

Question
Business Scenario: Second Hand Car Sales A large Australian second hand car dealer Pre-Loved Cars (P-LC), with dealerships across all Australian states, asked you to
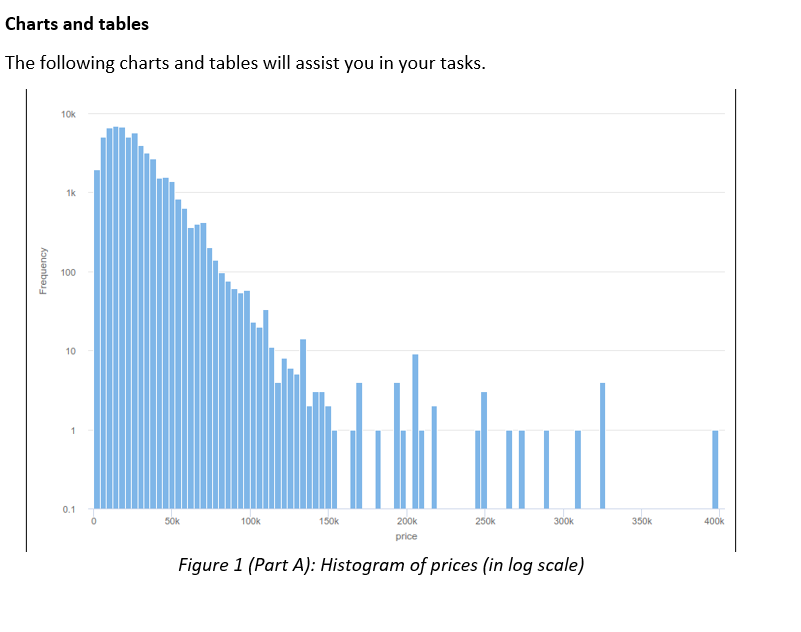
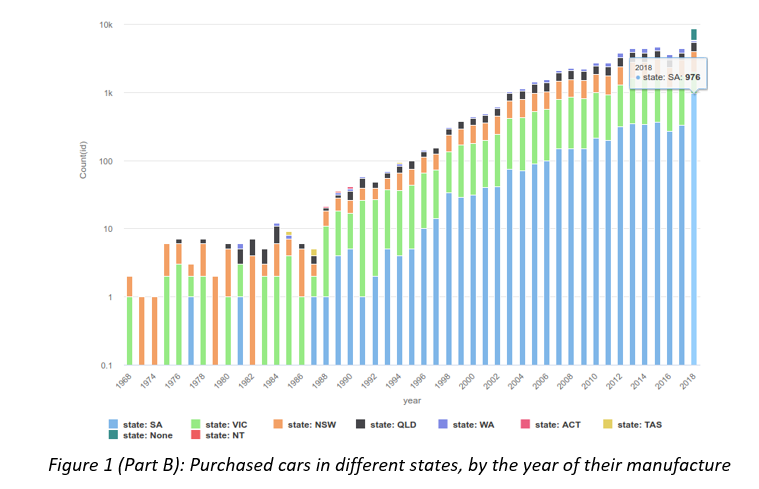
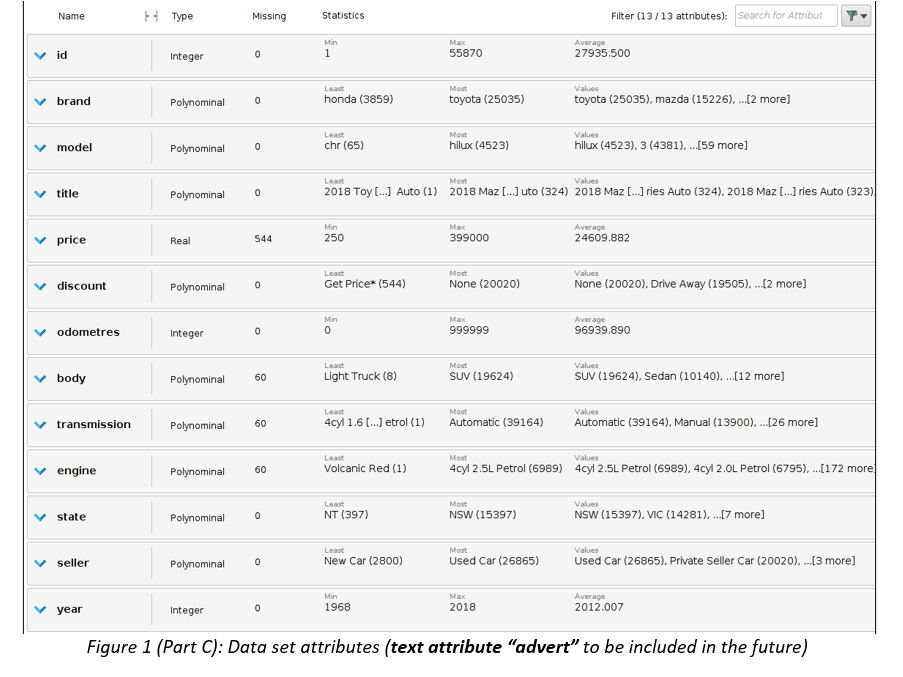
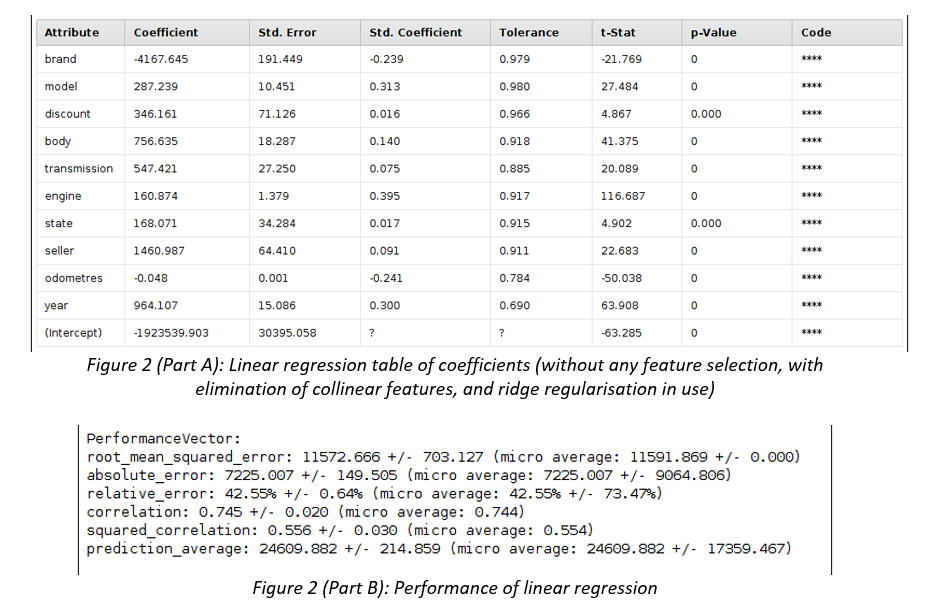
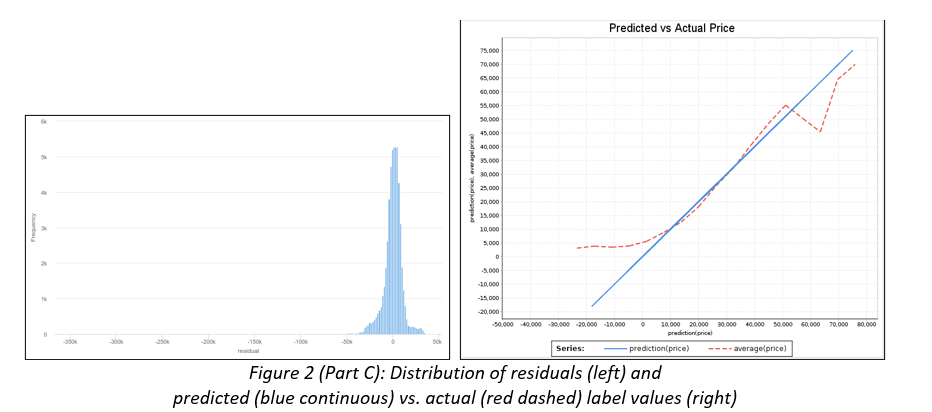
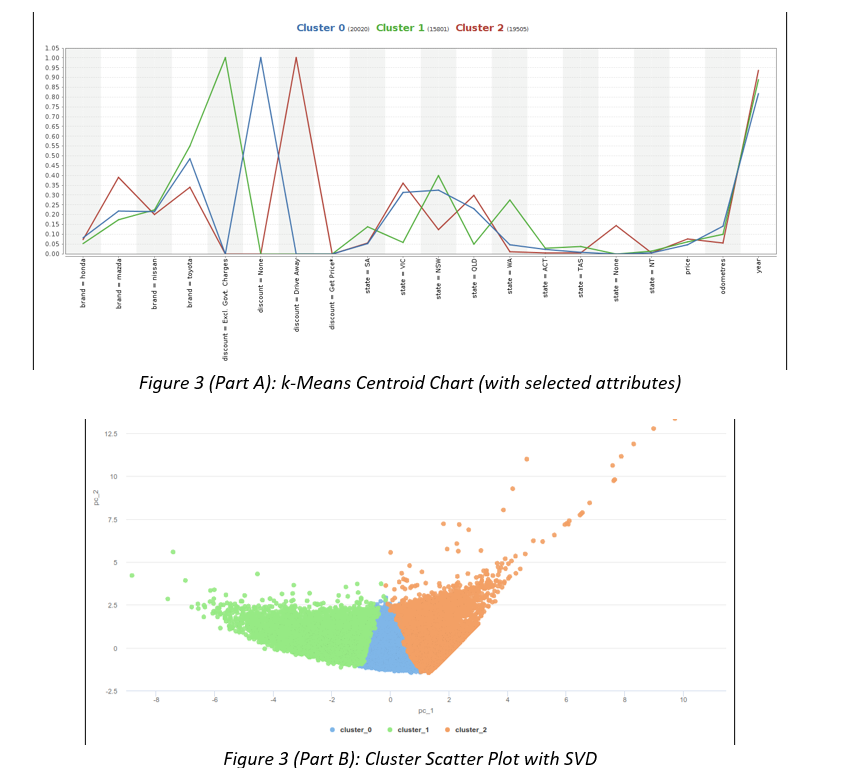
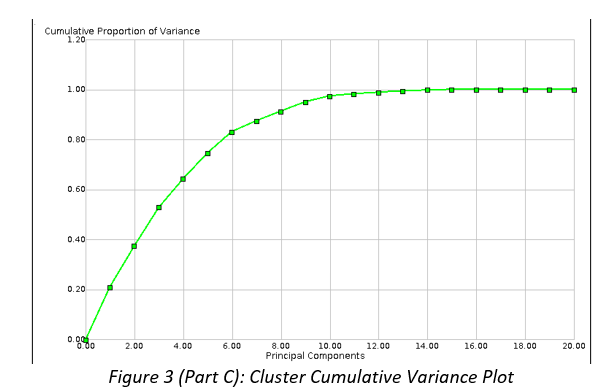
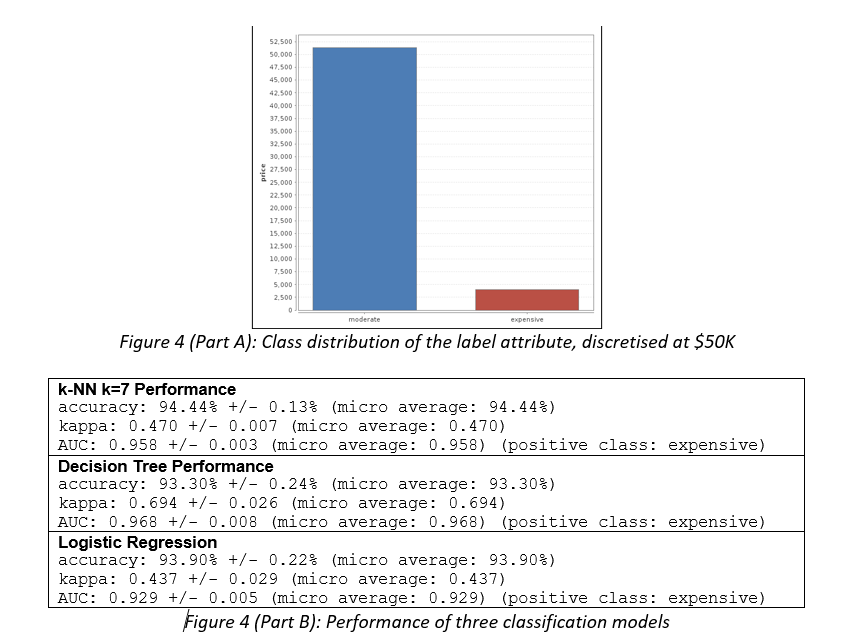
Business Scenario: Second Hand Car Sales A large Australian second hand car dealer Pre-Loved Cars (P-LC), with dealerships across all Australian states, asked you to develop a method of estimating a purchase price of any new car brought into their dealerships. At the moment, each car is described using structured data only, which is based on the car detailed evaluation in one of their workshops. However, in the future P-LC would like to pro-actively seek business opportunities by identifying prospective clients personal advertising placed on social media. P-LC provided you with data of past car evaluations and would like you to clean-up and explore car data, develop and evaluate a model predicting their prices (label), and minimize the classification or estimation error in the process. They have already undertaken some model development and attached the preliminary results for your comment. In several cases, the original numeric label was discretised. Data P-LC provided you with a sample of 55,870 car evaluations, which include 13 attributes: car ID, brand, model and their popular name (title), type of discount given, odometer/mileage reading (kilometres), body type, transmission, engine, state where the acquisition was made (e.g. Victoria), seller type (e.g. Private Seller), year of car manufacturing and price (label). P-LC are also planning to include a new attribute advert to include text sourced from social media. Some attributes have missing values or outliers. Charts and tables The following charts and tables will assist you in your tasks.
In the context of the Classification Performance, define these concepts and explain how they are used in the evaluation of a classifier: A. Classification Error, B. Kappa, C. Recall, D. False positive rate.
Provide the following information:
- Concept A is defined as and is used to
- Concept B is defined as and is used to
- Concept C is defined as and is used to
- Concept D is defined as and is used to
Step by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
Performance Audit A Case Study Of Indian Metro Railway Metropolitan Transport Project
Authors: Nilay Saha
1st Edition
3846510556, 978-3846510551