 978-3642105821