

Answered step by step
Verified Expert Solution
Question
1 Approved Answer
For here, complete the code following the questions in the same software and kindly explain in details, no need to add materials to the question
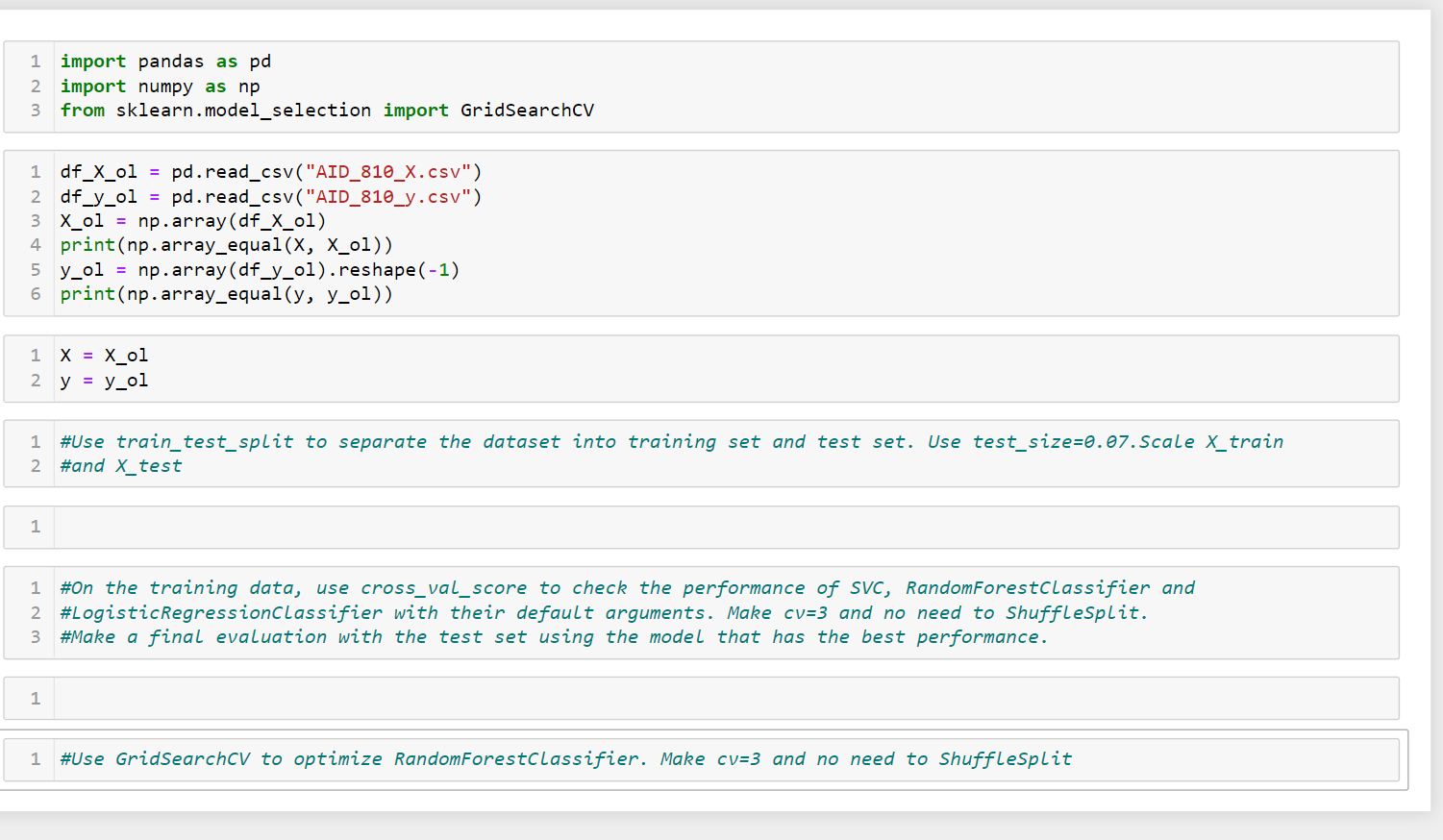
For here, complete the code following the questions in the same software and kindly explain in details, no need to add materials to the question just explain to me in details
1 import pandas as pd 2 import numpy as np 3 from sklearn.model_selection import GridSearchev 1 df_X_ol = pd.read_csv("AID_810_X.csv") 2 df_y_ol = pd.read_csv ("AID_810_y.csv") 3 X_ol = np.array(df_X_ol) 4 print(np.array_equal(X, X_ol)) 5 y_ol = np.array(df_y_ol).reshape(-1) 6 print(np.array_equal(y, y_ol)) 1 X = X_ol 2 y = y_ol 1 #Use train_test_split to separate the dataset into training set and test set. Use test_size=0.07.Scale x_train 2 #and X_test 1 1 #On the training data, use cross_val_score to check the performance of svc, RandomForestClassifier and 2 #LogisticRegressionClassifier with their default arguments. Make cv=3 and no need to ShuffleSplit. 3 #Make a final evaluation with the test set using the model that has the best performance. 1 1 #Use GridSearchcv to optimize RandomForestClassifier. Make cv=3 and no need to Shuffle SplitStep by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started