

Question
I gave the question and also the solution of lexer part 1. please help me to find the solution code of lexer part 2 Thank
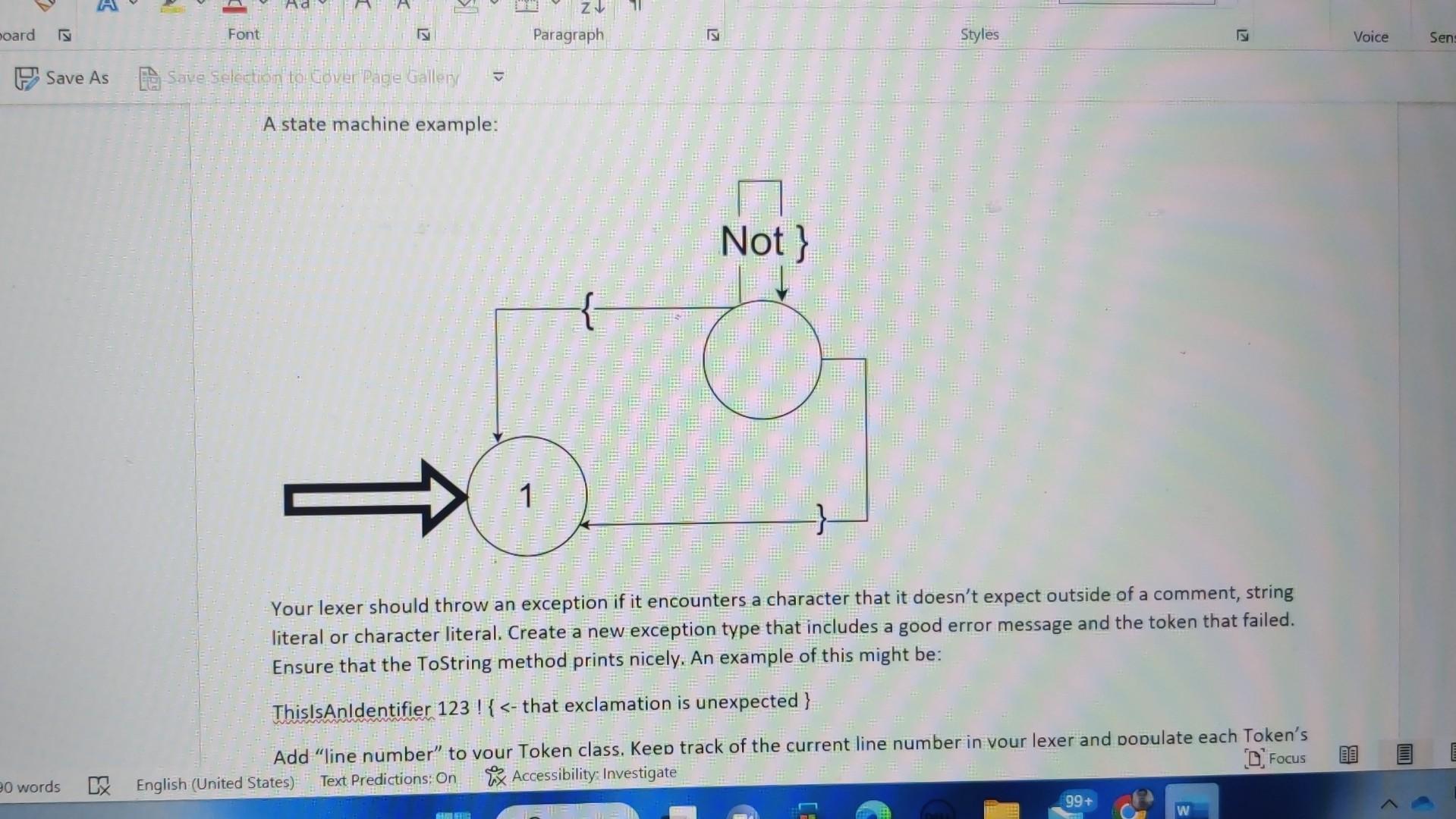
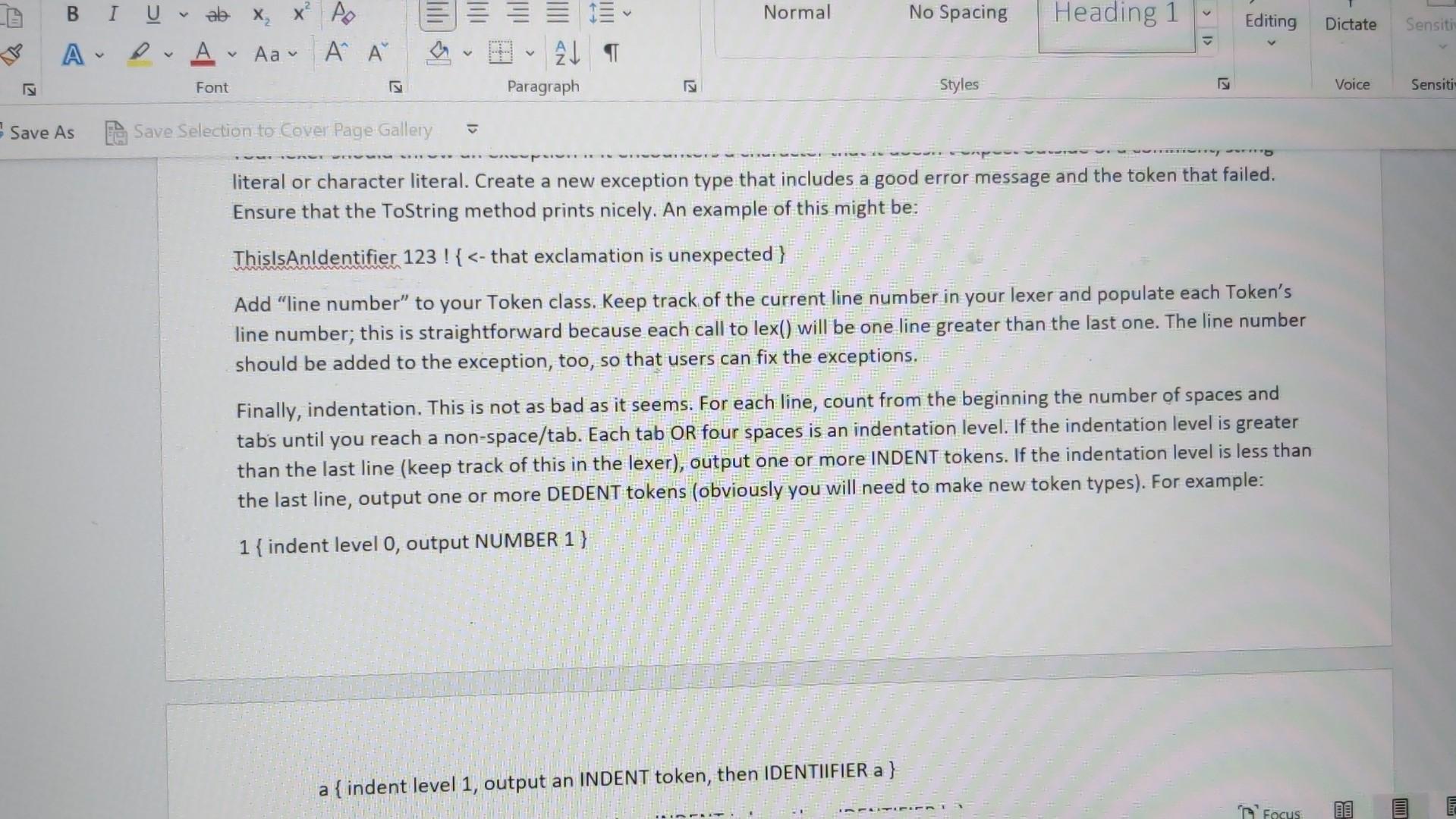
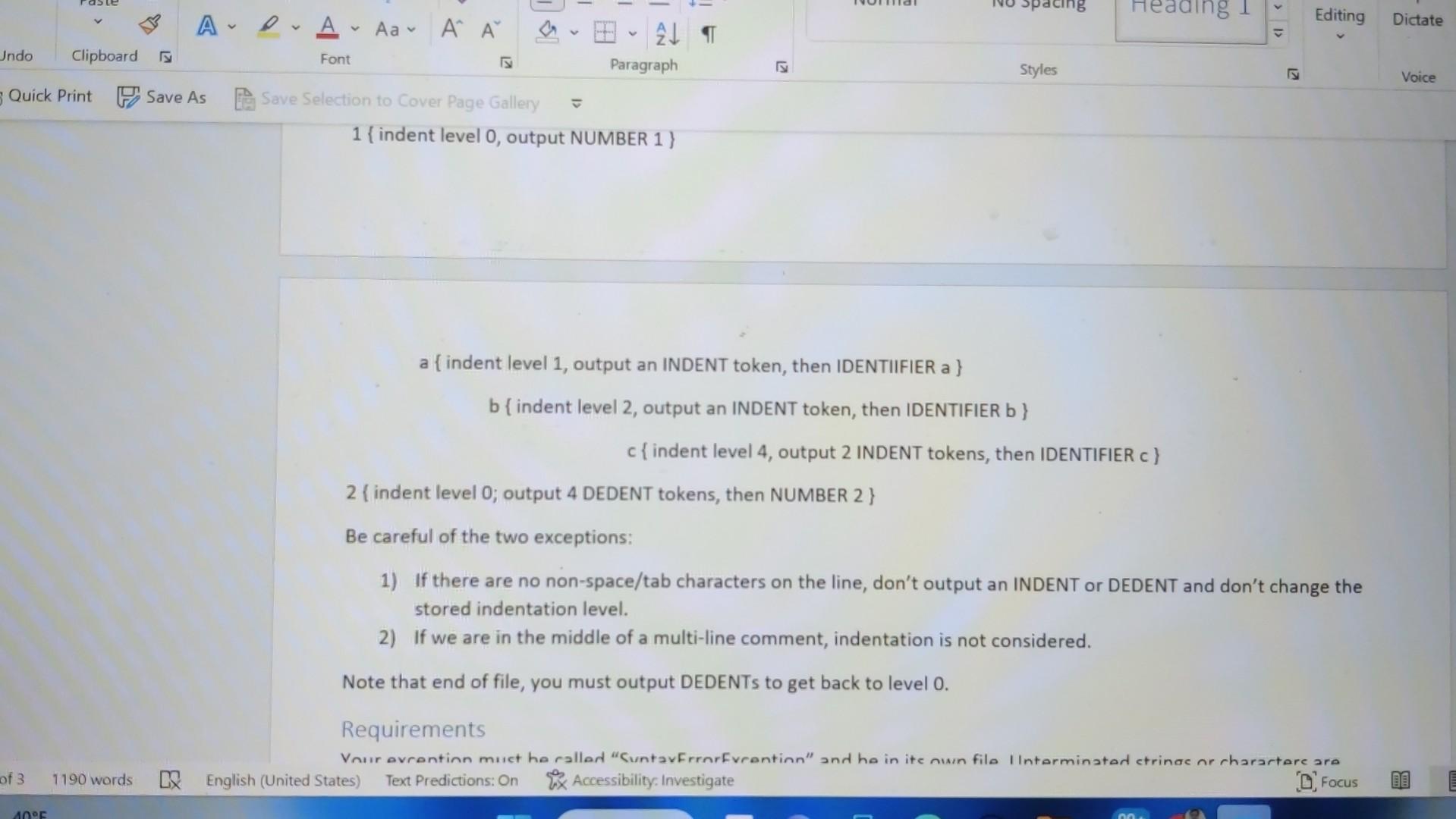
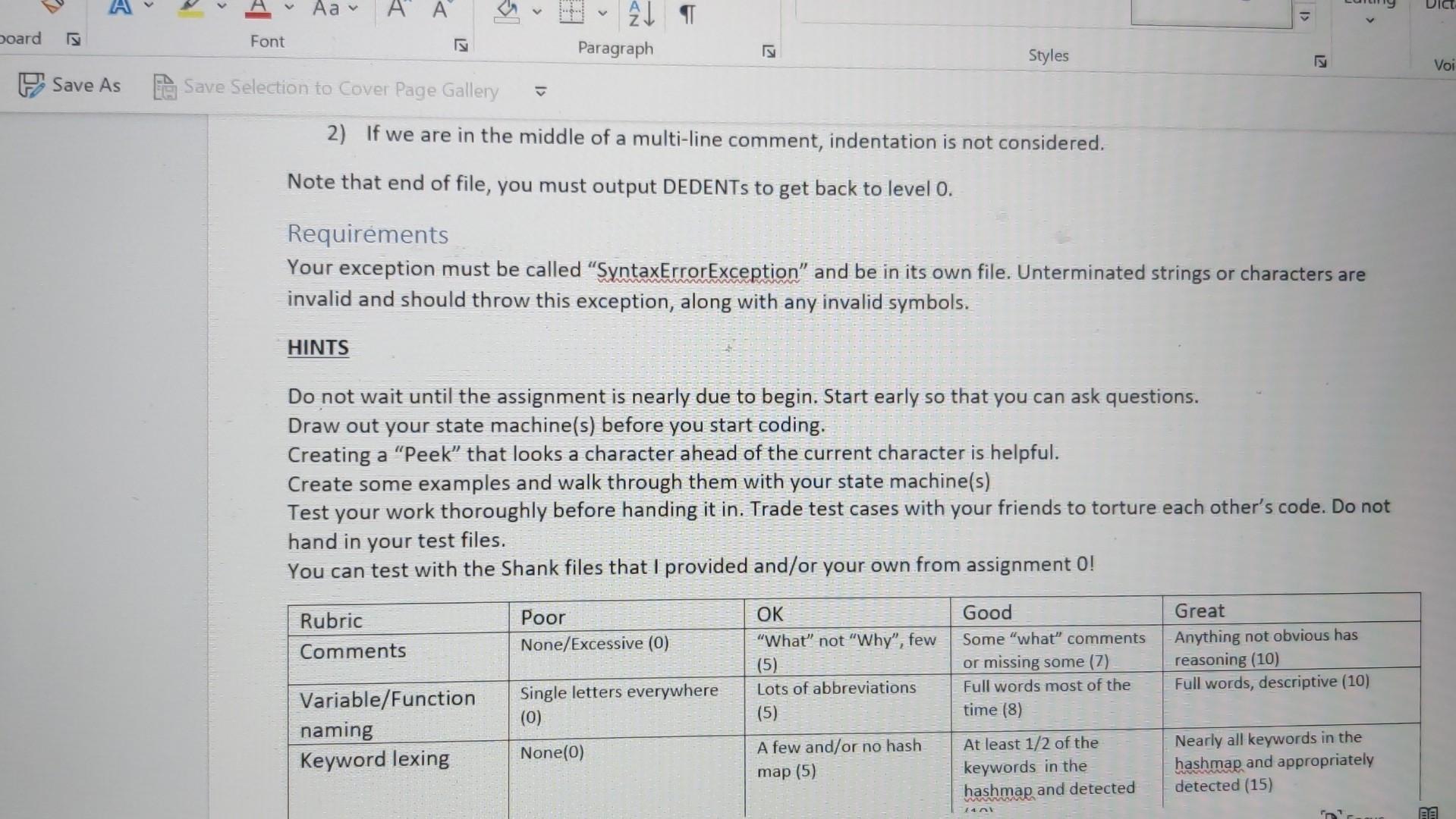





I gave the question and also the solution of lexer part 1. please help me to find the solution code of lexer part 2 Thank you
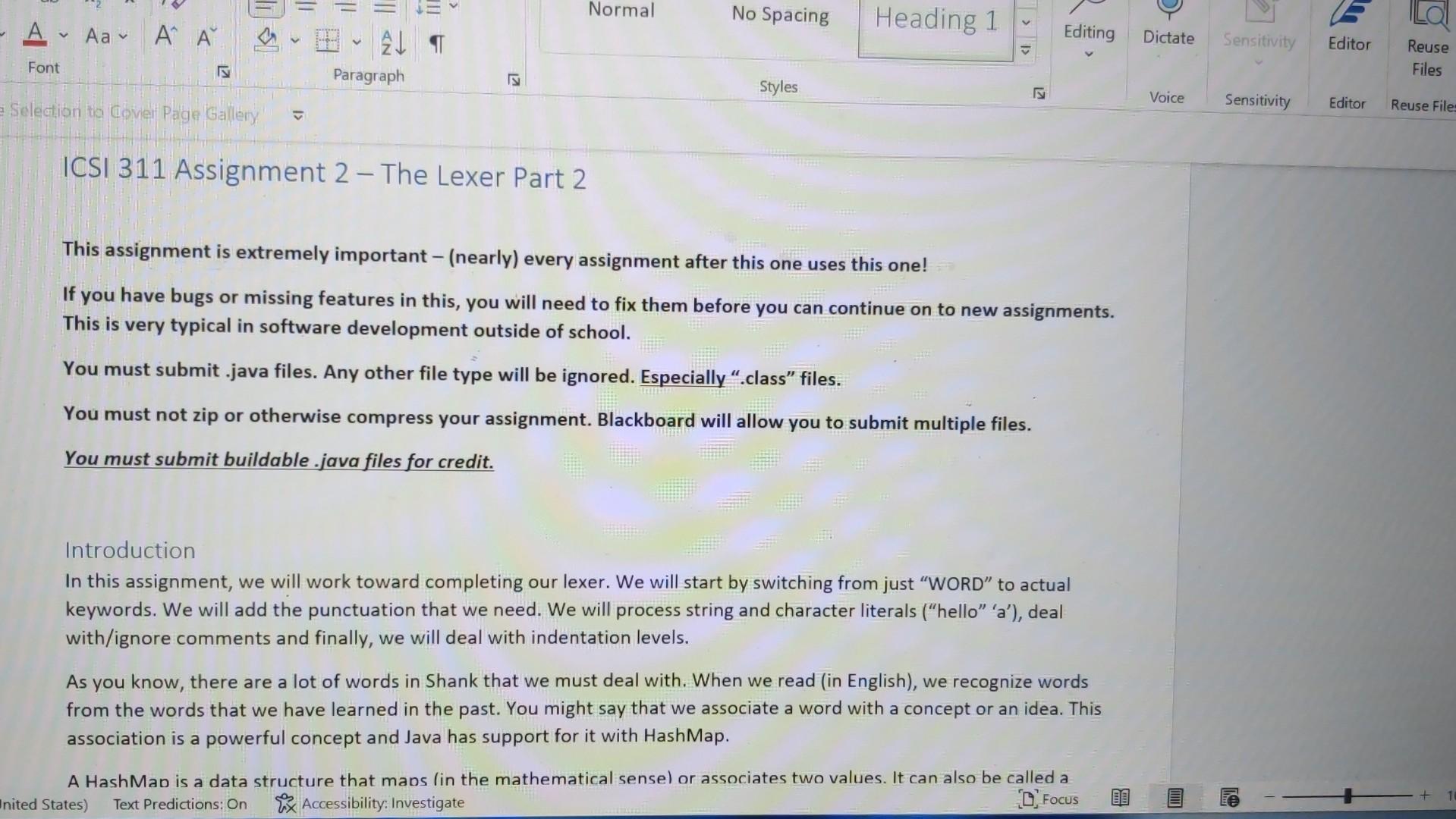
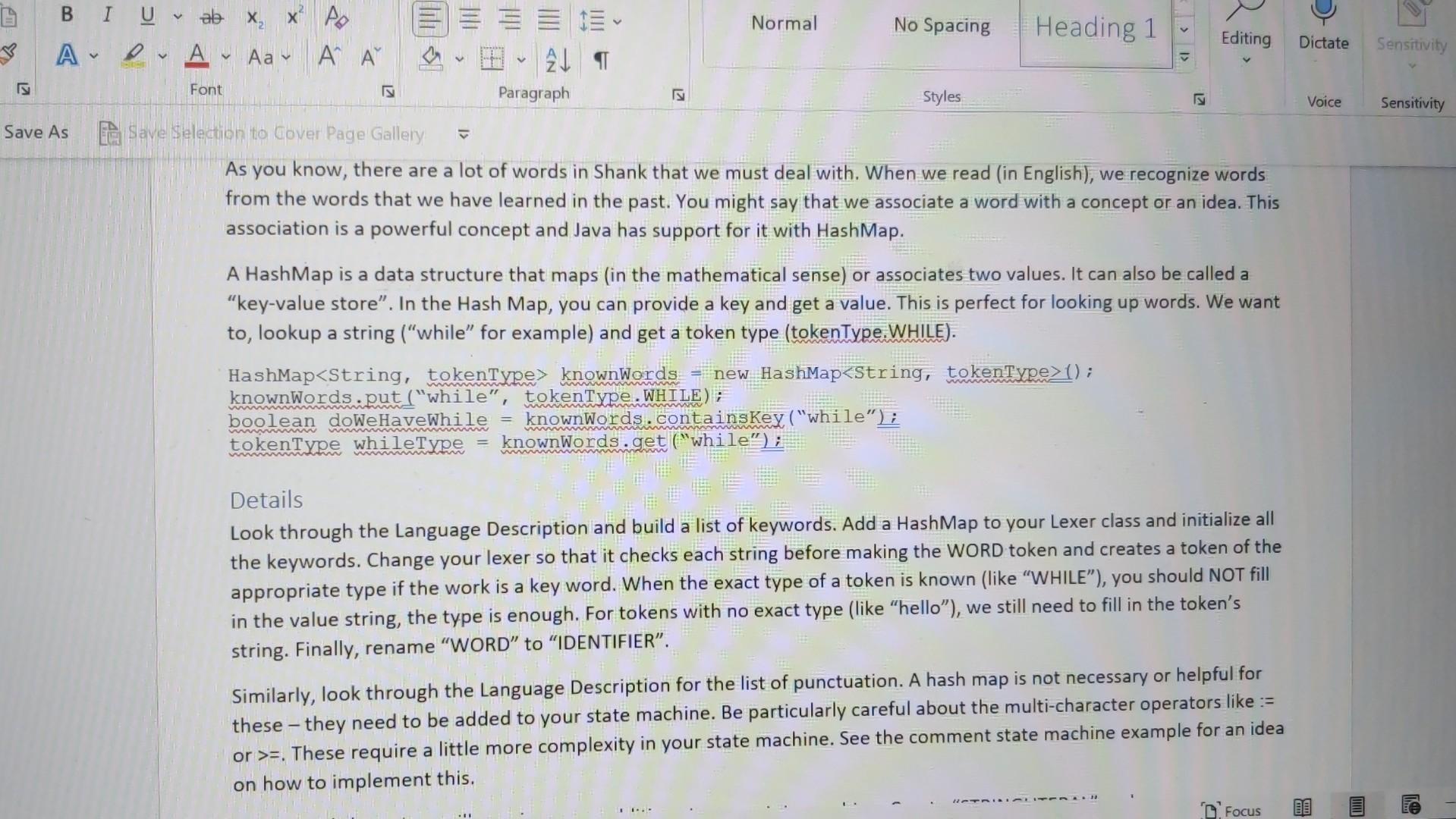
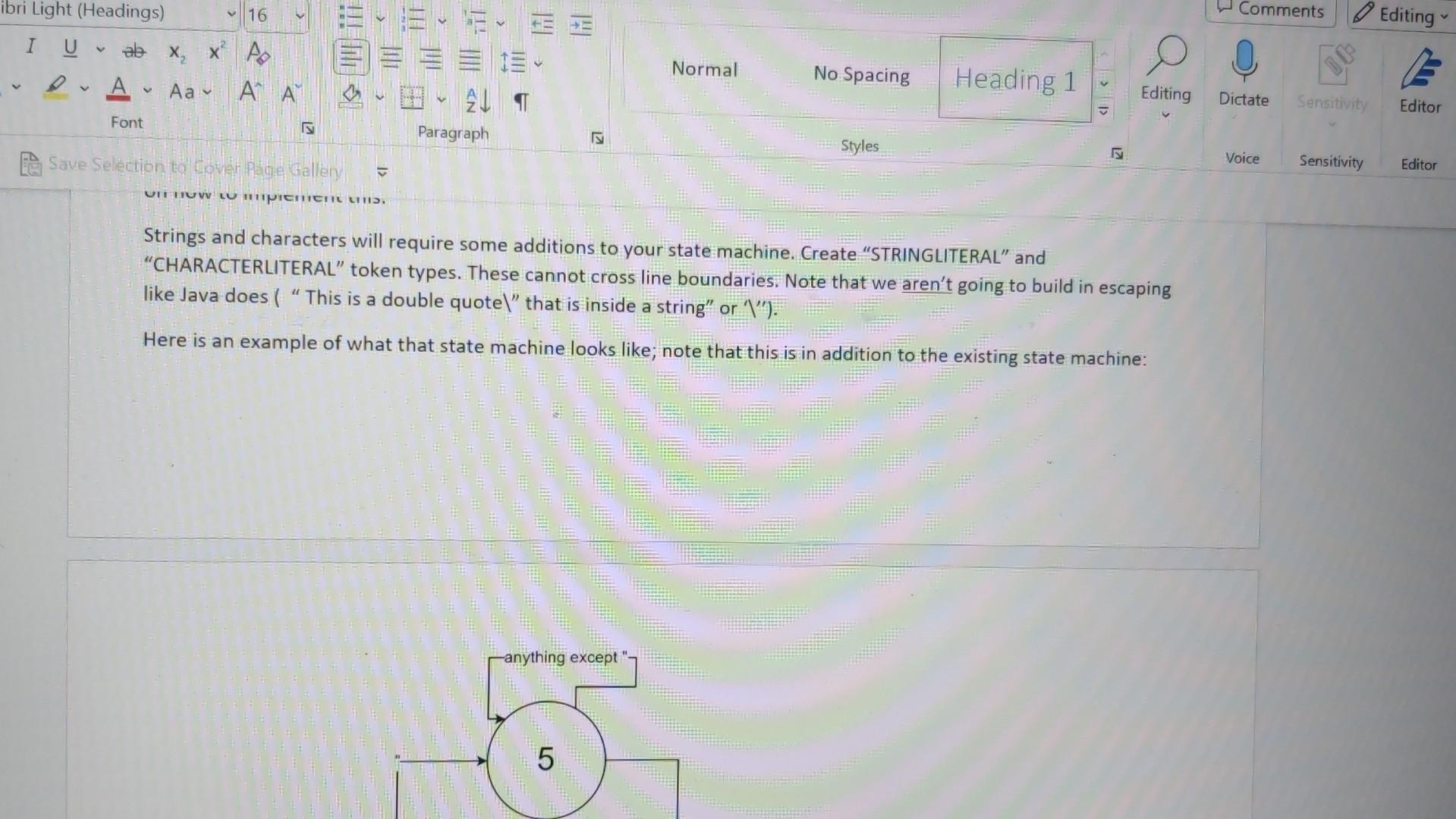
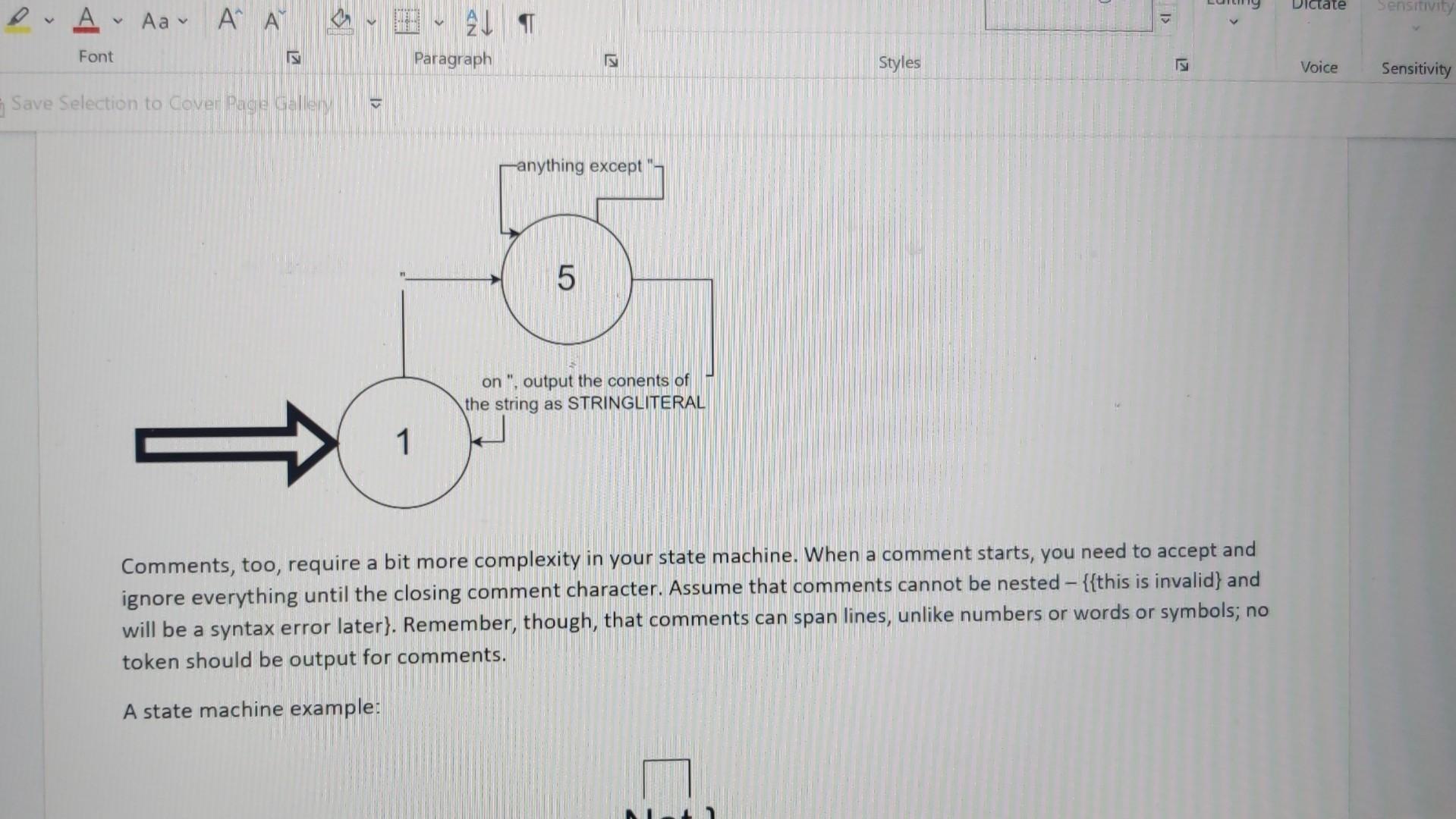
This assignment is extremely important - (nearly) every assignment after this one uses this one! If you have bugs or missing features in this, you will need to fix them before you can continue on to new assignments. This is very typical in software development outside of school. You must submit .java files. Any other file type will be ignored. Especially ".class" files. You must not zip or otherwise compress your assignment. Blackboard will allow you to submit multiple files. You must submit buildable .java files for credit. Introduction In this assignment, we will work toward completing our lexer. We will start by switching from just "WORD" to actual keywords. We will add the punctuation that we need. We will process string and character literals ("hello" 'a'), deal with/ignore comments and finally, we will deal with indentation levels. As you know, there are a lot of words in Shank that we must deal with. When we read (in English), we recognize words from the words that we have learned in the past. You might say that we associate a word with a concept or an idea. This association is a powerful concept and Java has support for it with HashMap. A HashMan is a data structure that mans lin the mathematical sensel or associates two values. It can also be called a d States) Text Predictions: On Rxx Accessibility: Investigate As you know, there are a lot of words in Shank that we must deal with. When we read (in English), we recognize words from the words that we have learned in the past. You might say that we associate a word with a concept or an idea. This association is a powerful concept and Java has support for it with HashMap. A HashMap is a data structure that maps (in the mathematical sense) or associates two values. It can also be called a "key-value store". In the Hash Map, you can provide a key and get a value. This is perfect for looking up words. We want to, lookup a string ("while" for example) and get a token type (tokenType..WHILE). HashMap> knownWords = new HashMap> ( ) ; knownWords.put ("while", tokenTxpe. WHILE); boolean doWeHaveWhile = knownWords. Containskey ("while"); tokenType whileType = knownWords.get ("while"); Details Look through the Language Description and build a list of keywords. Add a HashMap to your Lexer class and initialize all the keywords. Change your lexer so that it checks each string before making the WORD token and creates a token of the appropriate type if the work is a key word. When the exact type of a token is known (like "WHILE"), you should NOT fill in the value string, the type is enough. For tokens with no exact type (like "hello"), we still need to fill in the token's string. Finally, rename "WORD" to "IDENTIFIER". Similarly, look through the Language Description for the list of punctuation. A hash map is not necessary or helpful for these - they need to be added to your state machine. Be particularly careful about the multi-character operators like := or >=. These require a little more complexity in your state machine. See the comment state machine example for an idea on how to implement this. Strings and characters will require some additions to your state machine. Create "STRINGLITERAL" and "CHARACTERLITERAL" token types. These cannot cross line boundaries. Note that we aren't going to build in escaping like Java does ( "This is a double quotel" that is inside a string" or " \ "). Here is an example of what that state machine looks like; note that this is in addition to the existing state machine: Comments, too, require a bit more complexity in your state machine. When a comment starts, you need to accept and ignore everything until the closing comment character. Assume that comments cannot be nested - {{ this is invalid } and will be a syntax error later\}. Remember, though, that comments can span lines, unlike numbers or words or symbols; no token should be output for comments. A state machine example: A state machine example: Your lexer should throw an exception if it encounters a character that it doesn't expect outside of a comment, string literal or character literal. Create a new exception type that includes a good error message and the token that failed. Ensure that the ToString method prints nicely. An example of this might be: ThislsAnldentifier 123!{ lines = Files.readAllLines(Paths.get(filename Lexer lexer = new Lexer () ; for (String line : lines) \{ try \{ lexer.lex(line); \} catch (Exception e) \{ System.out.println("Exception: " + e.getMessage()); \} \} List lines = Files.readAllLines(Paths.get(filename Lexer lexer = new Lexer () ; for (String line : lines) \{ try \{ lexer.lex(line); \} catch (Exception e) \{ System.out.println("Exception: " + e.getMessage()); \} \} for (Token token : lexer.getTokens ()){ System.out.println(token.toString()); \} \} catch (IOException e) \{ System.out.println("Error: " + e.getMessage()); System.exit(1); \} \} \} Token.java public class Token \{ private enum TokenType \{ WORD, NUMBER, SYMBOL \} private TokenType tokenType; private String value; public Token(TokenType tokenType, String value) \{ this.tokenType = tokenType; this.value = value; \} public TokenType getTokenType() \{ return tokenType; \} public String getValue() \{ return value; \} @Override public String toString() \{ return tokenType + ": " + value; \} \} Explanation Lexer.javaimport java.util.ArrayList; import java.util.List; public class Lexer \{ private List tokens; public Lexer() \{ tokens = new ArrayList (); \} public void lex(String line) throws Exception \{ int i=0; while (i = new StringBuilder(); while ( i = new StringBuilder(); while ( i knownWords = new HashMap> ( ) ; knownWords.put ("while", tokenTxpe. WHILE); boolean doWeHaveWhile = knownWords. Containskey ("while"); tokenType whileType = knownWords.get ("while"); Details Look through the Language Description and build a list of keywords. Add a HashMap to your Lexer class and initialize all the keywords. Change your lexer so that it checks each string before making the WORD token and creates a token of the appropriate type if the work is a key word. When the exact type of a token is known (like "WHILE"), you should NOT fill in the value string, the type is enough. For tokens with no exact type (like "hello"), we still need to fill in the token's string. Finally, rename "WORD" to "IDENTIFIER". Similarly, look through the Language Description for the list of punctuation. A hash map is not necessary or helpful for these - they need to be added to your state machine. Be particularly careful about the multi-character operators like := or >=. These require a little more complexity in your state machine. See the comment state machine example for an idea on how to implement this. Strings and characters will require some additions to your state machine. Create "STRINGLITERAL" and "CHARACTERLITERAL" token types. These cannot cross line boundaries. Note that we aren't going to build in escaping like Java does ( "This is a double quotel" that is inside a string" or " \ "). Here is an example of what that state machine looks like; note that this is in addition to the existing state machine: Comments, too, require a bit more complexity in your state machine. When a comment starts, you need to accept and ignore everything until the closing comment character. Assume that comments cannot be nested - {{ this is invalid } and will be a syntax error later\}. Remember, though, that comments can span lines, unlike numbers or words or symbols; no token should be output for comments. A state machine example: A state machine example: Your lexer should throw an exception if it encounters a character that it doesn't expect outside of a comment, string literal or character literal. Create a new exception type that includes a good error message and the token that failed. Ensure that the ToString method prints nicely. An example of this might be: ThislsAnldentifier 123!{ lines = Files.readAllLines(Paths.get(filename Lexer lexer = new Lexer () ; for (String line : lines) \{ try \{ lexer.lex(line); \} catch (Exception e) \{ System.out.println("Exception: " + e.getMessage()); \} \} List lines = Files.readAllLines(Paths.get(filename Lexer lexer = new Lexer () ; for (String line : lines) \{ try \{ lexer.lex(line); \} catch (Exception e) \{ System.out.println("Exception: " + e.getMessage()); \} \} for (Token token : lexer.getTokens ()){ System.out.println(token.toString()); \} \} catch (IOException e) \{ System.out.println("Error: " + e.getMessage()); System.exit(1); \} \} \} Token.java public class Token \{ private enum TokenType \{ WORD, NUMBER, SYMBOL \} private TokenType tokenType; private String value; public Token(TokenType tokenType, String value) \{ this.tokenType = tokenType; this.value = value; \} public TokenType getTokenType() \{ return tokenType; \} public String getValue() \{ return value; \} @Override public String toString() \{ return tokenType + ": " + value; \} \} Explanation Lexer.javaimport java.util.ArrayList; import java.util.List; public class Lexer \{ private List tokens; public Lexer() \{ tokens = new ArrayList (); \} public void lex(String line) throws Exception \{ int i=0; while (i = new StringBuilder(); while ( i = new StringBuilder(); while ( iStep by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
Transactions On Large Scale Data And Knowledge Centered Systems Vi Special Issue On Database And Expert Systems Applications Lncs 7600
Authors: Abdelkader Hameurlain ,Josef Kung ,Roland Wagner ,Stephen W. Liddle ,Klaus-Dieter Schewe ,Xiaofang Zhou
2012th Edition
3642341780, 978-3642341786