

Question: Execution Steps of Building the Inverted Index is shown as below: September 11, 2019 Execution Steps to Build Inverted Index Count by Term, Doc
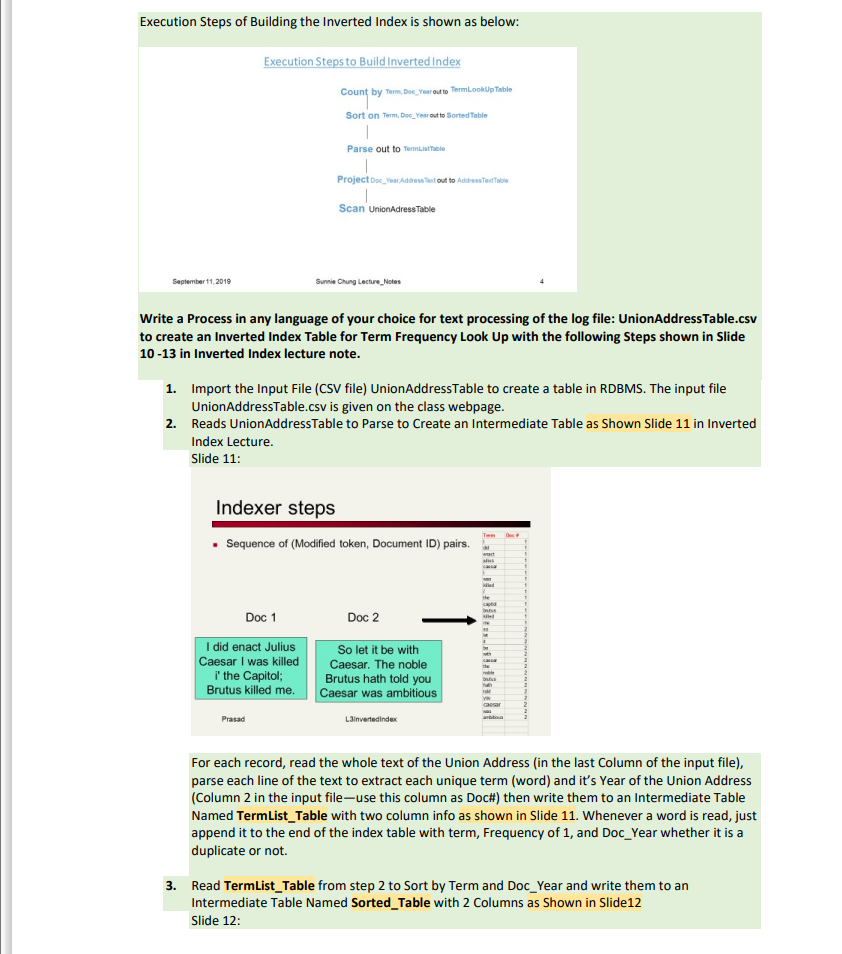

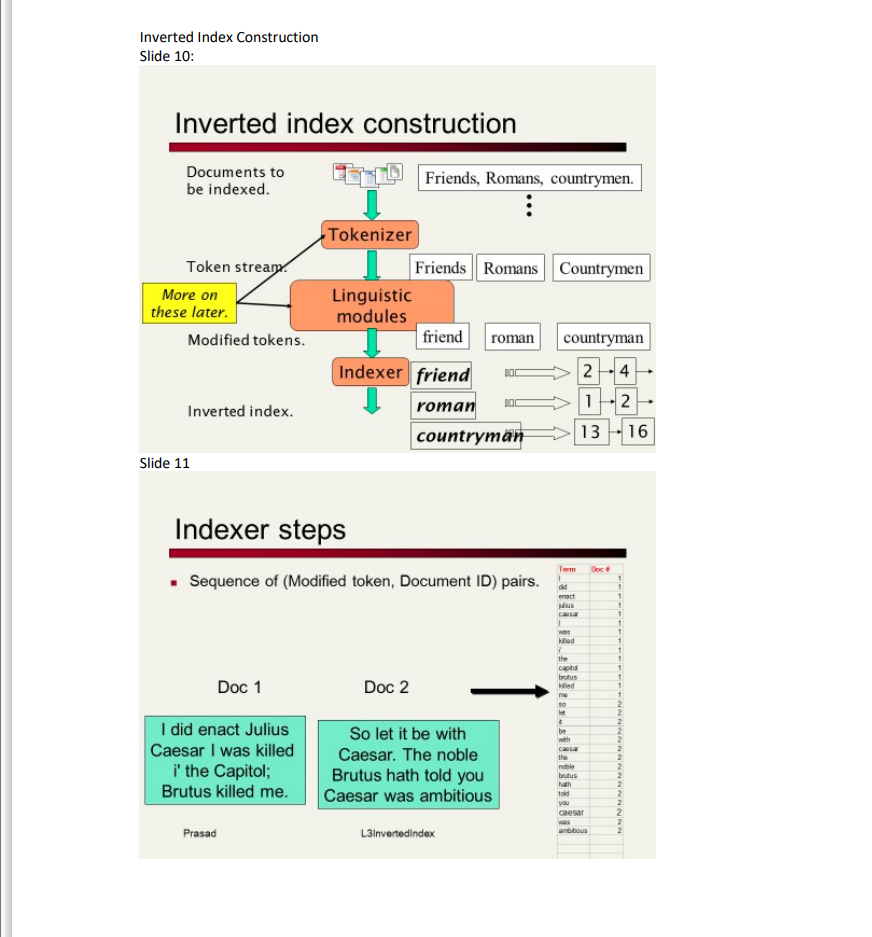

Execution Steps of Building the Inverted Index is shown as below: September 11, 2019 Execution Steps to Build Inverted Index Count by Term, Doc Year out to TermLook Up Table Sort on Term, Doc_Year out to Sorted Table I Parse out to TermListTable Project Dec Year Address Text out to Address Text Table T Scan UnionAdressTable Write a Process in any language of your choice for text processing of the log file: UnionAddress Table.csv to create an Inverted Index Table for Term Frequency Look Up with the following Steps shown in Slide 10-13 in Inverted Index lecture note. Doc 1 I did enact Julius Caesar I was killed i' the Capitol; Brutus killed me. Prasad Sunnie Chung Lecture Notes 1. Import the Input File (CSV file) Union Address Table to create a table in RDBMS. The input file UnionAddressTable.csv is given on the class webpage. 2. Reads UnionAddress Table to Parse to Create an Intermediate Table as Shown Slide 11 in Inverted Index Lecture. Slide 11: Indexer steps Sequence of (Modified token, Document ID) pairs. Doc 2 So let it be with Caesar. The noble Brutus hath told you Caesar was ambitious L3invertedIndex Tem M act Mu Carca kidlad the caped bus kled bl bus han 1 2 2 For each record, read the whole text of the Union Address (in the last Column of the input file), parse each line of the text to extract each unique term (word) and it's Year of the Union Address (Column 2 in the input file-use this column as Doc#) then write them to an Intermediate Table Named TermList_Table with two column info as shown in Slide 11. Whenever a word is read, just append it to the end of the index table with term, Frequency of 1, and Doc_Year whether it is a duplicate or not. 3. Read TermList_Table from step 2 to Sort by Term and Doc_Year and write them to an Intermediate Table Named Sorted_Table with 2 Columns as shown in Slide12 Slide 12: Sort by terms. Core indexing step. Prasad Multiple term entries in a single document are merged. Frequency information is added. Why frequency? Will discuss later. Term Dec about buks buls capitol cansar casar de eact heth 1 1 T L Jus ded kad k me rable 14 old you was was with 2 1 Tem 2 1 dd enact js 1 was R led The capito brutus killed mo 10 M E be with The noble brutus hold you casa ambitious Doc # 1 1 1 1 1 L3Inverted index 4. Read the Sorted_Table from Step3 to Aggregate the Frequency by Term and Doc_Year to Write to an Index Table TermLookUpTable with its Frequency (Word Count) as shown in Slide 13 with: TermLookUpTable (Term, Doc_Year, Term_Freq) Slide 13: 1 1 1 1 1 2 2 2 2 2 2 2 2 Tomm be brutus brutus capto car dd act hath plus killed t me P rable 20 The told you Tom Do# ambitious ba brut brut captol camar camar cassar d mat was 1 1 Mad M m naba he The told you was Do 2 1 2 + 1 1 2 1 1 Termo 2 1 1 2 1 1 2 2 1 1 2 1 2 2 1 2 2 2 1 1 1 2 2 1 1 2 1 1 1 2 2 2 1 2 1 1 1 2 4 1 1 1 2 1 1 1 2 1 1 1 1 1 1 1 1 Automatic Table Creation: At the end of each step, create each intermediate table and the final Index Table named "TermLookUpTable" in your SQL Server from your output in each step with the given schema. You can write a Stored Procedure and/or Table Function for automatic table creation. Show each table content in each step in your Lab report in screenshot. For Part1, You can use (modify) any "word Count" Program (Various versions of Word Count program for text processing are available on line). You can use any program/script language to write. You don't need to use Stored Procedure with Table Function if you create the final Index Table TermLookUpTable in SQL Server from your program. Inverted Index Construction Slide 10: Inverted index construction Documents to be indexed. Token stream. More on these later. Modified tokens. Inverted index. Slide 11 Doc 1 I did enact Julius Caesar I was killed i' the Capitol; Brutus killed me. Tokenizer Prasad Linguistic modules Friends, Romans, countrymen. Friends Romans Countrymen Indexer steps Sequence of (Modified token, Document ID) pairs. Doc 2 friend roman countryman 24 1-2 13 16 Indexer friend roman countryman So let it be with Caesar. The noble Brutus hath told you Caesar was ambitious L3Inverted index Term Doc enact Mus causar 1 was killed the capto brutus killed me 50 be with the nable brutus told you caesar was ambitious 1 1 1 1 1 Slide 12: Sort by terms. Core indexing step. Prasad Slide 13: L3Inverted index Multiple term entries in a single document are merged. Frequency information is added. Why frequency? Will discuss later. Tem Doc # ambitious be brutus brutus capitol coasan caesar cansar dd enact heth 1 1 1 L Jes killed killed kt nobla 50 the the you was was with 2 2 1 2 1 1 2 2 1 1 1 1 1 1 2 1 1 1 2 1 2 2 1 2 2 2 1 2 2 Temm L did enact julus caesar I was killed 7 the capitol brutus killed ma 50 lat L be with caesar the noble brutus hath told you caesar was ambisous Doc # 1 1 1 1 1 1 1 1 1 1 1 1 1 1- 2 2 2 2 2 2 2 2 2 2 2 2 2 + Term ambitious be brutus brutus capitol caesar did hath I 7 t julius killed lat me noble SO the the told you was was with Term Doc # ambitious ba brutus brutus capitol camar caesar caesar did enact hath L L MUS killed killed let ma nobla 50 the 110 told you was was with Doc # 2 2 1 2 11 1 2 1 1 2 1 1 2 1 1 2 1 2 2 1 2 2 2 1 2 2 2 2 1 2 1 1 2 2 1 1 1 1 1 1 2 1 1 1 2 1 2 2 1 2 2 2 1 2 2 Term freq 1 1 1 1 1 2 1 1 1 2 1 1 1 2 1 1 1 1 1 1 1 1 1 1 1
Step by Step Solution
3.42 Rating (152 Votes )
There are 3 Steps involved in it
Solutions Step 1 Here I am using Python language for perform the given task Import the Input File CSV file UnionAddressTable to create a table in RDBM... View full answer

Get step-by-step solutions from verified subject matter experts