

Answered step by step
Verified Expert Solution
Question
1 Approved Answer
Hi I need help with my Machine Learning assignment that requires the use of python language. The variables and labels stated in the question must
Hi I need help with my Machine Learning assignment that requires the use of python language. The variables and labels stated in the question must be strictly followed. The template python file was also provided and all the test conditions and variable and function names are stated there for reference. Please help to provide a description or explanation on what each line of the solution code is doing for my understanding. Thank you.
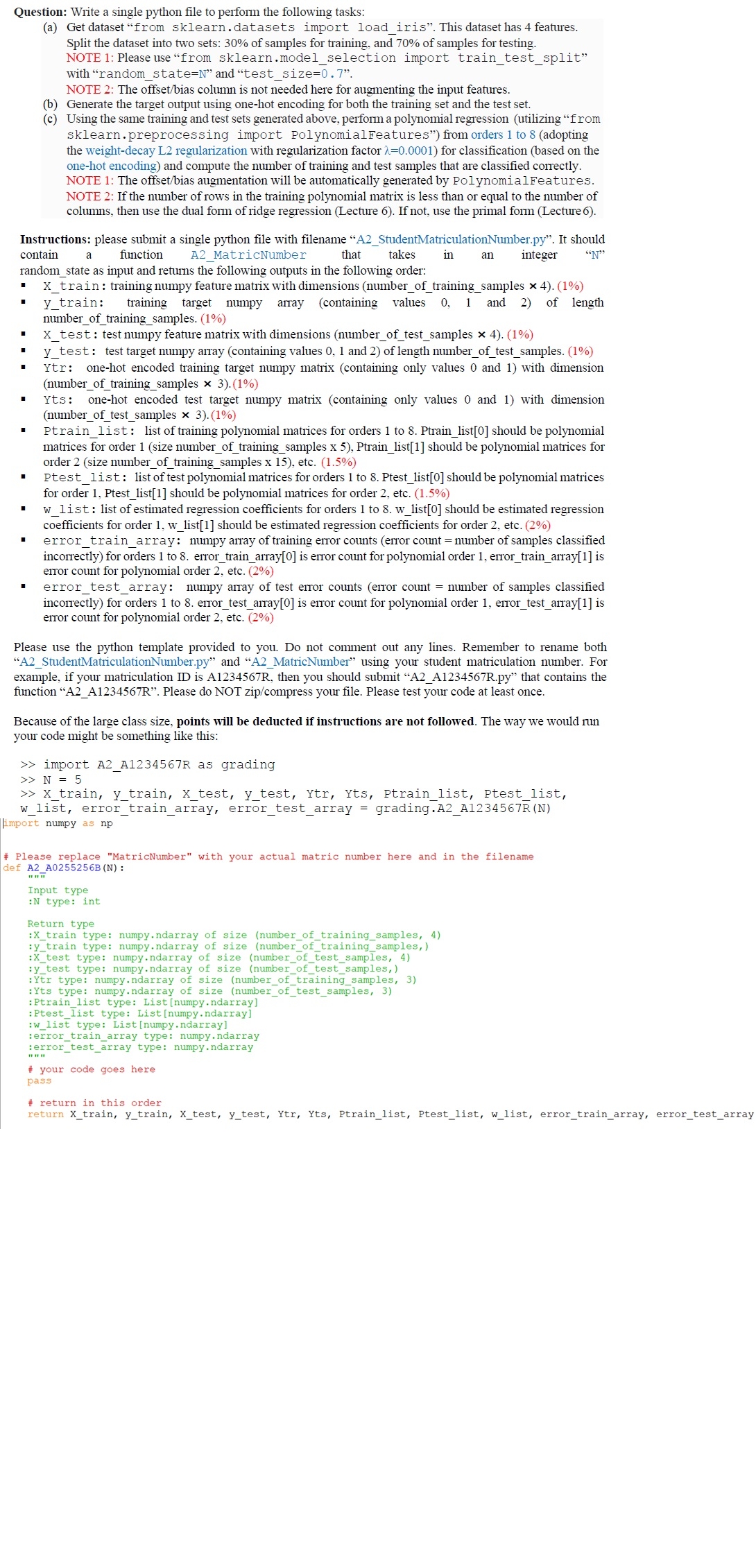
Question: Write a single python file to perform the following tasks:
a Get dataset "from sklearn.datasets import loadiris". This dataset has features.
Split the dataset into two sets: of samples for training, and of samples for testing.
NOTE : Please use "from sklearn.modelselection import traintestsplit"
with "randomstate and "testsize
NOTE : The offsetbias column is not needed here for augmenting the input features.
b Generate the target output using onehot encoding for both the training set and the test set
c Using the same training and test sets generated above, perform a polynomial regression utilizing "from
sklearn.preprocessing import PolynomialFeatures" from orders to adopting
the weightdecay L regularization with regularization factor for classification based on the
onehot encoding and compute the number of training and test samples that are classified correctly.
NOTE : The offsetbias augmentation will be automatically generated by PolynomialFeatures.
NOTE : If the number of rows in the training polynomial matrix is less than or equal to the number of
columns, then use the dual form of ridge regression Lecture If not, use the primal form Lecture
Instructions: please submit a single python file with filename AStudentMatriculationNumber.py It should
contain a function A MatricNumber that takes in an integer
randomstate as input and returns the following outputs in the following order:
train: training numpy feature matrix with dimensions numberof trainingsamples
ytrain: training target numpy array containing values and of length
numberoftrainingsamples.
xtest: test numpy feature matrix with dimensions numberoftestsamples
Ytest: test target numpy array containing values and of length numberoftestsamples.
Ytr: onehot encoded training target numpy matrix containing only values and with dimension
numberoftrainingsamples
Yts: onehot encoded test target numpy matrix containing only values and with dimension
numberoftestsamples
Ptrainlist: list of training polynomial matrices for orders to Ptrainlist should be polynomial
matrices for order size numberoftrainingsamples x Ptrainlist should be polynomial matrices for
order size numberoftrainingsamples x etc.
Ptestlist: list of test polynomial matrices for orders to Ptestlist should be polynomial matrices
for order Ptestlist should be polynomial matrices for order etc.
wlist: list of estimated regression coefficients for orders to wlist should be estimated regression
coefficients for order wlist should be estimated regression coefficients for order etc.
errortrainarray: numpy array of training error counts error count number of samples classified
incorrectly for orders to errortrainarray is error count for polynomial order errortrainarray is
error count for polynomial order etc.
errortestarray: numpy array of test error counts error count number of samples classified
incorrectly for orders to errortestarray is error count for polynomial order errortestarray is
error count for polynomial order etc.
Please use the python template provided to you. Do not comment out any lines. Remember to rename both
AStudentMatriculationNumber.py and AMatricNumber" using your student matriculation number. For
example, if your matriculation ID is AR then you should submit AARpy that contains the
function AAR Please do NOT zipcompress your file. Please test your code at least once.
Because of the large class size, points will be deducted if instructions are not followed. The way we would run
your code might be something like this: Nwlist, errortrainarray, errortestarray grading.AA barRN
limport numpy as np
# Please replace "Mat def AABN:
Input
Step by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
Database Administrator Limited Edition
Authors: Martif Way
1st Edition
B0CGG89N8Z