

Answered step by step
Verified Expert Solution
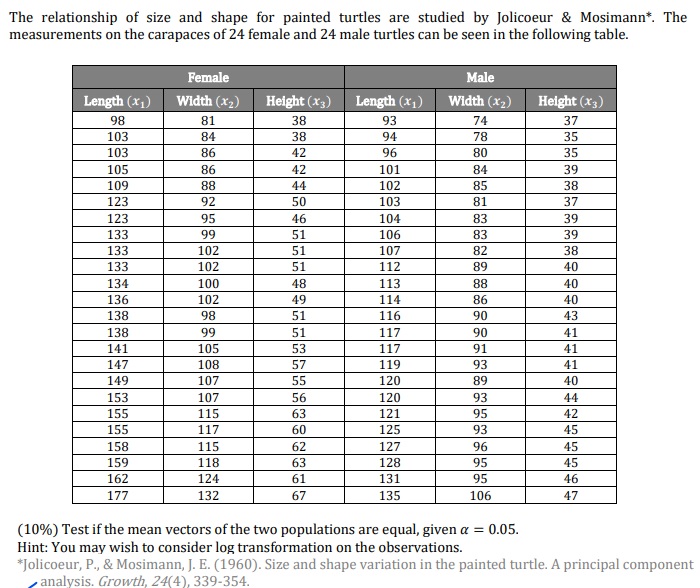
Question
1 Approved Answer
For this question, considering multivariate case, we run the code: # import package import pandas as pd import numpy as np from scipy import stats
For this question, considering "multivariate case", we run the code:
# import package
import pandas as pd
import numpy as np
from scipy import stats
# read data
Femaledata pdreadcsvrC:UsersfemalecsvheaderNone
Maledata pdreadcsvrc:UsersmalecsvheaderNone
N lenFemaledata
# log transformation
Femaledatalog nplogpFemaledata
Maledatalog nplogpMaledata
# covariance matrices
covmatrixfemale Femaledatalogcov
covmatrixmale Maledatalogcov
# number of samples in each group
nfemale lenFemaledata
nmale lenMaledata
# pooled covariance matrix
pooledcovmatrix nfemale covmatrixfemale nmale covmatrixmalenfemale nmale
# mean difference
meandiff Femaledatalogmean Maledatalogmean
# Hotelling's Tsquared statistic
tsquared npdotmeandiff.T npdotnplinalg.invpooledcovmatrix meandiffnfemale nmalenfemale nmale
# degrees of freedom
dftsquared lenFemaledata.columns
df nfemale nmale
# calculate pvalue after comparison with the Fdistribution
ptsquared stats.fcdftsquared, dfndftsquared, dfddf
printHotellings Tsquared strtsquared
printp strptsquared
# ttest for each variable
t p stats.ttestindFemaledatalog Maledatalog
printpt str p
for i in range lenp:
if pi pi:
printFemaledata.columnsi is significantly different"
else:
printFemaledata.columnsi is not significantly different"
And we get the result:
Hotelling's Tsquared
p e
pteee
which is wrong. Can you help me to correct the code and help me to explain the result? Thank you!:
Step by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
Programming The Perl DBI Database Programming With Perl
Authors: Tim Bunce, Alligator Descartes
1st Edition
1565926994, 978-1565926998