

Answered step by step
Verified Expert Solution
Question
1 Approved Answer
import pandas as pd import numpy as np from sklearn.model_selection import train_test_split mush_df = pd.read_csv('assets/mushrooms.csv') mush_df2 = pd.get_dummies(mush_df) X_mush = mush_df2.iloc[:,2:] y_mush = mush_df2.iloc[:,1] X_train2,
import pandas as pd import numpy as np from sklearn.model_selection import train_test_split
mush_df = pd.read_csv('assets/mushrooms.csv') mush_df2 = pd.get_dummies(mush_df)
X_mush = mush_df2.iloc[:,2:] y_mush = mush_df2.iloc[:,1]
X_train2, X_test2, y_train2, y_test2 = train_test_split(X_mush, y_mush, random_state=0)


*this is my code def answer_six():
from sklearn.svm import SVC
from sklearn.model_selection import validation_curve
param_range = np.logspace(-4,1,6)
train_scores, test_scores = validation_curve(SVC(random_state=0),X_test2,y_test2,param_name='gamma',param_range=param_range)
return np.array(list(map(np.mean,train_scores))),np.array(list(map(np.mean,test_scores)))
answer_six()
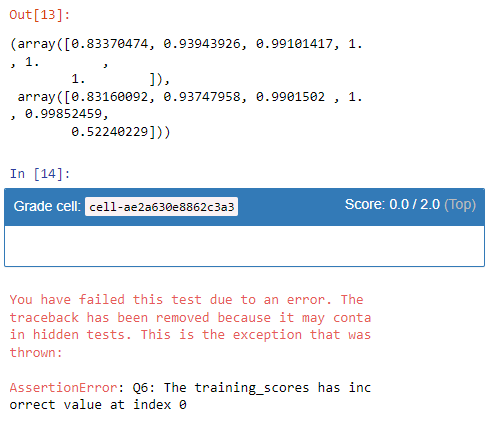 CAN SOMEONE HELP ME TO SOLVE MY PROBLEM?? I KEEP GETTING THIS FEEDBACK!!
CAN SOMEONE HELP ME TO SOLVE MY PROBLEM?? I KEEP GETTING THIS FEEDBACK!!
Step by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started