

Answered step by step
Verified Expert Solution
Question
1 Approved Answer
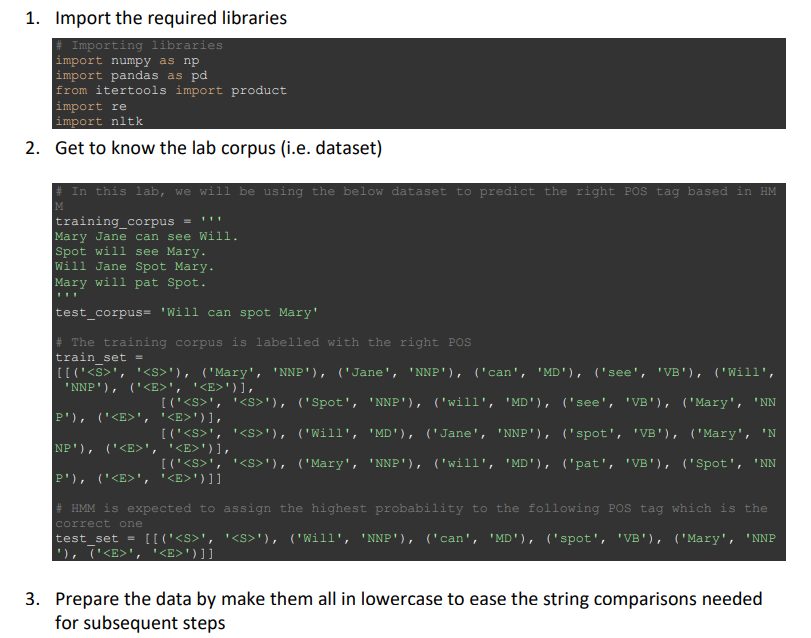
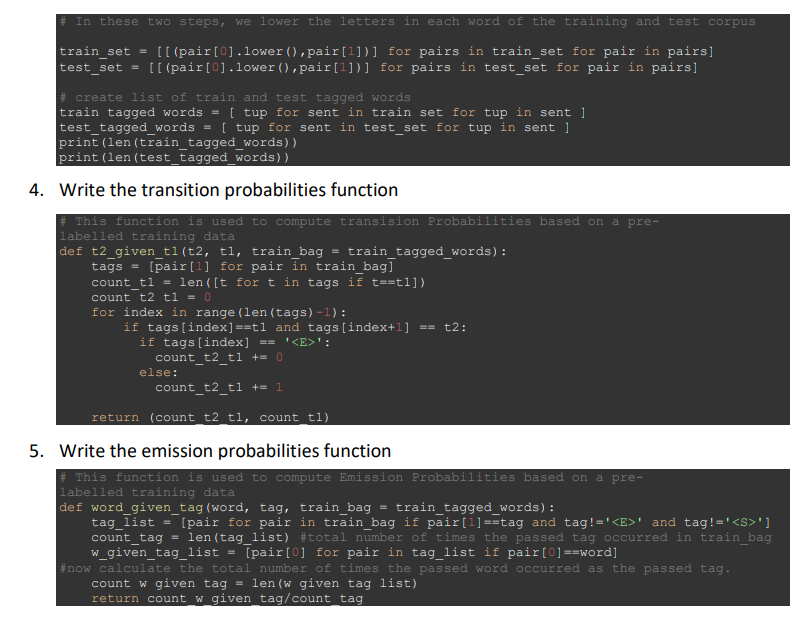
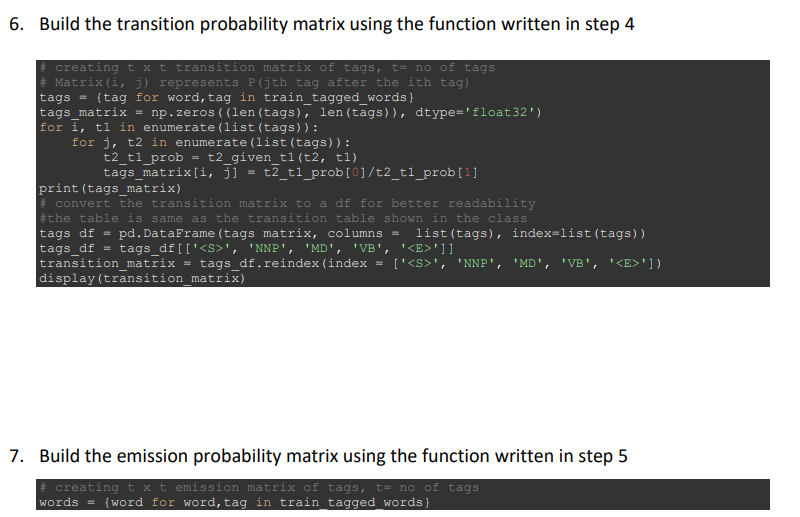
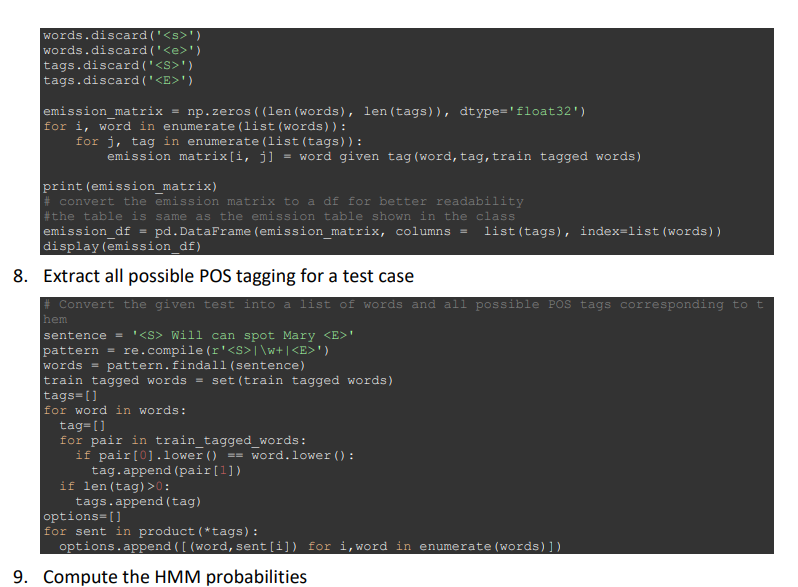
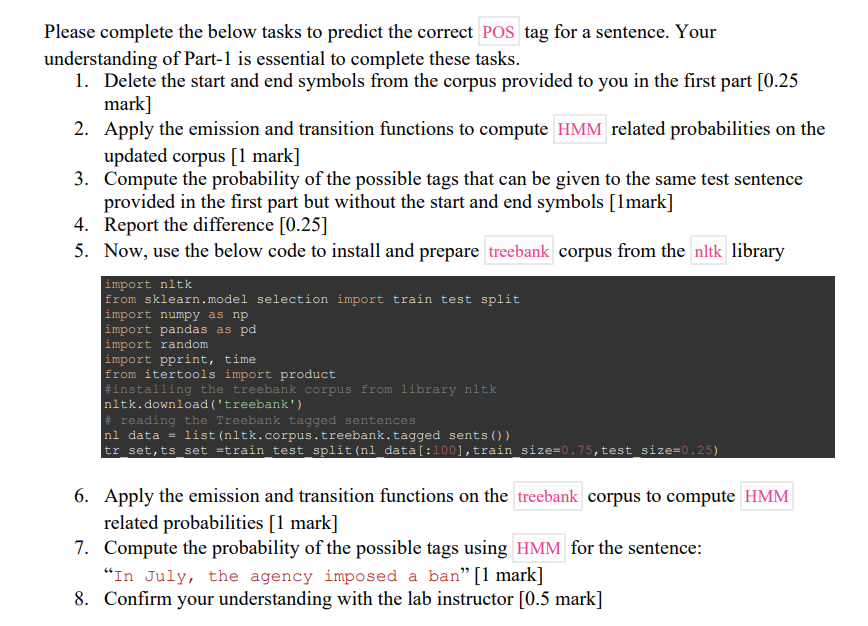
Get to know the lab corpus (i.e. dataset) Prepare the data by make them all in lowercase to ease the string comparisons needed for subsequent
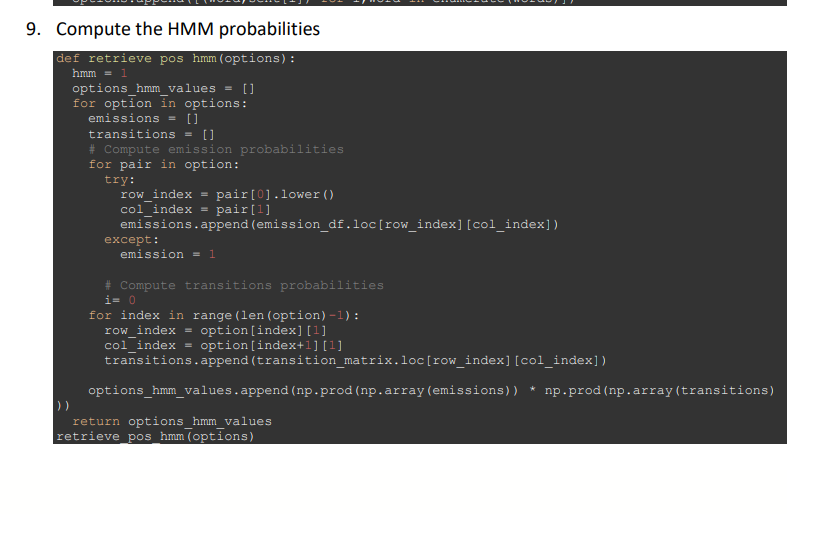
Step by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
Data Analytics With Sas Explore Your Data And Get Actionable Insights With The Power Of Sas
Authors: Nishant Sidana
1st Edition
9355515979, 978-9355515971