

Answered step by step
Verified Expert Solution
Question
1 Approved Answer
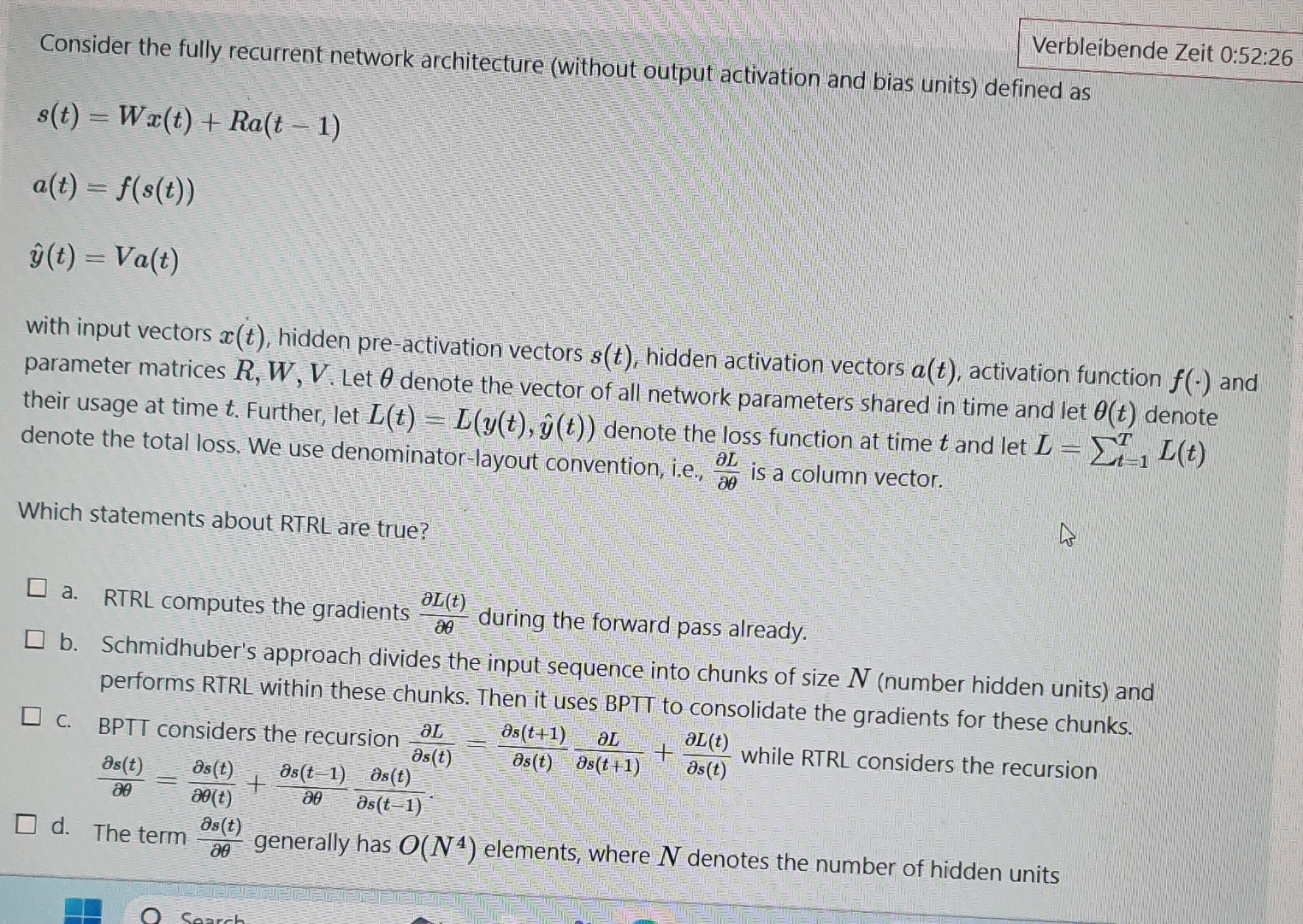
Consider the fully recurrent network architecture ( without output activation and bias units ) defined as s ( t ) = W x ( t
Consider the fully recurrent network architecture without output activation and bias units defined as
hat
with input vectors hidden preactivation vectors hidden activation vectors activation function and parameter matrices Let denote the vector of all network parameters shared in time and let denote their usage at time Further, let hat denote the loss function at time and let denote the total loss. We use denominatorlayout convention, ie is a column vector.
Which statements about RTRL are true?
a RTRL computes the gradients during the forward pass already.
b Schmidhuber's approach divides the input sequence into chunks of size number hidden units and performs RTRL within these chunks. Then it uses BPTT to consolidate the gradients for these chunks.
c BPTT considers the recursion while RTRL considers the recursion
d The term generally has elements, where denotes the number of hidden units
Step by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
A Beginners Guide To Google Drive And Docs Step By Step Practical Instructions To Google Drive Docs Sheets And Forms
Authors: Robert William
1st Edition
B085K8N4LN, 979-8615386251