

Question
import warnings warnings.filterwarnings(ignore) import os import pandas as pd import numpy as np import matplotlib.pyplot as plt np.random.seed(0) # Do not change this value: required


import warnings
warnings.filterwarnings("ignore")
import os
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(0) # Do not change this value: required to be compatible with solutions generated by the autograder.
def engagement_model()
*Your code here*
stu_ans = engagement_model()
assert isinstance(stu_ans, pd.Series), "Your function should return a pd.Series. "
assert len(stu_ans) == 2309, "Your series is of incorrect length: expected 2309 "
assert np.issubdtype(stu_ans.index.dtype, np.integer), "Your answer pd.Series should have an index of integer type representing video id." PLEASE HELP ME TO FINISH THE CODE ABOVE, I Meet some trouble in completing it!!
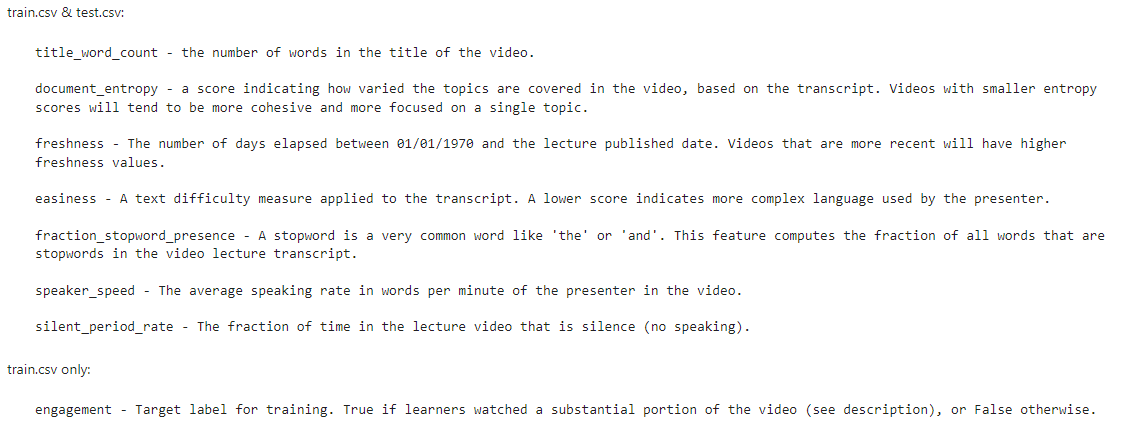
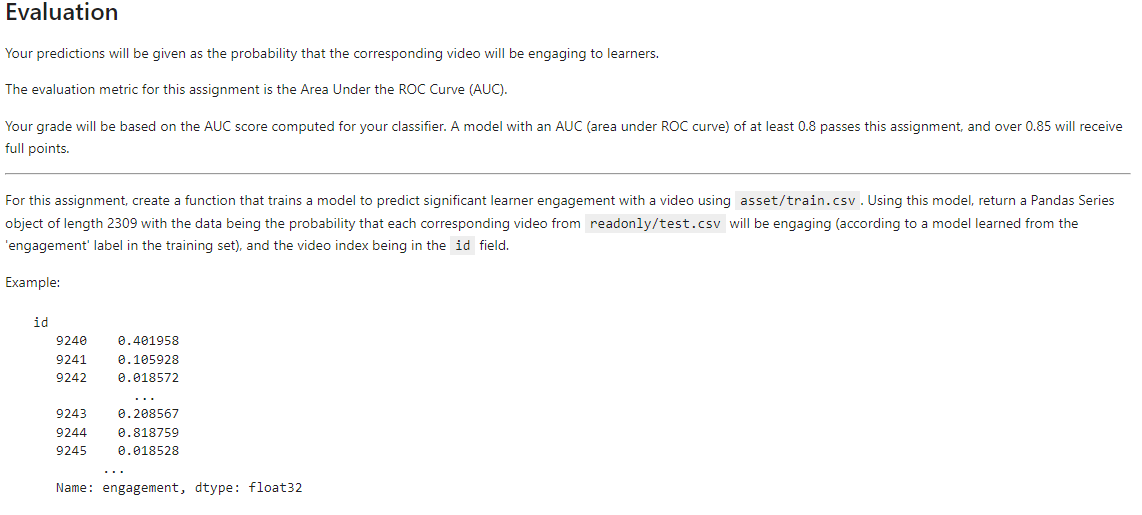
About the prediction problem One critical property of a video is engagement: how interesting or "engaging" it is for viewers, so that they decide to keep watching. Engagement is critical for learning, whether the instruction is coming from a video or any other source. There are many ways to define engagement with video, but one common approach is to estimate it by measuring how much of the video a user watches. If the video is not interesting and does not engage a viewer, they will typically abandon it quickly, e.g. only watch 5 or 10% of the total. A first step towards providing the best-matching educational content is to understand which features of educational material make it engaging for learners in general. This isere predictive modeling can be applied, via supervised machine learning. For this assignment, your task is to predict how engaging an educational video is likely to be for viewers, based on a set of features extracted from the video's transcript, audio track, hosting site, and other sources. We chose this prediction problem for several reasons: - It combines a variety of features derived from a rich set of resources connected to the original data; - The manageable dataset size means the dataset and supervised models for it can be easily explored on a wide variety of computing platforms; - Predicting popularity or engagement for a media item, especially combined with understanding which features contribute to its success with viewers, is a fun problem but also a practical representative application of machine learning in a number of business and educational sectors. About the dataset We extracted training and test datasets of educational video features from the VLE Dataset put together by researcher Sahan Bulathwela at University College London. We provide you with two data files for use in training and validating your models: train.csv and test.csv. Each row in these two files corresponds to a single educational video, and includes information about diverse properties of the video content as described further below. The target variable is which was defined as True if the median percentage of the video watched across all viewers was at least 30%, and False otherwise. Note: Any extra variables that may be included in the training set are simply for your interest if you want an additional source of data for visualization, or to enable unsupervised and semi-supervised approaches. However, they are not included in the test set and thus cannot be used for prediction. Only the data already included in your Coursera directory can be used for training the model for this assignment. For this final assignment, you will bring together what you've learned across all four weeks of this course, by exploring different prediction models for this new dataset. In addition, we encourage you to apply what you've learned about model selection to do hyperparameter tuning using training/validation splits of the training data, to optimize the model and further increase its performance. In addition to a basic evaluation of model accuracy, we've also provided a utility function to visualize which features are most and least contributing to the overall model performance. title_word_count - the number of words in the title of the video. document_entropy - a score indicating how varied the topics are covered in the video, based on the transcript. Videos with smaller entropy scores will tend to be more cohesive and more focused on a single topic. freshness - The number of days elapsed between 01/01/1970 and the lecture published date. Videos that are more recent will have higher freshness values. easiness - A text difficulty measure applied to the transcript. A lower score indicates more complex language used by the presenter. fraction_stopword_presence - A stopword is a very common word like 'the' or 'and'. This feature computes the fraction of all words that are stopwords in the video lecture transcript. speaker_speed - The average speaking rate in words per minute of the presenter in the video. silent_period_rate - The fraction of time in the lecture video that is silence (no speaking). train.csv only: engagement - Target label for training. True if learners watched a substantial portion of the video (see description), or False otherwise. Your predictions will be given as the probability that the corresponding video will be engaging to learners. The evaluation metric for this assignment is the Area Under the ROC Curve (AUC). Your grade will be based on the AUC score computed for your classifier. A model with an AUC (area under ROC curve) of at least 0.8 passes this assignment, and over 0.85 will receive full points. For this assignment, create a function that trains a model to predict significant learner engagement with a video using Using this model, return a Pandas Series object of length 2309 with the data being the probability that each corresponding video from will be engaging (according to a model learned from the 'engagement' label in the training set), and the video index being in the id field. Example: Name: engagement, dtype: float32Step by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
Introduction To Database And Knowledge Base Systems
Authors: S Krishna
1st Edition
9810206208, 978-9810206208