Hello. The Task is to write a Python code. Output should be a tuple with the Filename, index, length and peptide sequence of the longest open reading frame of the file. The File is a Fastafile, meaning it contains a DNA sequence. I prepared a piece of code which acceses/reads the file. I'll add a picture of how the inputfile looks. If you have questions please tell me. Thank you.Access code: with open(filename , "rt") as infile: for line in infile: line = line.strip() if line.startswith('>'): if buffer_sequence != "": store_sequences.append(buffer_sequence) buffer_sequence = '' else: buffer_sequence += line store_sequences.append(buffer_sequence) return store_sequences sequences = read_sequence_file("seqs.fa")#print(sequences)for seq in sequences: print(seq)
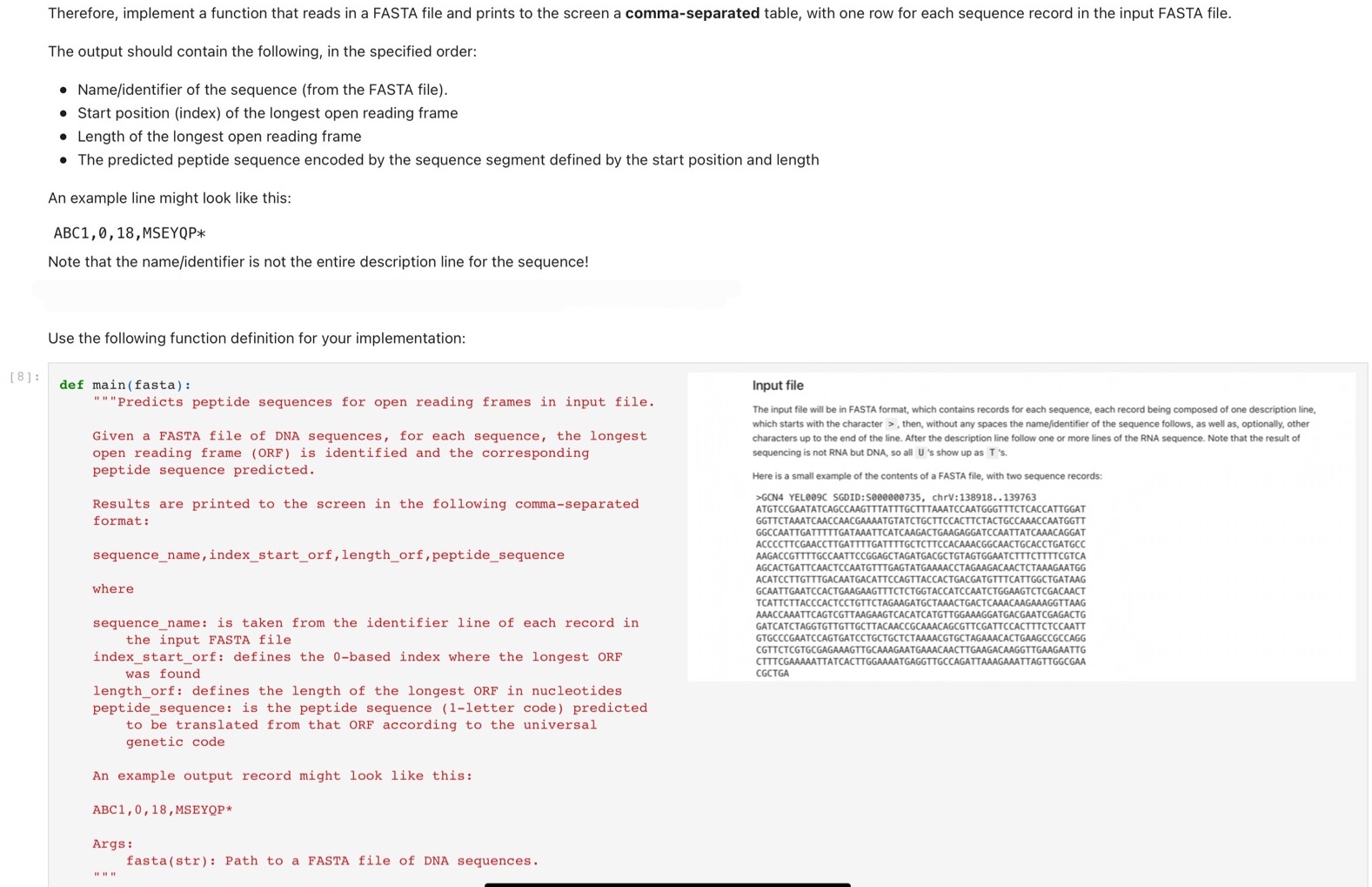
Therefore, implement a function that reads in a FASTA file and prints to the screen a comma-separated table, with one row for each sequence record in the input FASTA file. The output should contain the following, in the specified order: . Name/identifier of the sequence (from the FASTA file). . Start position (index) of the longest open reading frame . Length of the longest open reading frame The predicted peptide sequence encoded by the sequence segment defined by the start position and length An example line might look like this: ABC1, 0, 18, MSEYQP* Note that the name/identifier is not the entire description line for the sequence! Use the following function definition for your implementation: [8] : def main ( fasta) : Input file """Predicts peptide sequences for open reading frames in input file. The input file will be in FASTA format, which contains records for each sequence, each record being composed of one description line, which starts with the character > , then, without any spaces the name/identifier of the sequence follows, as well as, optionally, other Given a FASTA file of DNA sequences, for each sequence, the longest characters up to the end of the line. After the description line follow one or more lines of the RNA sequence. Note that the result of open reading frame (ORF) is identified and the corresponding sequencing is not RNA but DNA, so all U's show up as T's. peptide sequence predicted. Here is a small e tents of a FASTA file, with two se quence records: Results are printed to the screen in the following comma-separated >GCN4 YEL009C SGDID: 5000000735, chrV: 138918. .139763 ATGTCCGAATATCAGCCAAGTTTTTTGCTTTAAATCCAATGGGTTTCTCACCATTGGAT format : GGTTCTAAATCAACCAACGAAAATGTATCTGCTTCCACTTCTACTGCCAAACCAATGGTT GGCCAATTGATTTTTGATAAATTCATCAAGACTGAAGAGGATCCAATTATCAAACAGGAT ACCCCTTCGAACCTTGATTT TTTGCTCTTCCACAAACGGCAACTGCACCTGATGCC sequence_name, index_start_orf, length_orf , peptide_sequence AAGACCGTTTTGCCAATTCCGGAGCTAGATGACGCTGTAGTGGAATCTTTCTTTTCGTCA AGCACTGATTCAACTCCAATGTTTGA ACTCTAAAGAATGG ACATCCTTGTTTGACAATGACATTCCAGTTACCACTGACGATGTTTCATTGGCTGATAAG where GCAATTGAATCCACTGAAGAAGTTTCTCTGGTACCATCCAATCTGGAAGTCTCGACAACT TCATTCTTACCCACTCCTGTTCTAGAAGATGCTAAACTGACTCAAACAAGAAAGGTTAAG AAACCAAATTCAGTCGTTAAGAAGTCACATCATGTTGGAAAGGATGACGAATCGAGACTG sequence_name: is taken from the identifier line of each record in GATCATCTAGGTGTTGTTGCTTACAACCGCAAACAGCGTTCGATTCCACTTTCTCCAATT the input FASTA file GTGCCCGAATCCAGTGATCCTGCTGCTCTAAAACGTGCTAGAAACACTGAAGCCGCCAGG index_start_orf: defines the 0-based index where the longest ORF CGTTCTCGTGCGAGAAAGTTGCAAAGAATGAAACAACTTGAAGACAAGGTTGAAGAATTG CTTTCGAAAAATTATCACTTGGAAAATGAGGTTGCCAGATTAAAGAAATTAGTTGGCGAA was found CGCTGA length_orf: defines the length of the longest ORF in nucleotides peptide_sequence: is the peptide sequence (1-letter code) predicted to be translated from that ORF according to the universal genetic code An example output record might look like this: ABC1 , 0, 18 , MSEYQP* Args : fasta (str) : Path to a FASTA file of DNA sequences.\f