Consider again the TopUniversities data used in class. In addition to the existing attributes, U.S. News & World Report also provided rankings for the 25
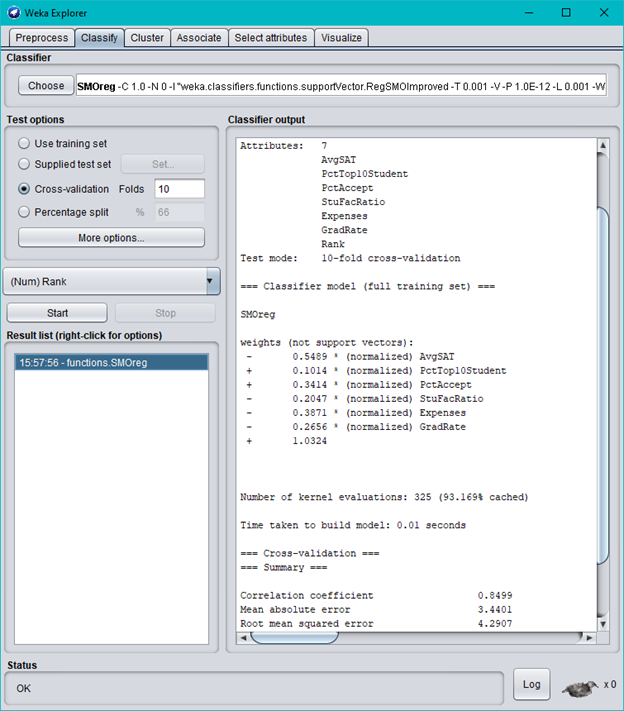
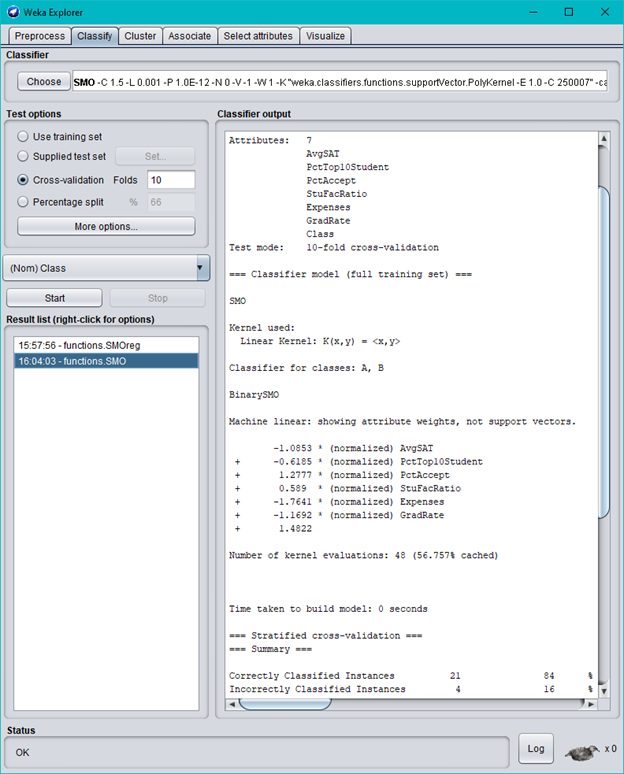
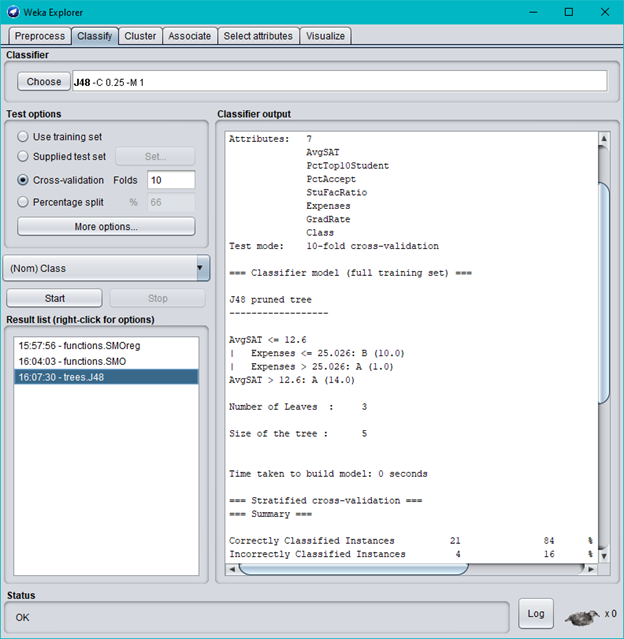
Consider again the TopUniversities data used in class. In addition to the existing attributes, U.S. News & World Report also provided rankings for the 25 universities. The rank order is the same as the position of the university in the dataset, e.g., Harvard is ranked #1, Princeton #2, ..., and Texas A&M #25 (see the list on the horizontal axis in the last screen in Question 29). The first output screen below is generated by Weka's SVR algorithm (SMOreg), using the university's rank as the target attribute. Then, we replaced the numeric ranking attribute with a 2-class attribute by grouping the first 15 universities to class A and the remaining 10 universities to class B. Based on this grouped dataset, the second output screen is generated by Weka's SVM algorithm (SMO) and the third output screen is generated by Weka's decision tree algorithm (J48). Answer questions (a), (b), (c) and (d) following the output screens.
Weka Explorer O X Preprocess Classify Cluster Associate Select attributes Visualize Classifier Choose SMOreg -C 1.0-N 0-I"weka.classifiers.functions.supportVector.RegSMOImproved -T 0.001 -V-P 1.0E-12 -L 0.001 -W Test options Classifier output Use training set Attributes: 7 Supplied test set Set.. AvaSAT PetTop10Student O Cross-validation Folds 10 PotAccept StuFacRatio Percentage split % 66 Expenses GradRate More options.. Rank Test mode: 10-fold cross-validation (Num) Rank == Classifier model (full training set) === Start Stop sMoreg Result list (right-click for options) weights (not support vectors) : 15:57:56 - functions.SMOreg 0. 5489 * (normalized) AvgSAT 0. 1014 * (normalized) PotTop10Student 0. 3414 * (normalized) PotAccept 0.2047 * (normalized) StuFacRatio 0. 3871 * (normalized) Expenses 0.2656 * (normalized) GradRate 1. 0324 Number of kernel evaluations: 325 (93.1694 cached) Time taken to build model: 0.01 seconds === Cross-validation === mmm Summary === Correlation coefficient 0.8499 Mean absolute error 3. 4401 Root mean squared error 4.2907 Status OK Log A XOWeka Explorer O X Preprocess |Classify | Cluster |Associate |Select attributes Visualize Classifier Choose SMO -C 1.5 -L 0.001 -P 1.0E-12-NO-V-1 -W1 -K"weka.classifiers.functions.supportVector.PolyKernel -E 1.0-C 250007"-ce Test options Classifier output O Use training set Accribuses: 7 O Supplied test set Set. AVSAT PetTop10Student O Cross-validation Folds 10 PotAccept StuFacRatio Percentage split % 66 Expenses GradRate More options... Class Test mode: 10-fold cross-validation (Nom) Class = Classifier model (full training set) mmm Start Stop SMO Result list (right-click for options) Kernel used: 15:57:56 - functions.SMOreg Linear Kernel: K(x, Y) = 16:04:03 - functions.SMO Classifier for classes: A, B BinarySMO Machine linear: showing actribute weights, not support vectors. -1. 0853 * (normalized) AvgSAT -0. 6185 * (normalized) PotTop10Student 1.2777 * (normalized) PotAccept 0.589 * (normalized) StuFacRatio -1. 7641 * (normalized) Expenses -1.1692 * (normalized) GradRate + 1. 4822 Number of kernel evaluations: 48 (56.7574 cached) Time taken to build model: 0 seconds www Stratified cross-validation mmm mmm Summary mmm Correctly Classified Instances 21 84 Incorrectly Classified Instances A 16 Status OK LogWeka Explorer X Preprocess Classify | Cluster |Associate Select attributes Visualize Classifier Choose J48 -C 0.25 -M 1 Test options Classifier output O Use training set Attributes: 7 Supplied test set Set. AVUSAT PetTop10Student O Cross-validation Folds 10 PetAccept StuFacRatio Percentage split 96 66 Expenses GradRate More options... Class Test mode: 10-fold cross-validation (Nom) Class mmm Classifier model (full training set) mmm Start Stop J48 pruned tree Result list (right-click for options) 15:57:56 - functions.SMOreg AVOSAT 25.026: A (1.0) 16:07:30 - trees.J48 AvgSAT > 12.6: A (14.0) Number of Leaves : Size of the tree : Time taken to build model: 0 seconds Stratified cross-validation mmm mmm Summary mmm Correctly Classified Instances 21 94 Incorrectly Classified Instances Status OK Log
Step by Step Solution
There are 3 Steps involved in it
Step: 1
Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2
Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance