

Question
Consider an MDP with 3 states, A, B and C; and 2 actions Clockwise and Counterclockwise. We do not know the transition function or the
Consider an MDP with 3 states, A, B and C; and 2 actions Clockwise and Counterclockwise. We do not know the transition function or the reward function for the MDP, but instead, we are given with samples of what an agent actually experiences when it interacts with the environment (although, we do know that we do not remain in the same state after taking an action). In this problem, instead of first estimating the transition and reward functions, we will directly estimate the Q function using Q-learning. Assume, the discount factor, is 0.5 and the step size for Q-learning, is 0.5. Our current Q function, Q(s, a), is shown in the left figure. The agent encounters the samples shown in the right figure:
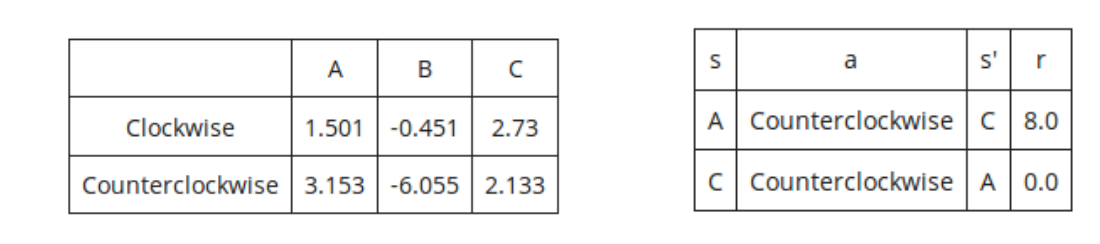
Provide the Q-values for all pairs of (state, action) after both samples have been accounted for.
s A B a s' r Clockwise 1.501 -0.451 2.73 A Counterclockwise C 8.0 Counterclockwise 3.153-6.055 2.133 Counterclockwise A 0.0Step by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
Introduction To Data Mining
Authors: Pang Ning Tan, Michael Steinbach, Vipin Kumar
1st Edition
321321367, 978-0321321367