

Question
Consider a labeled data set containing 100 data instances, which is randomly partitioned into two sets A and B, each containing 50 instances. We use
Consider a labeled data set containing 100 data instances, which is randomly partitioned into two sets A and B, each containing 50 instances. We use A as the training set to learn two decision trees, T10 with 10 leaf nodes and T100 with 100 leaf nodes. The accuracies of the two decision trees on data sets A and B are shown in Table 3.7.
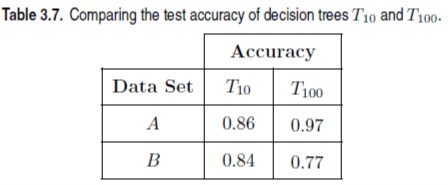 (a) Based on the accuracies shown in Table 3.7, which classification model would you expect to have better performance on unseen instances? (b) Now, you tested T10 and T100 on the entire data set (A + B) and found that the classification accuracy of T10 on data set (A+B) is 0.85, whereas the classification accuracy of T100 on the data set (A + B) is 0.87. Based on this new information and your observations from Table 3.7, which classification model would you finally choose for classification?
(a) Based on the accuracies shown in Table 3.7, which classification model would you expect to have better performance on unseen instances? (b) Now, you tested T10 and T100 on the entire data set (A + B) and found that the classification accuracy of T10 on data set (A+B) is 0.85, whereas the classification accuracy of T100 on the data set (A + B) is 0.87. Based on this new information and your observations from Table 3.7, which classification model would you finally choose for classification?
Step by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
Machine Learning And Knowledge Discovery In Databases European Conference Ecml Pkdd 2014 Nancy France September 15 19 2014 Proceedings Part 2 Lnai 8725
Authors: Toon Calders ,Floriana Esposito ,Eyke Hullermeier ,Rosa Meo
2014th Edition
3662448505, 978-3662448502