

Question
Extract Names Info Then, your task is to implement the extract_names_from_page function in the name_scraping.py file. The function has the following arguments: page_text : A
Extract Names Info
Then, your task is to implement the extract_names_from_page function in the name_scraping.py file. The function has the following arguments:
page_text: A text (str) of the HTML code of the page from the behindthename.com website, such as the one that is returned by the get_names_page function that you implemented earlier.
gender: A bool indicating if the gender information should be included in the output. By default this parameter is set to True.
usage: A bool indication if the usage information should be included in the output. By default this parameter is set to False.
desc: A bool indication if the description information should be included in the output. By default this parameter is set to False.
Given the page_text parameter corresponding to the output of the get_names_page(4) function call, the output of the extract_names_from_page(page_text, True, True, True) function call should be a dict the beginning of which looks like this:
{ 'lex': { 'gender': 'm', 'usage': ['Spanish'], 'desc': 'Short form of Alejandro.' }, 'lex': { 'gender': 'm', 'usage': ['Catalan'], 'desc': 'Catalan short form of Alexander.' }, 'Alex': { 'gender': 'm & f', 'usage': ['English', 'Dutch', 'German', 'French', 'Portuguese', 'Italian', 'Romanian', 'Greek', 'Swedish', 'Norwegian', 'Danish', 'Icelandic', 'Hungarian', 'Czech', 'Russian'], 'desc': 'Short form of Alexander, Alexandra and other names beginning with Alex.' }, ... } The (partial) output of the extract_names_from_page(page_text, False, True, False) function call should be:
{ 'lex': { 'usage': ['Spanish'] }, 'lex': { 'usage': ['Catalan'] }, 'Alex': { 'usage': ['English', 'Dutch', 'German', 'French', 'Portuguese', 'Italian', 'Romanian', 'Greek', 'Swedish', 'Norwegian', 'Danish', 'Icelandic', 'Hungarian', 'Czech', 'Russian'] }, ... } Scrape Names
Finally, your task is to implement the scrape_names function in the name_scraping.py file. The function has the following arguments:
pages: A list of integers that correspond to the pages to be scraped. For example, if the list is [1, 2, 3, 4], then the function should scrape the pages 1, 2, 3 and 4.
output_file_path: A path (str) to the file where the output should be written.
gender: A bool indicating if the gender information should be included in the output. By default this parameter is set to True.
usage: A bool indication if the usage information should be included in the output. By default this parameter is set to False.
desc: A bool indication if the description information should be included in the output. By default this parameter is set to False.
output_format: A str indicating the format of the output. The only supported formats are csv, json, and xml. By default this parameter is set to csv.
The function utilizes extract_names_from_page to obtain the data for each of the pages passing it its gender, usage, and desc parameters as provided.
In case the output_format parameter is set to csv the function should produce the CSV file with the following structure:
name,gender,usage,desc Aabraham,m,Finnish (Rare),Finnish form of Abraham. Aada,f,Finnish,Finnish form of Ada 1. Aadan,m,"Eastern African, Somali",Possibly a Somali form of Adam. Aadolf,m,Finnish (Rare),Finnish form of Adolf. ... Of course, the exact contents depend on how the other parameters are set.
In case the output_format parameter is set to json the function should produce the JSON file with the following structure:
{ "Aabraham": { "gender": "m", "usage": [ "Finnish (Rare)" ], "desc": "Finnish form of Abraham." }, "Aada": { "gender": "f", "usage": [ "Finnish" ], "desc": "Finnish form of Ada 1." }, "Aadan": { "gender": "m", "usage": [ "Eastern African", "Somali" ], "desc": "Possibly a Somali form of Adam." }, "Aadolf": { "gender": "m", "usage": [ "Finnish (Rare)" ], "desc": "Finnish form of Adolf." }, ... } Of course, the exact contents depend on how the other parameters are set.
In case the output_format parameter is set to xml the function should produce the XML file with the following structure:
m Finnish (Rare) Finnish form of Abraham. f Finnish Finnish form of Ada 1. m Eastern African Somali Possibly a Somali form of Adam. m Finnish (Rare) Finnish form of Adolf. ... Of course, the exact contents depend on how the other parameters are set.
How to Validate
Before submitting your work, please, make sure of the following:
There is the name_scraping.py file in your project directory.
The file contains the get_names_page, extract_page_count, extract_names_from_page, and scrape_names functions.
The get_names_page function returns the str of the HTML page as described in the task specification.
The extract_page_count function returns the int number of pages in the provided HTML document.
The extract_names_from_page function returns the dict of names extracted from the provided HTML document associated with the information as specified in the provided arguments.
The scrape_names function generates a CSV, JSON, or XML file meeting the requirements.
DONT USE CHATGPT! and fill in everything needed
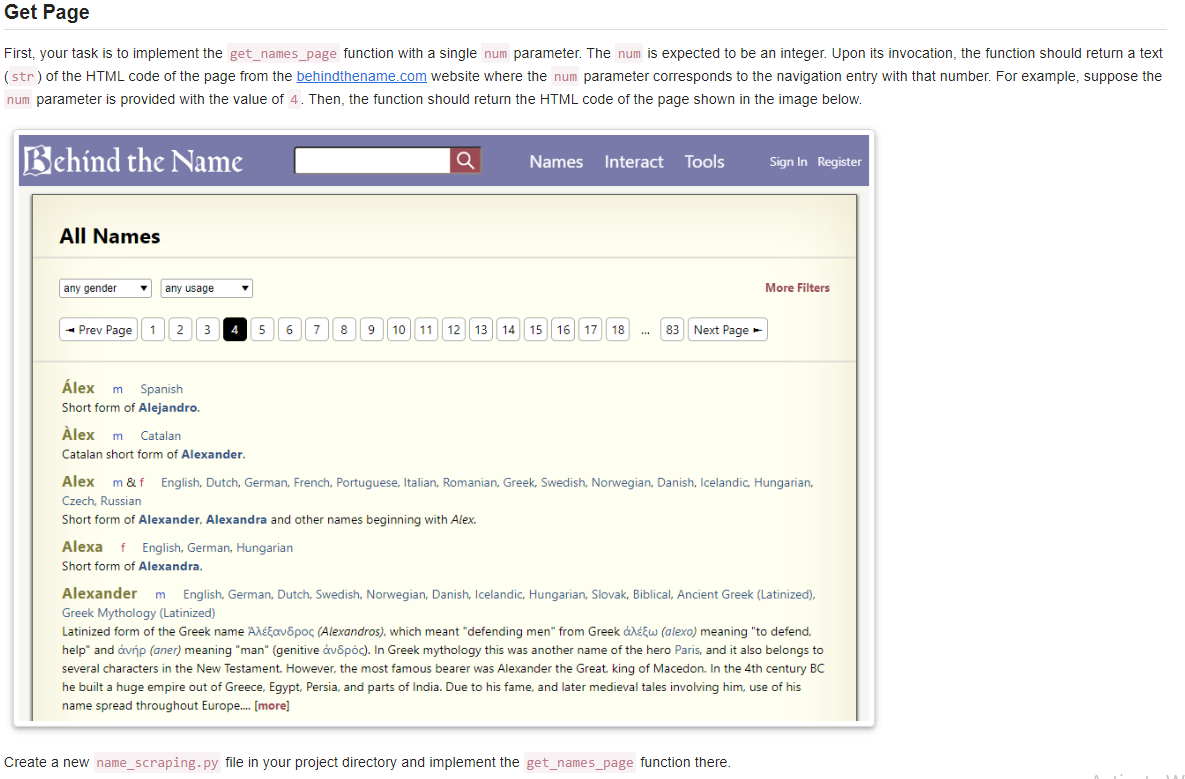
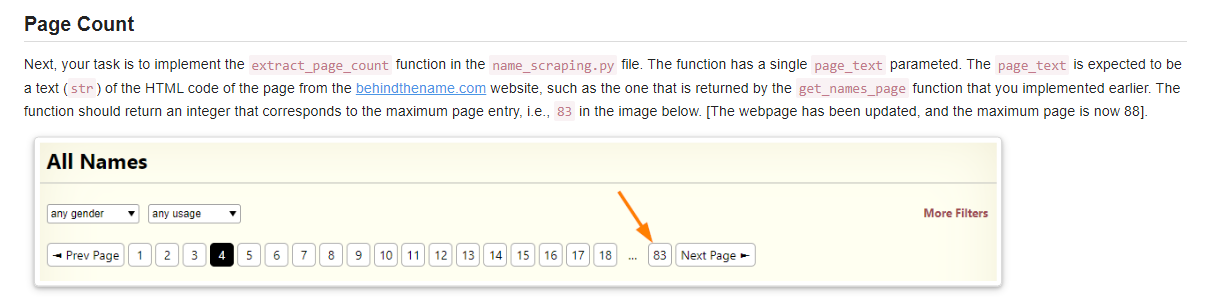
First, your task is to implement the get_names_page function with a single num parameter. The num is expected to be an integer. Upon its invocation, the function should return a text ( str) of the HTML code of the page from the website where the num parameter corresponds to the navigation entry with that number. For example, suppose the num parameter is provided with the value of 4 . Then, the function should return the HTML code of the page shown in the image below. Behind the Name Names Interact Tools Sign In Register All Names More Filters 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 83 lex m Spanish Short form of Alejandro. lex m Catalan Catalan short form of Alexander. Alex m \&f English, Dutch, German, French, Portuguese, Italian, Romanian, Greek, Swedish, Norwegian, Danish, Icelandic, Hungarian, Czech, Russian Short form of Alexander, Alexandra and other names beginning with Alex. Alexa f English, German, Hungarian Short form of Alexandra. Alexander m English, German, Dutch, Swedish, Norwegian, Danish, Icelandic, Hungarian, Slovak, Biblical, Ancient Greek (Latinized), Greek Mythology (Latinized) several characters in the New Testament. However, the most famous bearer was Alexander the Great, king of Macedon. In the 4 th century BC he built a huge empire out of Greece, Egypt, Persia, and parts of India. Due to his fame, and later medieval tales involving him, use of his name spread throughout Europe.... [more] Create a new name_scraping.py file in your project directory and implement the get_names_page function there. Next, your task is to implement the extract_page_count function in the name_scraping.py file. The function has a single page_text parameted. The page_text is expected to be a text ( str) of the HTML code of the page from the behindthename.com website, such as the one that is returned by the get_names_page function that you implemented earlier. The function should return an integer that corresponds to the maximum page entry, i.e., 83 in the image below. [The webpage has been updated, and the maximum page is now 88 ]
Step by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
Concepts Of Database Management
Authors: Joy L. Starks, Philip J. Pratt, Mary Z. Last
9th Edition
1337093424, 978-1337093422