

Question
CSC 143 You are required to complete this exercise using Java Map Collections Framework (as described in Chapter 11). Attach the source code file (*.java)
CSC 143
You are required to complete this exercise using Java Map Collections Framework (as described in Chapter 11).
Attach the source code file (*.java) when submitting this.
Hint: here is the beginning fragment of the output protein string: MTCSAIISAESFHLPALLPHHKLFSKPTESVTPSIFCSYREQIPRVLRNFIRILIPNENNVSSQFRTVSLNDRC
AUGACGUGCUCGGCAAUCAUCAGCGCGGAAUCUUUUCACUUACCUGCUCUUCUUCCUCAUCACAAGCUCUUUUCCAAACCAACAGAAUCCGUUACUCCGUCAAUCUUCUGUUCCUAUCGCGAGCAGAUUCCUCGGGUGCUACGCAACUUCAUCCGAAUCUUGAUACCAAACGAAAAUAACGUCUCGUCGCAGUUUCGCACAGUGUCCCUAAAUGAUCGCUGUGAUCUUGCCCUCGGUAGAGCCCGUGUCGCACUCUCUGCCACUGCUGAAAUGCCAACCCGCGCCCCAUCAUCACAAGGCGAAUCUCUACAGUUCUGGUUCCUCUACAGAAUGCUCGAGCAUGCCGGUUUGACCACCGUCCCACGCGUAACGCUCGAAAGACGCUCGGCCUCCAUCCUCGCCUCCAAUGCGCCAUGCAUAUAUCCAGCUACGAUGAGUAGACCGGGCGCGUCUUUAUCUGCAAGAACUCUGUCGCAGGGAGGCUUAAGCAACGGUGCUUAUGGGCAUCAUCCAUCCCUCAGCGGGUUAAUGGGUGACUUGAACACCAACGUCGAUUUACUUUCUACCUCGAAUCCUCCCCUCUUCGGUCUUCCUGCGGAGGCACAUUCUUGCCCGAAUAUCUUCAUACCACUUGGCAAAGGAAGAAUCGCCACAUGGCCGGGCGUUUUGACAGUUCGGAGUCUUGGUAUAUCUUGCCAAGGUUCGACUCAGUCAAGAGUGCACGGCAACCUAAAAUACGAAGGUGCACUUUCUCACACACGCCGGCAAUUGUCUCGUUACCGGAGCACGGUCAAACUAUCGCGAAUCAAGGCUCGAUUUAAGCGUCUAUGGCCUUCACUCCGCGUCCGGACAGAAACGAGGUCACUGAGAAACCGAGCGACGCUAAUCACGACUUCAGGUUACGACCAGCAUUUGCCACGGGCGCUGACGGCGUCGGAACGCACUGGCCCAUCACCUUAUUCUUGGAGUCACCCAACUCUCACCGCUGAAGAAAAUUCUGGAGGAACACACUACAGCCGUGAAGCACGCAACGUCAUUCUUCGCGCUGUGAUUACGUCGGCAUACUUGUUUGAUUUCCCUACUGGGACCGAGGCGUCAGGAUUAAUGCUCACAAAAUCGUGGUACGUACGAGGGCUAAUACGGAUGUAUGGCGGCGAACUUAAAAACUUCAAACAUACCCUCUUGCGUACGCCGGCGGAUUUGAACUACUUAGCAAUCAACUACUUUCUGCCGUCAGCUUGCUACGGGAGUUGCACGGAGUGGGAAAAGCAUAUUUCCAUUUCAGCAUCGUUACCUUCGGACGUCGUCUCCCAGUUGAGUGUCGCUGGUGUGGUUUGCCAAGUAGGGAACCAAGACCGAUUUGUGCAAGUGUGUCGGGCGACUGAGUCAAACAGUGGUAGCCUAUCAAAACGCGGUUACGUCAGGAGACCGCGGAUUCACCAAUGCUUAGACCCCCCUCCCCGCCCUGGGUUAUUGCGACUCUGGCGAUCCGAUGGCACGGCCUUUGGCUUAUGUAAGAACAGUAACUUCGCCGUAGGCCACAAUGCGGAACCCAUACCCAGCUGGCCAAACCAAGAGCGGGCUUGCUGGCCUUUAAGAGCACAGCGCUGCUACCAGUUUAUGAACAGCAGGGGAGUAGUGUCUACCUCACUCUACGAUAGUAUUCCUGCAAGCGUGCCACUUUGCCGCCGGACUGGGCCUUUACUUUUAUGUUACAGCAAAGUAAGGCAAAUCAUGGCUAGGGGCGCCCUGGAUCCGGAACAUCGGCUGCGGGUGUAUCUUUCUCAAACCAAAAACCGCUGUGCCGCCCUGAGUUCGCAAUUAUCAUCUCAGUCGAGGCCAGCGCAAGAUCUAGACUUUGAGGACGAGGCUCAGGACGAGCAGUGUACACAGUCUGGGGUAGGAGCGGUCAAGCUCUGGCCAUUUAUUCUCGACCGCUCGCCUAGUCGAGGGUUGCGAACGUCGGGUUUGCUGCUAGUGAAUAGCGCGCAGUUAGCGAGUGCGGACCGACAGGGCUCGUUCCGUCGGUUCCACGUGAGUCAGGAGAAUCUUUCCACCUCAGUGGGACGCUGCAGGAUGAGGCGUCCAGAGGGCCGCUUACCGCAAGGGCGGUCGGUGGUUCGACUUAACGUUGACCGAUGUUGUCUCGUCUAUGGACUAUUAUGCAAUACCGAUAGGUGGGACUCAUCCGGCUUCGUAACGAAAGACAAACCGGCGGUCAGUGUCGCAAAUAAACAUUGGCUGGUCCGAACACACUAUGGGAGUGGCUCAUCAGUCAUACUUGAUAUGAUAGGAUGCCUCCCCCUCCUGCUCCCUGCACGGAGGCUCCAAGUACGCUCAUGCUACGAUUGGUGGUUUGGCUUUGUCUUCUCUAGCACGCGGGCACGCUCAGGUUCUUUUAUAGUGCGUCGAGGAUUCACUGUCGCCGUCCGCGAGAGGGGGACCUGUCGCGUUGCAGAAAAGAUCUAUACUCAUUGUACAAGCACGUUAUAUCAGGCCGAAUAUCCGCUGCUUCUUUCCUUCCCCAUUAACGACGAGCAAGAAGGGGAACGAGGUUUCCUGUGUUCGAUGUAUCAAAGUGGCGCUCUCGGAAUUGGAGGGGGUUUUCUCAAUCCCUCGGGUGUCCGUGCGCAGGGGUCAACCUCACCGGAGGCUCAAGCAAAAGCUCCGACGAUAUGUCCAAUUAAACCACCUCAUGAAUACCCCUCCCUCCCCAAGUCGGGUGCAGUUGCGUGUAGUCUCAGGAGGAUGGAUUACUCGCGUCCAAGUGCUACAGGUCCCCUGAUGAGCUCCAUCACGCUGAUCCACAACCGCGGAGACGGCACUACUCGCCAGAAUUACAUGGGUCAUUCCAGGUCAAUGGUGAGGGUUUCUCAUGACCAGGGCCGGUCAUGGGUGUCGUCGCUGUCAAACGAUACAGCGACCUAUAAUGCCUAUUUACACCUCGAGCAGGGGGGAUACAACAGCGCAGUCAGCCAAGUUUCAGGUUUUACCGCAAUCCUCUGUAGGUCAACUAGUGCACACGGGUUACCCCACGGUCGUAUAACGUCUCGGCAUGUUACGUCUAGCGUCACGAAAAGGCGUCGGUACAACCCUCAGGUUUUAACCUUGGGCCAACCAUGCAAUAAGCUAGGUGGACCGUUCAGACCUAUGGUUCCUCACCAUCGGGCAAACGCAAGGGCCGUGGUCUGCAGGGAAAUAUGGGAGAGAAGUAAUGAUGUAACAGUGUCUGGAGGGACGACCUUGAGACUGCGUUACCGUUCCAACGCCCGUCGCUCCGCUUCACGGGCAUUCAAAACGUGCCCGGGUUCAAUCAUUAGCGACAUAUACCACAAGGCGGGGGGUCCCUAUCUCACGUCCGAAAUCCCACGAGCAUUAAAGGCGUUGAACCGCGUGUUCGAUGCGCCUGUUAGAUUAACAUCAUACUCUUUCGAGACCAAUAAAAGUAGUGGUAACAACAUAAGACCCUGCACCACCCAAGUAACGGUUAACAGCCGGAAUCCCGCACAAAGUCUCCGUUACGUAUCUUUUAAAAUGAGGUCUGCUACGGAGAAUUCAAUAGUUGUCUCAGGCGUCGAUCUUCUCGGGUUCUACAGCAAUUGCCACAGUUUUACCAACACCGACACGAGGUGUACUCUGCUACCGGAGCACCAUGCCCCUUACACGUUUCAUGGACAAAGGAAUUCGGCUGAUGGGGUUCCAAGCCGAGGGUGUGUUAAUACGUUUUUCAUGAUCCAGGUUCCUUCCUACGUCGUCUUGGAUUUCUUUGCCUUUGAGACGCACUAUGCUUCGACACUGUCCCAACUAAAAAGGGGCAAGAUUUACAACUGUUUGGCUGAUUCGGUUCUGGUCCGAGAUAUGCUUAGCAGCAGCACUUCCUUUACUUAUACUCCUAACCCGAUGAAUCCCGUGCUUAUCUUUCGUGAGACGGGGAUUUGGGUUUCGCUCUCGAACUUAUACUCAUCCCGCCGCAUAAAGAAUCUCCCAAGUAUCGCCUUAGAUUAUCUCUGCAAUCCACAUACAGAUCGGACACAGUUGGUCAGUAGUGCGAAACUACCGGGUAAACGAAAGUUAACUGCCUUCAGUCGCUUGCCUGUUCUAGGCAGGAACGAAGCAUUCGGUGCGGUAGAGGUGGUCGCCGCGUCACAUAUUAGGAGGCCGCGUAGAUACCCUCAAGUAGCUCGACGGCGGUUUCAGGCUGGCAGAUCACCCGAUGUCAGAUCGGAGCUAGCGCGUUUAAGGAUGACGGCUUUGGGGUUUCGAGAGAUCGCGUCUGUCCCGUCUUCGCGUGCAAUAAUGAGUAUGGUCGCAGGCCGAUUGAUCCCUCUGUCCCCCACGGCUGCAUGUUUAGCUCAGUACGUCCUGCUCCCUGAAACCGAUUUGUCUUCACUACUUAUUAAGGCGCAGUUGCCCUUUGGCACACCCUACGGUAGACAGGUAUCUGCCCGCUGUUUUAGCAAGGAUGCGCUGCAUCCCGCUACACCCGCAAGUGGAGGACACCACCGGGGCCCCCAUCCUCAGUGCCGUGUCUAUUCCUCAUCUCGGCUUCCACUGAGGGUACACCAAGGGCGAUGGAGAGUGCGUCCUGUGGAUUGCCAACCGCAUACCACGAUAGUGCGCAAUUACUCGUGGCGCUACAGGAAACCUCGCGAGUCGCCGGAUUUCCACGUCCAUUUGCAUAAUAACUCCUUGACGCCACCUUCGUACGGUAGCCGAUGUCCUCAAAAACCCCUACAUUUAGUAAGCCUUAUGCUUUUUAGUCCUGUGAAGGCAAAUGUGAUGGUCCGGGGGUGCCUACUAUGCUUGUGGCGUGAUAUGAGGUAUCAGACCUUCCUAACAGUCUGCCUAGAUCCUUUGACGCGAAGGGACGAUGUUGGGAGUCGGGCUGGUUCCAAUGAGGCGAAAAUGUAUCUCACAGGAGCGAUAGGAGGCCCCAGCGGCAGACAGCUCACACUAGCCAAACUAACGUUCUCAAAUAGUACCACAAUUCUGACCAUCAUGCUUCGUCUUUCACAGAACGGAUCUGGCAAAGAUACUAAGCCCCACGCAAUGUCUCGUAUCCGUGUUAGGCUAUAUACUGGGGCAUGCUCUUGUCGGAAGAACUUGAAUCCCUCAGCUAGGACAGACCCCGCAAAACCAAUCUUUAACCGGGGCAGAAUCCCCUCACAGCCUAUCACCAGCCAAAUGAGCCGUGGUGGGUCUCCAGGGUUGGUUCUAGAGACUUUGACAUUAUGCACACGCGAGACCCUAAUCGGACAACACGUAUGUCGACACCAUAACAUGGGGUUUAUCUCGCGCCUCGUGCCAAGGCCAAUCGGCCUACAGGUGACAACGAGAAAUGUUAGAAAUGUACUGCUUCGACAGCGGGAGUGCGAGUACCGGAUAUCGCGACCUUUGGGAGAUGUCUUUACCCCUGCUCCAAGUAUCGAAUAUGCCACUUACACAACUUGGUGCCUCGUAGGACCCUUCCCACCGAAACGUAUCUGGUCCUUGACCACAGGCGGGCUUUACGCACGUGCCCCCCGCUUCGAGAGAUCGUGGGUCAUCAAGUGUCGCAAAGUGCGUUAUAACGGCUCCUUCGGUUUUGAAAAUCUCGCACCGAGAUGCUUUAUGUUACACCAGUCAUCAUUAAUCUGCUGGCUACCUAUCGUAACGAACUCCCUCUACGUAUGGAGGACCGCGUCUUCGCUAAGACAGUCAAACUACAUGUUCAGCAUUUUAGUUUUCGGUAUCUUUAAUAUUCAACCAAACCUGGAAUCUAUCCUUUAUUUUUUAAUUGAGUGGCCCACUCGUUGGACAUCGGGGAAAACGGGUCUGUGGAAGAGAUGCCUACAAGUGGUAGCCAUAGAGGGAGUGAUCACGGGACGUGUUGGAAACUCGGCAAUCCCCGGACAUUGCAGCCCGGGUAUUGUCCUCAGCCGACCAUGUUGUUUCGCACUCCACCGAAAGAGGGGACCAGACAGGUCGUACCCCUUUGACGGGGCACAGUCCCACCGUUAUGCAACCUCGUUUGUCUUUUGGACCGUAUUUAGCUACCGCCUAGGCACUGUGAUUGUAACCGAGGGCAUUGUGGGGUCCGACACAUUUUCCAAGGGCACACAAAUACGGAGCCGGUGGAGUGAAAGACCCAUCCGUUCUACCAUACGGCCUGUGUGUUGGAGGCGGUAUGUUAUCCAUGAAUCAGUUUUCCUUACUAAUACUAGGGUUCAGAGAUGCAAAUACGCAAGUAAUCGGUCUACUGGACCGAUAGAGGCAGUGACGUUUAGUUCGCUGACGACUCAAAGGUAUCGUUUUCGAGACGGGGAUUUUACCGCGUACAGGUUACGUCCAACGUUAUCGAAUGUAAUAACGGAUUAUGGCUCAACUGUAAUACUCUCCCUUUCCAGCCUUGGAGGCGUCACCCCGUUUAUUUCCGUCCGUACAGGCACAUUAGCGACGGAAUGGUCGUAUAUAUUCAAGACGGCUCUCAUAUGGCUAUCACUGCAGCCUCUGUGGUUGUCGGAUUGUGAUUUUAAAAAACAUCUAUCUGAGUGGUCAUGCAAAUUCCGAUACACUCACAUCUAUAAACGCUUACUUACGUUAGUACCCAAGCGGUCCUACCUACGAUCUCUUUUCUUAUAUCCAACGUACGGAGUUUUAGGUUCAGAUACGGUCACCGAUACUUCGGUCGCUUGGACACUGUGCAGCGUAGAUUACAGGUGGUGGUGUGCAGUGACAAGCCUGUGGCCAGCAGCCGCUUCGAGGCAUCUCCUAAUCCCGGAGUCUUAUUCUAGUGCCAUGUCCAUCAGCAUGGGAUAUAUCAGGACUCGCUUUGCUCUAAGGAGUUUUAGCUCUAAGCCGAUCCCGGGAGACGGCUACUCUAUGCCAUAUAACAGAGCUAACGCACCCAUAGUCCUGCAGAUUCGCAGACUGUUGAGAAUCUUGUUUGGACCGGGCUUUCCUGAGGUGUAUAGUGGUGUAUGCGGUGAGAAUUCAAUUAAAUCGUUUAAGCCGUGCCCAAGAGCAAAUCUAUGUUAUAUCACAAAAUUACGACUGGUCUCUGACCAUAUCAUCAUAGUACGGGGGACACGCAUUCCUCAAGAACGGGACAUGAGCGGCUGUCUCUUCAAAAUCUUACAGUGGGCCCGGGAGCCCUAUAUUUGGGUCAGCACACCGAACAUGGCAAGACUGCAGGCGCACAUCAAAAAAUUAUAUAGUUCAUCGGCGGGAGCAGUCCCGGUUGCGCAAACGGUCGGCUUCCAUAAUCAAAGAGGCCAAGCGGAACGGAGCCGCGGGCCCAUCCGCUACCGGGGAUGCGGUAACACACCUCUUCUAGUCGACUCCCCUACAUGUCAUACCGUGUAUGGAGGACACUCAGCUUCCACAGUAGAGAGUGAUAUACGAAGCUUUGGGCUCAUAGAUUCAGUUGAUAUUUUAUUACCGCCCUGCACCGAAGAACGUUCGAAAUUUCGGCACUACACCGACUCCCACCGAUCGGUUAACACAAAUGAGGUGCUCGAUUCCACGGCUAACAGGCUGGAAGACAAUGAUUGGGAGGGUGAUGUCUUUAAGUCCGCGCCGGGUCCUUGUGGGUGUAUGACCGCAACGGGGAGCAAUGACCAAAUCCCUGUGCCUAUCUUUCCCAAUGGCUUUACCCUAAAUCAGGUGAUGGAAUUCAAAGGCGCUCAGCAACCUGGAGGUCCCAAUCGUAAUCCGUAUCAGCCACGCGAGCGAUUUGGUAGCUACUGGGACAGAUUUCGAGGAUGCCUAUCCCUUAACAGGUGGAGAUUAUUCGGAACUCGUACGCAGCGAAUGGAACCACAUGCUGCAGCUCUGACGCGGCUGCGUCGGCGGAGUAAAGAGGACUCUUAUAUCGUGAUGUCUCAGCCAUUUACUUUUGGGACACUGUUUUGGUCCUCACAGGAUACGCCGCCACAAUUCUGGAGCUACGGUAUAAUACGCACUACAGCACCUGCUGCUGUGUGGGCGAUCAUAAUUCCCUCUGACGCAUUCAAUCGAUCAGCCUUCUACUGUCGUUCUUCGCGGGGAGCAAGAAAUCGUCCGGUGUGCGUUCGCAGUGAGCUUCAGGAUAGACUGAAUAUCGGCAGUAAAGCCAUUUCCUAA
Translating RNA into Protein1 The 20 commonly occurring amino acids are abbreviated by using 20 letters from the English alphabet Henceforth, the term genetic string will incorporate protein strings along with DNA strings and RNA strings. The RNA codon table dictates the details regarding the encoding of specific codons into the amino acid alphabet. Here is the RNA condon table for your reference: Atable indicating the translation of individual RNA codons into amino acids for the purpose of protein Creation CUUL AUNUI UNUC F CUCL AUC I UUAL CUAL AUA I GLA V UUGL CUGL AUGM GUG V UCUS CCUP ACUT GCU A UCCS ACC T GCCA UCAS CCA P ACAT GCA A UCG S CCG P ACGT GCG A CAUH AAU N GAUD UALU Y UAC Y UAA stop CAA AAA K GAA E UAG stop CAG Q AAG K GAGE UGU C CGUR AGUS GGU G UGC C CGC R AGCS GGC G UGA Stop CGAR AGAR GGA G CGG R UGG W AGGR Given: An RNA string s corresponding to a strand of mRNA (of length at most 10 kbp). Return: The protein string encoded by s. For example: RNA String: AUGGCCAUGGc CC should be translated into Protein String: MAMAPRTEINSTRING Translating RNA into Protein1 The 20 commonly occurring amino acids are abbreviated by using 20 letters from the English alphabet Henceforth, the term genetic string will incorporate protein strings along with DNA strings and RNA strings. The RNA codon table dictates the details regarding the encoding of specific codons into the amino acid alphabet. Here is the RNA condon table for your reference: Atable indicating the translation of individual RNA codons into amino acids for the purpose of protein Creation CUUL AUNUI UNUC F CUCL AUC I UUAL CUAL AUA I GLA V UUGL CUGL AUGM GUG V UCUS CCUP ACUT GCU A UCCS ACC T GCCA UCAS CCA P ACAT GCA A UCG S CCG P ACGT GCG A CAUH AAU N GAUD UALU Y UAC Y UAA stop CAA AAA K GAA E UAG stop CAG Q AAG K GAGE UGU C CGUR AGUS GGU G UGC C CGC R AGCS GGC G UGA Stop CGAR AGAR GGA G CGG R UGG W AGGR Given: An RNA string s corresponding to a strand of mRNA (of length at most 10 kbp). Return: The protein string encoded by s. For example: RNA String: AUGGCCAUGGc CC should be translated into Protein String: MAMAPRTEINSTRING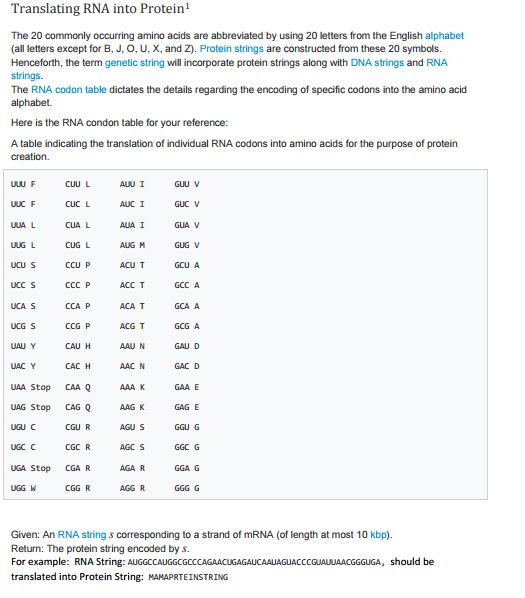
Step by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
Current Trends In Database Technology Edbt 2004 Workshops Edbt 2004 Workshops Phd Datax Pim P2panddb And Clustweb Heraklion Crete Greece March 2004 Revised Selected Papers Lncs 3268
Authors: Wolfgang Lindner ,Marco Mesiti ,Can Turker ,Yannis Tzitzikas ,Athena Vakali
2005th Edition
3540233059, 978-3540233053