

Question: I ordered the images, you can see the question in order. I need python code, firstly I couldn't even invest the data as dictionary format.

 I ordered the images, you can see the question in order. I need python code, firstly I couldn't even invest the data as dictionary format. Please write python code. Thank you!
I ordered the images, you can see the question in order. I need python code, firstly I couldn't even invest the data as dictionary format. Please write python code. Thank you!
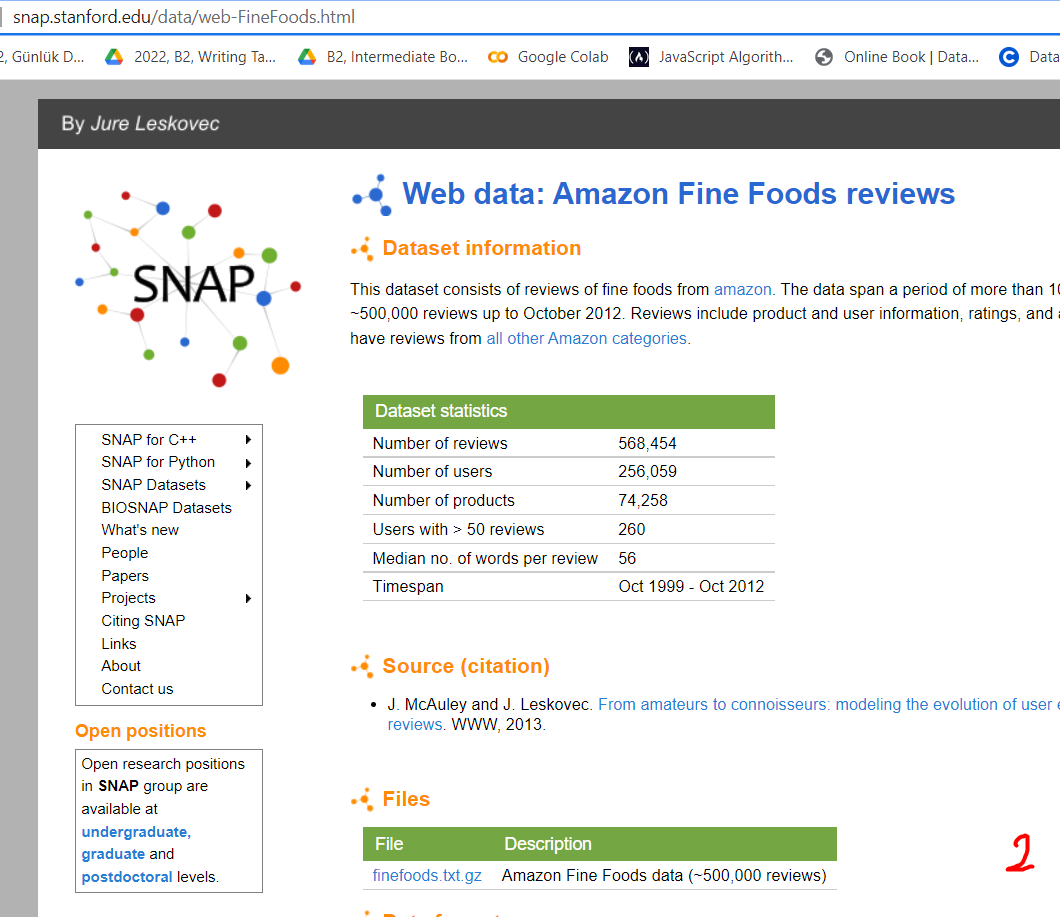
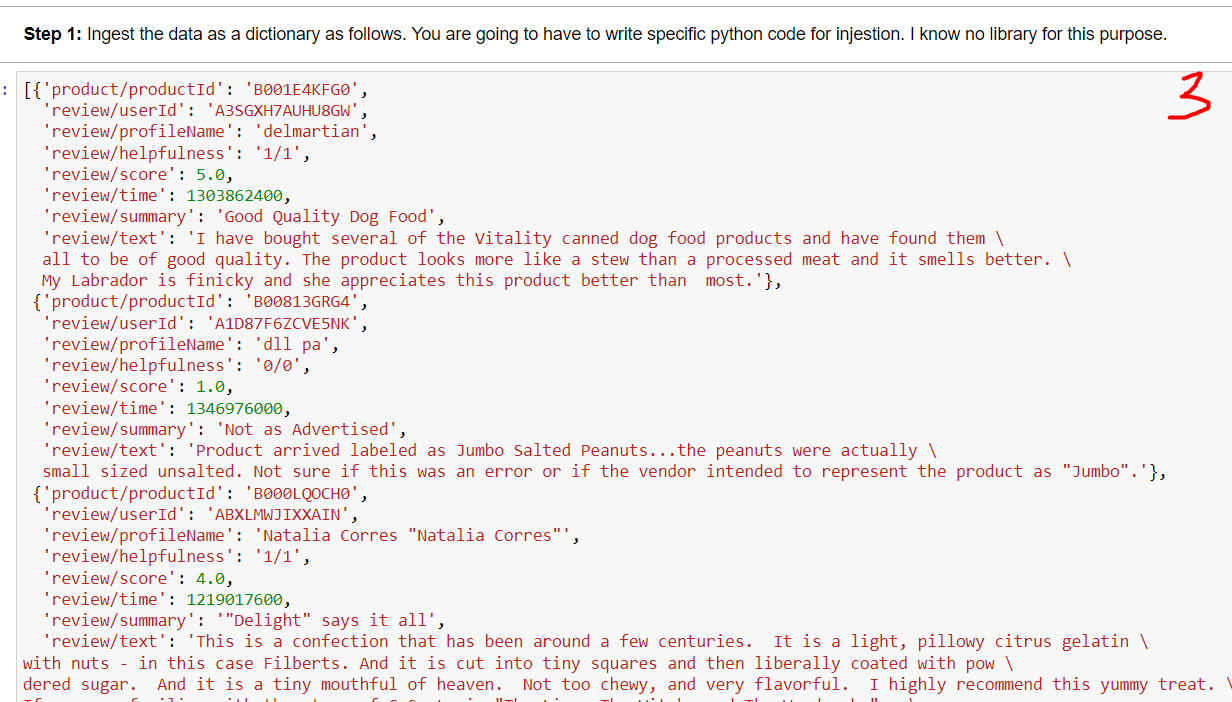
For this question we are going to use Amazon Fine Foods reviews from Stanford Network Analysis Project (SNAP). The dataset is very large (Approximately 500K entries). Here is a sample of the data: Web data: Amazon Fine Foods reviews Dataset information This dataset consists of reviews of fine foods from amazon. The data span a period of more than 1 500,000 reviews up to October 2012 . Reviews include product and user information, ratings, and have reviews from all other Amazon categories. Source (citation) - J. McAuley and J. Leskovec. From amateurs to connoisseurs: modeling the evolution of user reviews. WWW, 2013. Open positions Open research positions in SNAP group are available at Files undergraduate, graduate and postdoctoral levels. Step 1: Ingest the data as a dictionary as follows. You are going to have to write specific python code for injestion. I know no library for this purpose. Step 2: Convert the injested JSON into a pandas dataframe. Step 3: Calculate the average score for each product and store is as a pandas dataframe. Step 4: From the original dataframe filter out (remove) all products that has less than 100 reviews. Get the resulting list of productld's. How many products do we have satisfying this condition? Step 5: From the original dataframe filter out (remove) all users that has less than 50 reviews. Get the resulting list of userid's. How many users do we have satisfying this condition? Step 6: On the original dataframe filter out (remove) all users that has less than 50 reviews and all products that has less than 100 reviews. Use the lists from Step 4 and 5. Step 7: Create a pivot table for userld's vs productld's. Step 8: Normalize each row by dividing each row with the sum of that row. Call the dataframe result Step 9: Multiply result with its transpose result. T in two different ways. Now, you obtained two similarity matrices: one for users, the other for products. Step 10: Construct a networkx network of users and a network of products. Sketch the networks. Observe that these networks are too complicated to understand. Step 11: Remove some edges by setting threshold for the similarity value. Experiment few values and choose an appropriate value, and sketch the final results for both user and product networks. For this question we are going to use Amazon Fine Foods reviews from Stanford Network Analysis Project (SNAP). The dataset is very large (Approximately 500K entries). Here is a sample of the data: Web data: Amazon Fine Foods reviews Dataset information This dataset consists of reviews of fine foods from amazon. The data span a period of more than 1 500,000 reviews up to October 2012 . Reviews include product and user information, ratings, and have reviews from all other Amazon categories. Source (citation) - J. McAuley and J. Leskovec. From amateurs to connoisseurs: modeling the evolution of user reviews. WWW, 2013. Open positions Open research positions in SNAP group are available at Files undergraduate, graduate and postdoctoral levels. Step 1: Ingest the data as a dictionary as follows. You are going to have to write specific python code for injestion. I know no library for this purpose. Step 2: Convert the injested JSON into a pandas dataframe. Step 3: Calculate the average score for each product and store is as a pandas dataframe. Step 4: From the original dataframe filter out (remove) all products that has less than 100 reviews. Get the resulting list of productld's. How many products do we have satisfying this condition? Step 5: From the original dataframe filter out (remove) all users that has less than 50 reviews. Get the resulting list of userid's. How many users do we have satisfying this condition? Step 6: On the original dataframe filter out (remove) all users that has less than 50 reviews and all products that has less than 100 reviews. Use the lists from Step 4 and 5. Step 7: Create a pivot table for userld's vs productld's. Step 8: Normalize each row by dividing each row with the sum of that row. Call the dataframe result Step 9: Multiply result with its transpose result. T in two different ways. Now, you obtained two similarity matrices: one for users, the other for products. Step 10: Construct a networkx network of users and a network of products. Sketch the networks. Observe that these networks are too complicated to understand. Step 11: Remove some edges by setting threshold for the similarity value. Experiment few values and choose an appropriate value, and sketch the final results for both user and product networks
Step by Step Solution
There are 3 Steps involved in it

Get step-by-step solutions from verified subject matter experts