

Answered step by step
Verified Expert Solution
Question
1 Approved Answer
How many training instances are in the dataset? How many test instances? How many features are in the training data? What is the distribution

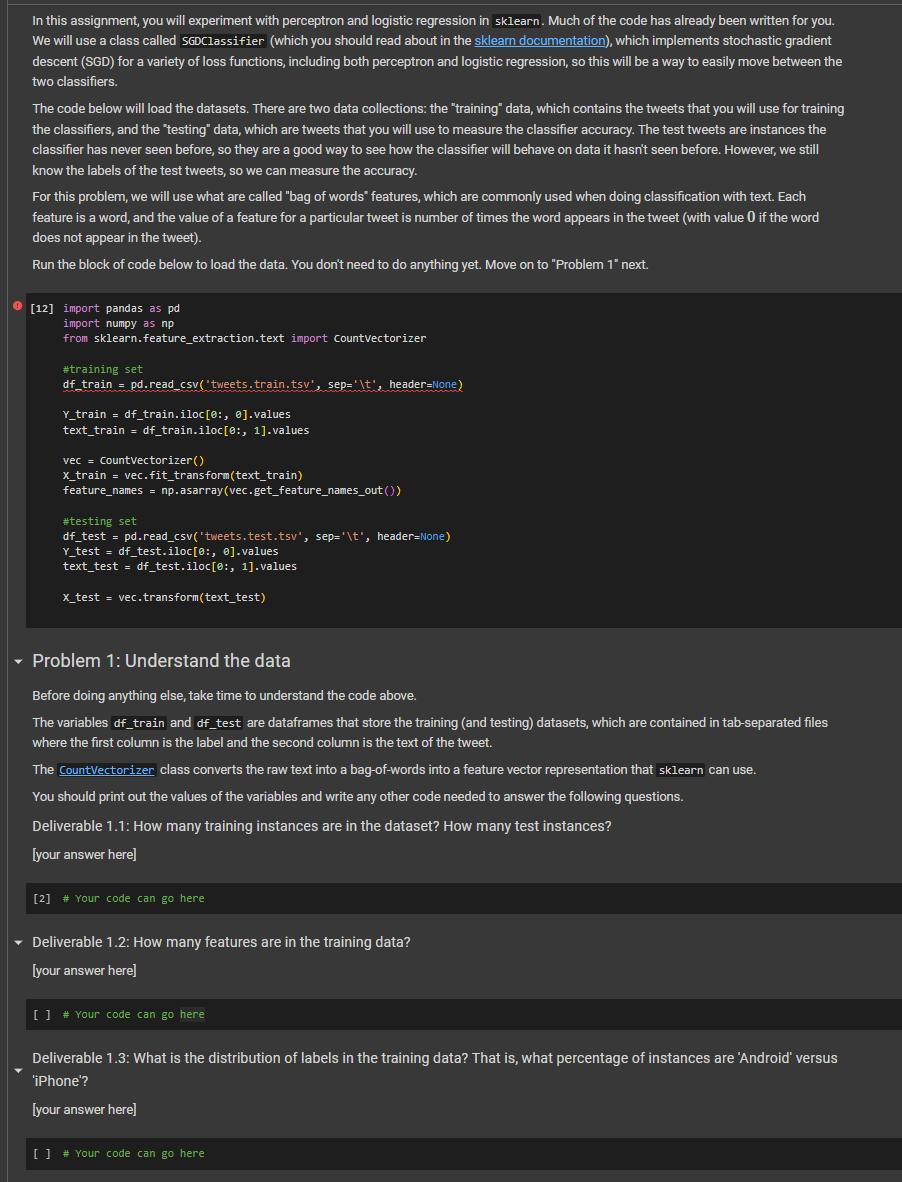
How many training instances are in the dataset? How many test instances? How many features are in the training data? What is the distribution of labels in the training data? That is, what percentage of instances are 'Android' versus 'iPhone'? Assignment overview In this assignment, you will build a classifier that tries to infer whether tweets from @realDonaldTrump were written by Trump himself or by a staff person. This is an example of binary classification on a text dataset. It is known that Donald Trump uses an Android phone, and it has been observed that some of his tweets come from Android while others come from other devices (most commonly iPhone). It is widely believed that Android tweets are written by Trump himself, while iPhone tweets are written by other staff. For more information, you can read this blog post by David Robinson, written prior to the 2016 election, which finds a number of differences in the style and timing of tweets published under these two devices. (Some tweets are written from other devices, but for simplicity the dataset for this assignment is restricted to these two.) This is a classification task known as "authorship attribution", which is the task of inferring the author of a document when the authorship is unknown. We will see how accurately this can be done with linear classifiers using word features. In this assignment, you will experiment with perceptron and logistic regression in sklearn. Much of the code has already been written for you. We will use a class called SGDClassifier (which you should read about in the sklearn documentation), which implements stochastic gradient descent (SGD) for a variety of loss functions, including both perceptron and logistic regression, so this will be a way to easily move between the two classifiers. The code below will load the datasets. There are two data collections: the "training" data, which contains the tweets that you will use for training the classifiers, and the "testing" data, which are tweets that you will use to measure the classifier accuracy. The test tweets are instances the classifier has never seen before, so they are a good way to see how the classifier will behave on data it hasn't seen before. However, we still know the labels of the test tweets, so we can measure the accuracy. For this problem, we will use what are called "bag of words" features, which are commonly used when doing classification with text. Each feature is a word, and the value of a feature for a particular tweet is number of times the word appears in the tweet (with value 0 if the word does not appear in the tweet). Run the block of code below to load the data. You don't need to do anything yet. Move on to "Problem 1" next. [12] import pandas as pd import numpy as np from sklearn.feature_extraction.text import countVectorizer #training set df_train = pd.read_csv('tweets.train.tsv', sep='\t', header=None) Y_train = df_train.iloc[0, 0].values text_train = df_train.iloc[0:, 1].values vec = CountVectorizer() x_train = vec.fit_transform(text_train) feature_names = np.asarray(vec.get_feature_names_out()) #testing set df_test = pd.read_csv('tweets.test.tsv', sep='\t', header=None) Y_test = df_test.iloc[0:, 0].values text_test = df_test.iloc[0:, 1].values x_test = vec.transform(text_test) Problem 1: Understand the data Before doing anything else, take time to understand the code above. The variables df_train and df_test are dataframes that store the training (and testing) datasets, which are contained in tab-separated files where the first column is the label and the second column is the text of the tweet. The CountVectorizer class converts the raw text into a bag-of-words into a feature vector representation that sklearn can use. You should print out the values of the variables and write any other code needed to answer the following questions. Deliverable 1.1: How many training instances are in the dataset? How many test instances? [your answer here] [2] # Your code can go here Deliverable 1.2: How many features are in the training data? [your answer here] [ ] # Your code can go here Deliverable 1.3: What is the distribution of labels in the training data? That is, what percentage of instances are 'Android' versus 'iPhone'? [your answer here] [ ] # Your code can go here
Step by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
Machine Learning For Business Analytics
Authors: Galit Shmueli, Peter C. Bruce, Amit V. Deokar, Nitin R. Patel
1st Edition
1119828791, 9781119828792