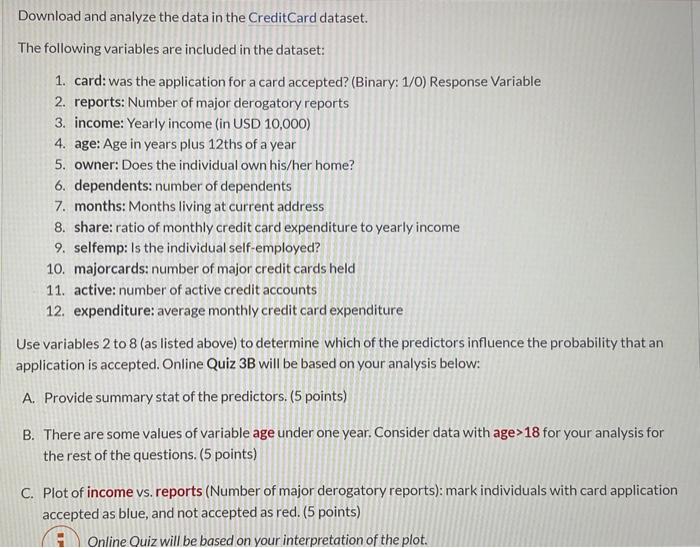
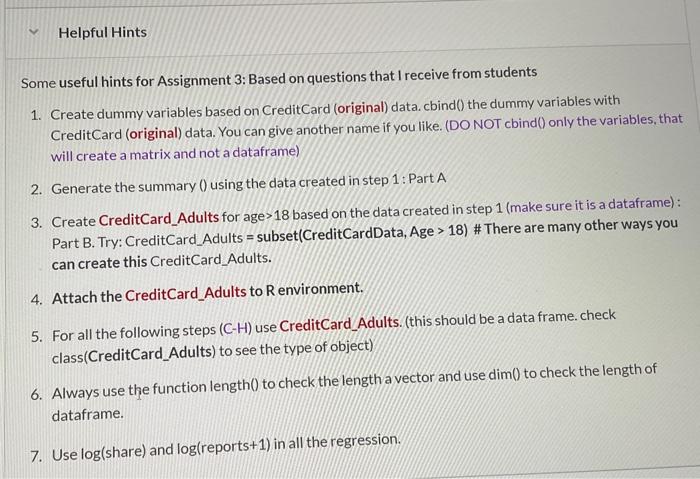
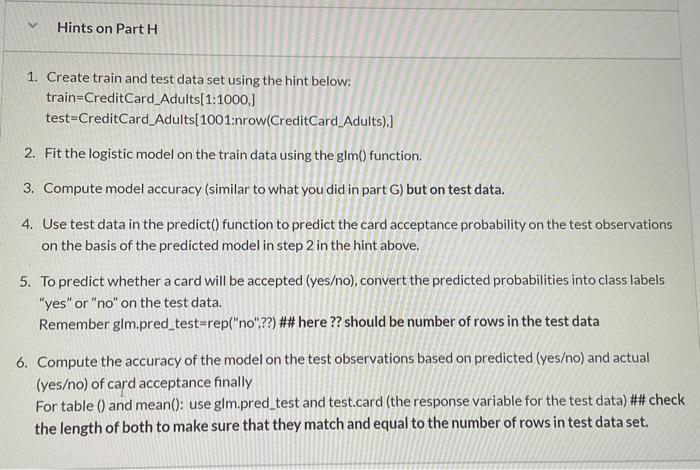
Download and analyze the data in the CreditCard dataset. The following variables are included in the dataset: 1. card: was the application for a card accepted? (Binary: 1/0) Response Variable 2. reports: Number of major derogatory reports 3. income: Yearly income (in USD 10,000) 4. age: Age in years plus 12 ths of a year 5. owner: Does the individual own his/her home? 6. dependents: number of dependents 7. months: Months living at current address 8. share: ratio of monthly credit card expenditure to yearly income 9. selfemp: Is the individual self-employed? 10. majorcards: number of major credit cards held 11. active: number of active credit accounts 12. expenditure: average monthly credit card expenditure Use variables 2 to 8 (as listed above) to determine which of the predictors influence the probability that an application is accepted. Online Quiz 3B will be based on your analysis below: A. Provide summary stat of the predictors. (5 points) B. There are some values of variable age under one year. Consider data with age >18 for your analysis for the rest of the questions. (5 points) C. Plot of income vs. reports (Number of major derogatory reports): mark individuals with card application accepted as blue, and not accepted as red. ( 5 points) Online Ouiz will be based on your interpretation of the plot. D. Boxplots of income as a function of card acceptance status. Boxplots of reports as a function of card acceptance status (mark card application accepted as blue, and not accepted as red). (Display two boxplots in same page). (10 points) E. Construct the histogram for the predictors ( 2 to 8 in the list above). (5 points) Note that share is highly right-skewed, so log(share) will be used in the analysis. reports is also extremely right skewed (most values of reports are 0 or 1 , but the maximum value is 14 . To reduce the skewness, log(reports 1 ) will be used for your analysis. Highly skewed predictors have high leverage points and are less likely to be linearly related to the response. F. Use variables 2 to 8 to determine which of the predictors influence the probability that an application is accepted. Use the summary function to print the results. (10 points) Online Quiz will be based on the following and related concepts: Do any of the predictors appear to be statistically significant? If so, which ones? Explain how each of the significant predictors influences the response variable. G. To predict whether the application will be accepted or not, convert the predicted probabilities into class labels yes with the following condition: probs >.5= "yes". Compute the confusion matrix and overall fraction of correct predictions. ( 30 points) 1.) Online Quiz will be based on the following and related questions: Explain what the confusion matrix is telling you about the types of mistakes made by logistic regression (false positive, false negative, overall correct predictions). H. Now fit the logistic regression model using a training data for observations 1 to 1000 . Compute the confusion matrix and the overall fraction of correct predictions for the test data (that is, the data for observations 1001 to end of data). ( 30 points) Some useful hints for Assignment 3 : Based on questions that I receive from students 1. Create dummy variables based on CreditCard (original) data. cbind() the dummy variables with CreditCard (original) data. You can give another name if you like. (DO NOT cbind) only the variables, that will create a matrix and not a dataframe) 2. Generate the summary () using the data created in step 1: Part A 3. Create CreditCard_Adults for age >18 based on the data created in step 1 (make sure it is a dataframe): Part B. Try: CreditCard_Adults = subset(CreditCardData, Age >18 ) \# There are many other ways you can create this CreditCard_Adults. 4. Attach the CreditCard_Adults to Renvironment. 5. For all the following steps (C-H) use CreditCard_Adults. (this should be a data frame. check class(CreditCard_Adults) to see the type of object) 6. Always use the function length() to check the length a vector and use dim() to check the length of dataframe. 7. Use log( share) and log( reports +1) in all the regression. 1. Create train and test data set using the hint below: train=CreditCard_Adults[1:1000,] test=CreditCard_Adults[1001:nrow(CreditCard_Adults),] 2. Fit the logistic model on the train data using the glm() function. 3. Compute model accuracy (similar to what you did in part G ) but on test data. 4. Use test data in the predict() function to predict the card acceptance probability on the test observations on the basis of the predicted model in step 2 in the hint above. 5. To predict whether a card will be accepted (yeso), convert the predicted probabilities into class labels "yes" or "no" on the test data. Remember glm.pred_test=rep("no"??) \#\# here ?? should be number of rows in the test data 6. Compute the accuracy of the model on the test observations based on predicted (yeso) and actual (yeso) of card acceptance finally For table () and mean(): use gim.pred_test and test.card (the response variable for the test data) \#\# check the length of both to make sure that they match and equal to the number of rows in test data set. card: was the application for a card accepted? (Binary: 1/0 ) Response Variable The question states following: "Use variables 2 to 8 (as listed above) to determine which of the predictors influence the probability that an application is accepted." Note: The order of variables are in the question (as follows) and not in the data set: 2. reports: Number of major derogatory reports 3. income: Yearly income (in USD 10,000) 4. Age: Age in years plus 12 ths of a year 5. Owner: Does the individual own his/her home? 6. dependents: number of dependents 7. months: Months living at current address 8. share: ratio of monthly credit card expenditure to yearly income In Homework 3, you will see how we can use Classification Model - Logistic Regression to predict credit risk measured by credit default rate based on customer's' credit history and other attributes. Work cooperatively to the following tasks in your groups, making sure to divide work evenly and document who contributed what. Note: Quiz 3B in iCollege will be based on this Assignment. Please have your R program available in running condition when you take the quiz. You will need solutions of your program to take the quiz. Quiz 3B is not under lock down browser. Download and analyze the data in the CreditCard dataset. The following variables are included in the dataset: 1. card: was the application for a card accepted? (Binary: 1/0) Response Variable 2. reports: Number of major derogatory reports 3. income: Yearly income (in USD 10,000) 4. age: Age in years plus 12 ths of a year 5. owner: Does the individual own his/her home? 6. dependents: number of dependents 7. months: Months living at current address 8. share: ratio of monthly credit card expenditure to yearly income 9. selfemp: Is the individual self-employed? 10. majorcards: number of major credit cards held 11. active: number of active credit accounts 12. expenditure: average monthly credit card expenditure Use variables 2 to 8 (as listed above) to determine which of the predictors influence the probability that an application is accepted. Online Quiz 3B will be based on your analysis below: A. Provide summary stat of the predictors. (5 points) B. There are some values of variable age under one year. Consider data with age >18 for your analysis for the rest of the questions. (5 points) C. Plot of income vs. reports (Number of major derogatory reports): mark individuals with card application accepted as blue, and not accepted as red. ( 5 points) Online Ouiz will be based on your interpretation of the plot. D. Boxplots of income as a function of card acceptance status. Boxplots of reports as a function of card acceptance status (mark card application accepted as blue, and not accepted as red). (Display two boxplots in same page). (10 points) E. Construct the histogram for the predictors ( 2 to 8 in the list above). (5 points) Note that share is highly right-skewed, so log(share) will be used in the analysis. reports is also extremely right skewed (most values of reports are 0 or 1 , but the maximum value is 14 . To reduce the skewness, log(reports 1 ) will be used for your analysis. Highly skewed predictors have high leverage points and are less likely to be linearly related to the response. F. Use variables 2 to 8 to determine which of the predictors influence the probability that an application is accepted. Use the summary function to print the results. (10 points) Online Quiz will be based on the following and related concepts: Do any of the predictors appear to be statistically significant? If so, which ones? Explain how each of the significant predictors influences the response variable. G. To predict whether the application will be accepted or not, convert the predicted probabilities into class labels yes with the following condition: probs >.5= "yes". Compute the confusion matrix and overall fraction of correct predictions. ( 30 points) 1.) Online Quiz will be based on the following and related questions: Explain what the confusion matrix is telling you about the types of mistakes made by logistic regression (false positive, false negative, overall correct predictions). H. Now fit the logistic regression model using a training data for observations 1 to 1000 . Compute the confusion matrix and the overall fraction of correct predictions for the test data (that is, the data for observations 1001 to end of data). ( 30 points) Some useful hints for Assignment 3 : Based on questions that I receive from students 1. Create dummy variables based on CreditCard (original) data. cbind() the dummy variables with CreditCard (original) data. You can give another name if you like. (DO NOT cbind) only the variables, that will create a matrix and not a dataframe) 2. Generate the summary () using the data created in step 1: Part A 3. Create CreditCard_Adults for age >18 based on the data created in step 1 (make sure it is a dataframe): Part B. Try: CreditCard_Adults = subset(CreditCardData, Age >18 ) \# There are many other ways you can create this CreditCard_Adults. 4. Attach the CreditCard_Adults to Renvironment. 5. For all the following steps (C-H) use CreditCard_Adults. (this should be a data frame. check class(CreditCard_Adults) to see the type of object) 6. Always use the function length() to check the length a vector and use dim() to check the length of dataframe. 7. Use log( share) and log( reports +1) in all the regression. 1. Create train and test data set using the hint below: train=CreditCard_Adults[1:1000,] test=CreditCard_Adults[1001:nrow(CreditCard_Adults),] 2. Fit the logistic model on the train data using the glm() function. 3. Compute model accuracy (similar to what you did in part G ) but on test data. 4. Use test data in the predict() function to predict the card acceptance probability on the test observations on the basis of the predicted model in step 2 in the hint above. 5. To predict whether a card will be accepted (yeso), convert the predicted probabilities into class labels "yes" or "no" on the test data. Remember glm.pred_test=rep("no"??) \#\# here ?? should be number of rows in the test data 6. Compute the accuracy of the model on the test observations based on predicted (yeso) and actual (yeso) of card acceptance finally For table () and mean(): use gim.pred_test and test.card (the response variable for the test data) \#\# check the length of both to make sure that they match and equal to the number of rows in test data set. card: was the application for a card accepted? (Binary: 1/0 ) Response Variable The question states following: "Use variables 2 to 8 (as listed above) to determine which of the predictors influence the probability that an application is accepted." Note: The order of variables are in the question (as follows) and not in the data set: 2. reports: Number of major derogatory reports 3. income: Yearly income (in USD 10,000) 4. Age: Age in years plus 12 ths of a year 5. Owner: Does the individual own his/her home? 6. dependents: number of dependents 7. months: Months living at current address 8. share: ratio of monthly credit card expenditure to yearly income In Homework 3, you will see how we can use Classification Model - Logistic Regression to predict credit risk measured by credit default rate based on customer's' credit history and other attributes. Work cooperatively to the following tasks in your groups, making sure to divide work evenly and document who contributed what. Note: Quiz 3B in iCollege will be based on this Assignment. Please have your R program available in running condition when you take the quiz. You will need solutions of your program to take the quiz. Quiz 3B is not under lock down browser