I HAVE COMPLETED THE FIRST MODIFICATION PLEASE HELP ON THE REST. THANK YOU!



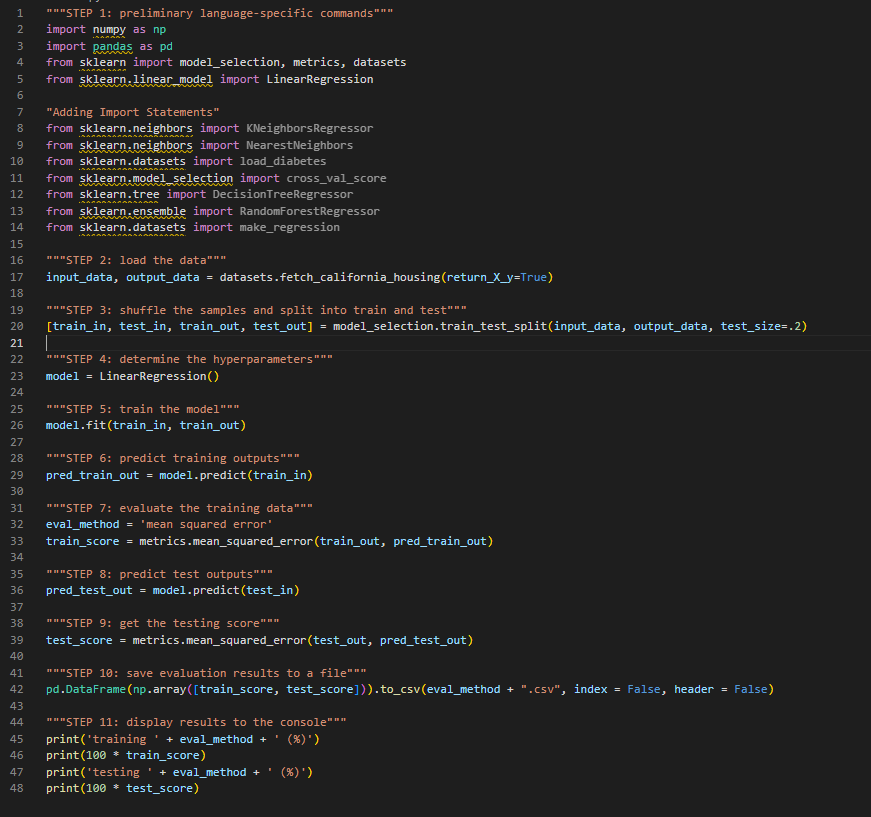
In this assignment, you will be modifying the Python script to explore some of the regression algorithms that we have learned in class so far. So far, we have been using linear regression as the ML technique of choice. Here, we will be adding k-nearest neighbors (KNN), decision trees and random forests Modifications: For this assignment, you will make three main changes to the program. First, you will need to modify Step 1 to add import statements for KNN, Decision Trees and Random Forest. To do so, see the documentation in the links above (specifically, the example on each page) as well as the syntax of the existing import statement for linear regression. Next, you will modify Step 4 to be able to choose any of the four regression methods (random forest, linear regression, KNN, or decision tree). Currently, there is one line of code for creating a linear regression object. To modify this, create a string called method that represents the regressor that the user wants to select (e.g., "LR", "KNN", "DT"), then write an if statement that sets model to the desired ML regressor object. The syntax for creating these objects can be found in the sklearn documentation for KNN \& DT. And finally, each regressor object can have method-specific hyperparameters (in the line of code that creates the regressor; see scikit-learn documentation) that can be adjusted to improve a model's performance. - use_intercept - determines whether to use the term (True or False) For kNN: - n_neighbors - determines the k value of how many neighbors are used in predicting an output - weights - determines whether to use "uniform" (all neighbors are averaged equally) or "distance" (neighbors are weighted based on their distance) - metric - determines the type of distance to use, such as "euclidean", "manhattan", or something els For decision trees: - max_depth - maximum depth of a tree if a number is entered; no maximum if set to None - min_samples_split - minimum number of samples required for a node to split - min_samples_leaf - minimum number of samples required for a node to be a leaf For random forest: - n_estimators - number of trees to create - max_depth - maximum depth of a tree if a number is entered; no maximum if set to None - min_samples_split - minimum number of samples required for a node to split - min_samples_leat - minimum number of samples required for a node to be a leat - bootstrap - if True takes a bootstrap sample for each tree; if False uses the same data for each tree When testing the accuracy (specifically, the mean squared error) of each method, try adjusting the different hyperparameters to see which values provide the best accuracy. And finally, so far, we have only been using one dataset for testing our ML models. For more reliable reporting of results, it is better to utilize more than one dataset. Thus, your last modification to this assignment will be in Step 2 to add least one more regression dataset to compare (you can simply comment out whichever dataset you are not actively loading, or you can write an if statement). Some simple datasets can be found here: https://scikit learn.org/stable/datasets/toy_dataset.html, but you will have to pick a regression dataset such as diabetes or linnerud




