

Question
Here is the simplest form of my model: Like_i_j = alpha _0_0 + alpha_1_0 Polarity_i_j + U_0_j+R_i_j Like_i_j is the number of likes left for
Here is the simplest form of my model:
Like_i_j = \alpha _0_0 + \alpha_1_0 Polarity_i_j + U_0_j+R_i_j
Like_i_jis the number of likes left for tweet "i" posted by user j.Polarity_i_j is the polarity of the tweet (whether it is negative or positive). So, there are two levels of variables, one is for tweets (i) and the other one is for users (j). "\alpha _0_0 + \alpha _1_0 Polarity_i_j" is the fixed part, and "U_0_j +R_i_j" is the random part.\sigma ^2_0(= variance of R_i_j) is variability inLike_i_j at the tweet level.\tau ^2_0 (= variance of U_0_j) is variability inLike_i_j at the user level.
Now, I want to use a log-Normal hierarchical Bayesian model in "brms" package to fit the model. Here are my codes:
library(brms)
fit
My problem is that this code will give me one intercept for each user. Because I have many many users, I will have too many intercepts. For making analysis simpler and have just two parameters (mean and variance) instead of too many parameters (intercepts), I want to have a mean for all intercepts (grand mean) in my fitted model. If I use just "likes ~ 1 + polarity" as the formula rather than "likes ~ 1 + polarity + (1 | user)", would it be like a simple regression and ignore the effect of users? In overall, considering my purpose, could you please tell me whether it is the correct code in brms that I am using?
Then, I want to consider the effect of followers of each user. It would be a user-level variable like
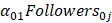
Step by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
Advanced Engineering Mathematics
Authors: ERWIN KREYSZIG
9th Edition
0471488852, 978-0471488859