comp384 telehealth sas assignment Perform the following steps first perform model validation on a linear regression model: Using Partitioned Data in a Linear Regression Model
comp384 telehealth
sas assignment
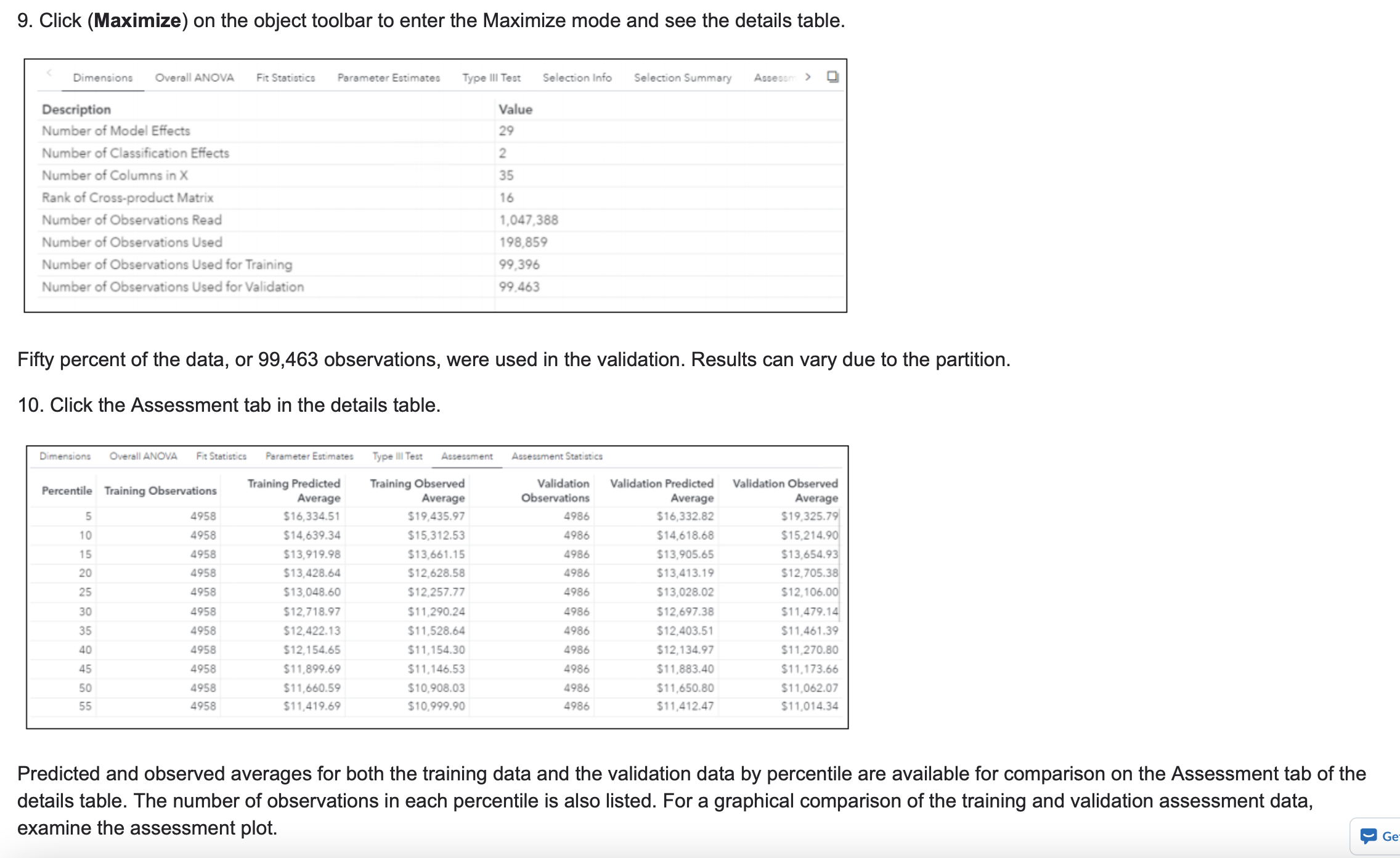
Perform the following steps first perform model validation on a linear regression model: Using Partitioned Data in a Linear Regression Model 1. Open the previous report, VS_BankLinear. In the upper right corner, click (Menu) and select Open -> My Folder -> VS_BankLinear. 2. Click Open. 3. On the Page 1 tab of the Linear Regression, click (Options) and select Duplicate Page. This linear regression model with a filter yields the following results: . R-square: .0941 . RMSE: 6031.44 . ASE: 36,375,307.4 . Observations Used: 198,859 . Logged, imputed RFM variables with p-values > .05: rfm1, rfm3, rfm7, rfm12 4. In the Data pane, select New data item -> Partition. 5. In the New Partition window, enter 50 in the Training partition sampling percentage field and click OK.New Partition Name: Partition Based on: O Data item O Sampling Sampling method: Simple random sampling Number of partitions: 2 Training partition sampling percentage: * 50 Random number seed OK Cancel 6. Select the duplicated Linear Regression on the canvas of Page 1 (1) so that it is the active object. 7. In the Roles pane, add Partition as the partition ID. 8. Click the Assessment tab.Linear Regression tat Interval New Sales Validation ASE 36,358,640.9218 Observations Used 198,859 Unused 861,179 Create Pipeline ... Fit Summary Residual Assessment Assessment tot Interval New Sales $20,000 $18,000 $16,000 $14,000 $12,000 $10,000 $8,000 Percentile 0 20 40 60 80 100 0 20 40 60 80 100 Partition Training Validation Predicted Average Observed Average The Validation ASE (Average Square Error) of the new model is 36,358,640.9, and 198,859 observations were used (for the entire model.) Although it is still showing issues with bias, the validation assessment might also reveal an indication of model complexity. Note: Even if you specify the random number seed property, you still might see nondeterministic results due to the difference in data distribution and computational threads or the walker that is used to sample the partition column.9. Click (Maximize) on the object toolbar to enter the Maximize mode and see the details table. Dimensions Overall ANOVA Fit Statistics Parameter Estimates Type Ill Test Selection Info Selection Summary Assessn > Description Value Number of Model Effects 29 Number of Classification Effects 2 Number of Columns in X 35 Rank of Cross-product Matrix 16 Number of Observations Read 1,047,388 Number of Observations Used 198,859 Number of Observations Used for Training 99,396 Number of Observations Used for Validation 99.463 Fifty percent of the data, or 99,463 observations, were used in the validation. Results can vary due to the partition. 10. Click the Assessment tab in the details table. Dimensions Overall ANOVA Fit Statistics Parameter Estimates Type Ill Test Assessment Assessment Statistics Percentile Training Observations Training Predicted Training Observed Validation Validation Predicted Validation Observed Average Average Observations Average Average 5 4958 $16,334.51 $19,435.97 4986 $16,332.82 $19,325.79 10 4958 $14,639.34 $15,312.53 4986 $14,618.68 $15.214.90 15 4958 $13,919.98 $13,661.15 4986 $13,905.65 $13,654.93 20 4958 $13,428.64 $12,628.58 1986 $13,413.19 $12,705.38 25 4958 $13,048.60 $12,257.77 1986 $13,028.02 $12, 106.00 30 4958 $12,718.97 $11,290.24 4986 $12,697.38 $11,479.14 35 4958 $12,422.13 $11,528.64 4986 $12,403.51 $11,461.39 40 4958 $12, 154.65 $11,154.30 4986 $12,134.97 $11,270.80 45 4958 $11,899.69 $11,146.53 4986 $11,883.40 $11,173.66 50 4958 $11,660.59 $10,908.03 4986 $11,650.80 $11,062.07 55 4958 $11,419.69 $10,999.90 1986 $11,412.47 $11,014.34 Predicted and observed averages for both the training data and the validation data by percentile are available for comparison on the Assessment tab of the details table. The number of observations in each percentile is also listed. For a graphical comparison of the training and validation assessment data, examine the assessment plot. Ge11. Click the Assessment Statistics tab in the details table. Observed Average Obsewatlons Used Unused The Assessment Statistics tab contains both the training and validation ASE (average square error) as well as the number of observations that are used to generate each statistic. Once again, results can vary due to the partition. 12. In the upper right corner, click (Menu) and select Save As. Navigate to Folders -> My Folder and name the report VS_BankPartition. Click Save as Practice 3. Building a GLM Model to Predict the Amount of Donations For this assignment, you use the PVA data set to build a GLM model. The target variable is transformed to be more consistent with the restrictions that regulate the analysis. a. Open Practice 3 completed as instructed above. Examine the results of the linear model. 1. Does there seem to be a problem with model bias? 2. Do the residuals seem to satisfy the assumption of constant variance? b. Build an appropriate GLM model for the continuous target under the assumption that it follows a log-normal distribution. Duplicate the linear regression model on a new page as a GLM. Select the Informative missingness check box. Use a Backward elimination method with the Significance level selection criterion and default signicance level of .01. Set the link function to Log. c. Does the GLM model solve the problems that you found in the linear model, if any? d. What main effects were removed from this model during the backward variable selection process? (Do not include the _miss variables.)
Step by Step Solution
There are 3 Steps involved in it
Step: 1
Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2
Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance