I NEED HELP ON THIS! Basic Python Coding!
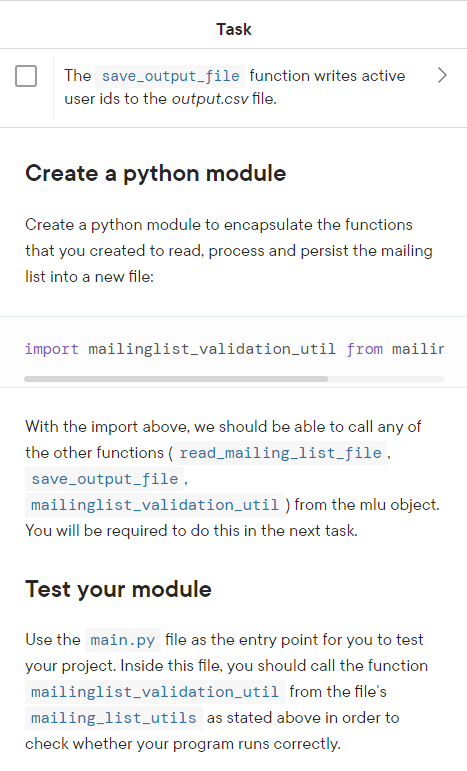
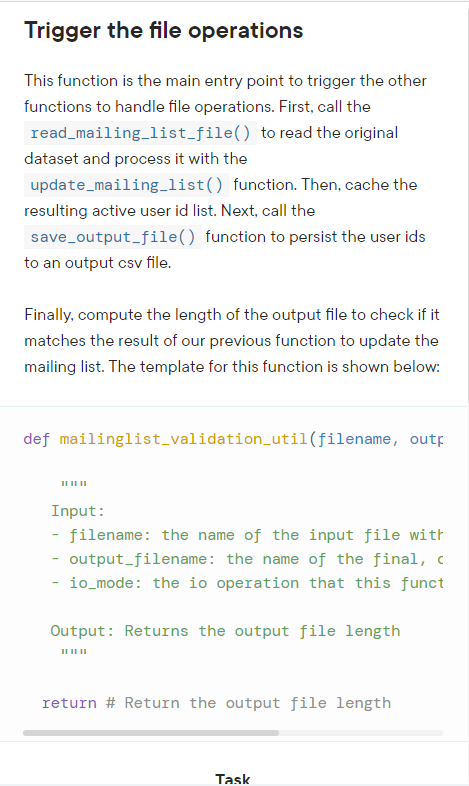
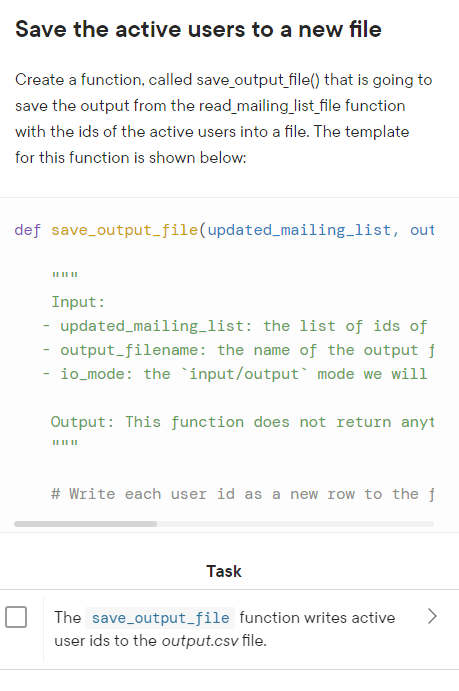
Your implementation is up and running as expected, but as the data grows, TargetCRM needs a way to read and write the data in a more performatic way. Also, the manager will often need to generate reports from the users data, but aggregating values in our current architecture is very resource consuming. In order to make a more stable solution to support future demand, (taking into account that the data grows in at a fast pace), you can take advantage of data analysis library solutions available in python. For this bonus project, you will be introduced to a very popular python data analysis package, called pandas. pandas is a very commonly used python resource and has built-in data structures that are very easy to work with, such as and Dataframes, and several aggregations and analytical functions. To really stand out in this code delivery, TargetCRM offered you a bonus if you figure out a way to implement a more robust and scalable way to read the raw csv data and return the number of users in the mailing list. Below there is a general overview of this bonus project: 1. Install the package using 2. Read the csv file into a The save_output_file function writes active > user ids to the output.csv file. Create a python module Create a python module to encapsulate the functions that you created to read, process and persist the mailing list into a new file: import mailinglist_validation_util from mailir With the import above, we should be able to call any of the other functions (read_mailing_list_file, save_output_file, mailinglist_validation_util ) from the mlu object. You will be required to do this in the next task. Test your module Use the file as the entry point for you to test your project. Inside this file, you should call the function mailinglist_validation_util from the file's mailing_list_utils as stated above in order to check whether your program runs correctly. Trigger the file operations This function is the main entry point to trigger the other functions to handle file operations. First, call the read_mailing_list_file( ) to read the original dataset and process it with the update_mailing_list ( ) function. Then, cache the resulting active user id list. Next, call the save_output_file( ) function to persist the user ids to an output csv file. Finally, compute the length of the output file to check if it matches the result of our previous function to update the mailing list. The template for this function is shown below: def mailinglist_validation_util(filename, outf Input: - filename: the name of the input file witt - output_filename: the name of the final, - io_mode: the io operation that this funct Output: Returns the output file length "n return \# Return the output file length Save the active users to a new file Create a function, called save_output_file() that is going to save the output from the read_mailing_list_file function with the ids of the active users into a file. The template for this function is shown below: def save_output_file(updated_mailing_list, out Input: - updated_mailing_list: the list of ids of - output_filename: the name of the output f - io_mode: the 'input/output' mode we will Output: This function does not return anyt " \# Write each user id as a new row to the f Task The save_output_file function writes active user ids to the output.csv file. that reads in the original dataset from a 'csv' file, transforms it in a python dictionary, and pass the data to the update_mailing_list ( ) function to filter out the 'unsubscribed' users. After that, we return the ids of the active users. The template for this function is shown below: def read_mailing_list_file(filename, io_mode): Input: - filename: the filename of the original de - io_mode: the 'input/output' mode we will Output: the list of ids of the active user ! II return \# Return the resulting ids of the Task The read_mailing_list_file function reads in a CSV file's data and returns the filtered list of ids. mailing_list.csv Files are a great way to persist data, especially small to a main.py mid-size datasets. As a company effort to create a more mor modules_package_.. robust infrastructure to store the email addresses data, they asked you to persist the user emails into csv files. CSV stands for comma-separated values. As the name implies, csv files store data with a comma character separating each field in the data file. The csv format was chosen because of the flexibility of working with this type of file and the great support from analytic tools, such as Excel, and, becoming more popular in recent years, BI tools. As data generated by the users grow, the company wants to use this data in the future to analyze it and get informative data from it. Another facility to work with files is that we can distribute them in the company's local environment to work in parallel. So, if the mailing list database increases in a pace that we cannot store every user in a single file, we can distribute the users among several csv files and process files separately, or in batches, and then gather them together when we need to perform some sort of analysis. This sort of capability is very desirable in today's real applications as the data generated by online users is increasing at a very fast pace. Module Lab Assessment 8: Mailing List Validation File Processing Overview TargetCRM is a CRM software company that is currently looking for a way to improve the architecture of its solution. The software sends emails to registered users every week and today the system does not have a proper, structured way to persist the mailing list data, so the data is stored in in-memory data structures like dictionaries and lists. As working with data structures like dictionaries in Python might be memory (resource) consuming and not failure-proof (that is, any hardware/software failure might lead the data to be lost forever if the only place we have them is in memory), we need to move the project to a more robust, structured way of storing data




