

Question
I wrote this python script to scrape a webpage. The formatting is coming out weird in the csv file, I want everything in 2 columns
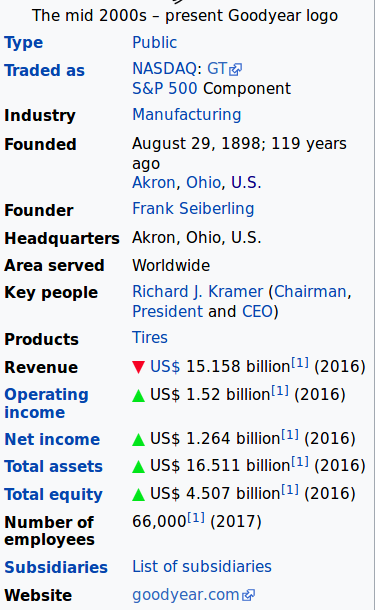
I wrote this python script to scrape a webpage. The formatting is coming out weird in the csv file, I want everything in 2 columns but some it scattered around. Also, the B column needs to be shifted up one, so type should be in the same row as public, traded as should be in the same row as NASDAQ:GT S&P 500 component. How do i fix that? thanks, the website name is also not appearing from the webpage, how do i fix that? I attached how i would like it to look in the csv file, thanks
import requests import csv from datetime import datetime from bs4 import BeautifulSoup
# download the page myurl = requests.get("https://en.wikipedia.org/wiki/Goodyear_Tire_and_Rubber_Company") # create BeautifulSoup object soup = BeautifulSoup(myurl.text, 'html.parser')
# pull the class containing all tire name name = soup.find(class_ = 'logo') # pull the div in the class nameinfo = name.find('div')
# just grab text inbetween the div nametext = nameinfo.text
# print information about goodyear logo on wiki page #print(nameinfo)
# now, print type of company, private or public #status = soup.find(class_ = 'category') #for link in soup.select('td.category a'): #print link.text
# now get the ceo information #for employee in soup.select('td.agent a'): # print employee.text
# print area served #area = soup.find(class_ = 'infobox vcard') #print(area)
# grab information in bold on the left hand side vcard = soup.find(class_ = 'infobox vcard') rows = vcard.find_all('tr') first = [] for row in rows: cols = row.find_all('th') for x in cols: first.append(str(x.text.strip())) ## Storing data in string form #first.append([x.text.strip() for x in cols]) ## Storing data in list form #print cols
vcard = soup.find(class_ = 'infobox vcard') rows = vcard.find_all('tr') second = [] for row in rows: cols2 = row.find_all('td') for x in cols2: second.append(str(x.text.strip())) ## Storing data in string form #second.append([x.text.strip() for x in cols2]) ## Storing data in list form #print second
with open('index.csv', 'w') as csv_file: for f,s in zip(first,second): csv_file.write(str(f) + "," + str(s)) csv_file.write(" ") print(f,s)
The mid 2000s - present Goodyear logo Type Traded as Public NASDAQ: GT S&P 500 Component Manufacturing Industry August 29, 1898; 119 years ago Akron, Ohio, U.S Frank Seiberling Founded Founder Headquarters Akron, Ohio, U.S Area served Worldwide Key people Richard J. Kramer (Chairman, President and CEO) Tires Products Revenue Operating US$ 1.52 billion 11 (2016) US$ 15.158 billion 1l (2016) income Net income US$ 1.264 billion!11 (2016) Total assets US$ 16.511 billion 11 (2016) Total equity US$ 4.507 billion 11 (2016) Number of 66,000111 (2017) employees Subsidiaries List of subsidiaries Website goodyear.com
Step by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
PostgreSQL 10 High Performance Expert Techniques For Query Optimization High Availability And Efficient Database Maintenance
Authors: Ibrar Ahmed ,Gregory Smith ,Enrico Pirozzi
3rd Edition
1788474481, 978-1788474481