

Question
[In Java] Please correct the following code. [Note] Everything is in the lexar package. Except TokenSetup.java and tokens -> This is in the setup folder
[In Java] Please correct the following code. [Note] Everything is in the "lexar" package. Except TokenSetup.java and tokens -> This is in the setup folder as shown in the picture. 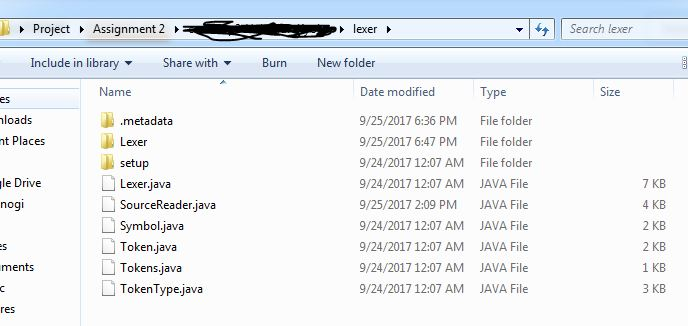
//Lexar.java
package lexer;
/** * The Lexer class is responsible for scanning the source file * which is a stream of characters and returning a stream of * tokens; each token object will contain the string (or access * to the string) that describes the token along with an * indication of its location in the source program to be used * for error reporting; we are tracking line numbers; white spaces * are space, tab, newlines */ public class Lexer { private boolean atEOF = false; // next character to process private char ch; private SourceReader source;
// positions in line of current token private int startPosition, endPosition;
public Lexer(String sourceFile) throws Exception { // init token table new TokenType(); source = new SourceReader(sourceFile); ch = source.read(); }
public static void main(String args[]) { Token tok; Lexer lex = null; try { lex = new Lexer("simple.x"); while (true) { tok = lex.nextToken(); System.out.println("L: " + tok.getLeftPosition() + " R: " + tok.getRightPosition() + " " + tok.toString() + " : " + lex.source.getLineno()); } } catch (Exception e) { } }
/** * newIdTokens are either ids or reserved words; new id's will be inserted * in the symbol table with an indication that they are id's * * @param id is the String just scanned - it's either an id or reserved word * @param startPosition is the column in the source file where the token begins * @param endPosition is the column in the source file where the token ends * @return the Token; either an id or one for the reserved words */ public Token newIdToken(String id, int startPosition, int endPosition) { return new Token(startPosition, endPosition, Symbol.symbol(id, Tokens.Identifier)); }
/** * number tokens are inserted in the symbol table; we don't convert the * numeric strings to numbers until we load the bytecodes for interpreting; * this ensures that any machine numeric dependencies are deferred * until we actually run the program; i.e. the numeric constraints of the * hardware used to compile the source program are not used * * @param number is the int String just scanned * @param startPosition is the column in the source file where the int begins * @param endPosition is the column in the source file where the int ends * @return the int Token */ public Token newNumberToken(String number, int startPosition, int endPosition, int lineNumber) { return new Token( startPosition, endPosition, Symbol.symbol(number, Tokens.INTeger) ); }
/** * build the token for operators (+ -) or separators (parens, braces) * filter out comments which begin with two slashes * * @param s is the String representing the token * @param startPosition is the column in the source file where the token begins * @param endPosition is the column in the source file where the token ends * @return the Token just found */ public Token makeToken(String s, int startPosition, int endPosition) { if (s.equals("//")) { // filter comment try { int oldLine = source.getLineno();
do { ch = source.read(); } while (oldLine == source.getLineno()); } catch (Exception e) { atEOF = true; }
return nextToken(); }
// be sure it's a valid token Symbol sym = Symbol.symbol(s, Tokens.BogusToken); if (sym == null) { System.out.println("******** illegal character: " + s); atEOF = true; return nextToken(); }
return new Token(startPosition, endPosition, sym); }
/** * @return the next Token found in the source file */ public Token nextToken() { // ch is always the next char to process if (atEOF) { if (source != null) { source.close(); // source = null; }
return null; }
// scan past whitespace try { while (Character.isWhitespace(ch)) { ch = source.read(); } } catch (Exception e) { atEOF = true; return nextToken(); }
startPosition = source.getPosition(); endPosition = startPosition - 1;
if (Character.isJavaIdentifierStart(ch)) { // return tokens for ids and reserved words String id = ""; try { do { endPosition++; id += ch; ch = source.read(); } while (Character.isJavaIdentifierPart(ch)); } catch (Exception e) { atEOF = true; }
return newIdToken(id, startPosition, endPosition); }
if (Character.isDigit(ch)) { // return number tokens String number = ""; try { do { endPosition++; number += ch; ch = source.read(); } while (Character.isDigit(ch)); } catch (Exception e) { atEOF = true; }
return newNumberToken(number, startPosition, endPosition, source.getLineno()); }
// At this point the only tokens to check for are one or two // characters; we must also check for comments that begin with // 2 slashes String charOld = "" + ch; String op = charOld; Symbol sym; try { endPosition++; ch = source.read(); op += ch; // check if valid 2 char operator; if it's not in the symbol // table then don't insert it since we really have a one char // token sym = Symbol.symbol(op, Tokens.BogusToken);
if (sym == null) { // it must be a one char token return makeToken(charOld, startPosition, endPosition); }
endPosition++; ch = source.read(); return makeToken(op, startPosition, endPosition); } catch (Exception e) { }
atEOF = true; if (startPosition == endPosition) { op = charOld; } return makeToken(op, startPosition, endPosition); }
@Override public String toString() { return source.toString(); } }
//SourceReader.java
package lexer;
import java.io.*;
/** * This class is used to manage the source program input stream; * each read request will return the next usable character; it * maintains the source column position of the character */ public class SourceReader { private BufferedReader source; //https://docs.oracle.com/javase/7/docs/api/java/io/BufferedReader.html // line number of source program private int lineno = 0, // position of last character processed position; // if true then last character read was newline private boolean isPriorEndLine = true; // so read in the next line private String nextLine; private StringBuilder builder;
// public static void main( String args[] ) { // SourceReader s = null; // try { // s = new SourceReader( "t" ); // // while( true ) { // char ch = s.read(); // System.out.println( "Char: " + ch + " Line: " + s.lineno + "position: " + s.position ); // } // } catch (Exception e) {} // // if( s != null ) { // s.close(); // } // }
/** * Construct a new SourceReader * * @param sourceFile the String describing the user's source file * @throws IOException is thrown if there is an I/O problem */ public SourceReader(String sourceFile) throws IOException { System.out.println("Source file: " + sourceFile); System.out.println("user.dir: " + System.getProperty("user.dir")); source = new BufferedReader(new FileReader(sourceFile)); builder = new StringBuilder(); }
void close() { try { source.close(); } catch (Exception e) { } }
/** * read next char; track line #, character position in line * return space for newline * * @return the character just read in * @IOException is thrown for IO problems such as end of file */ public char read() throws IOException { if (isPriorEndLine) { lineno++; position = -1; nextLine = source.readLine();
if (nextLine != null) { System.out.println("READLINE: " + nextLine);
builder.append(String.format(" %d: %s", lineno, nextLine)); }
isPriorEndLine = false; }
if (nextLine == null) { // hit eof or some I/O problem throw new IOException(); }
if (nextLine.length() == 0) { isPriorEndLine = true; return ' '; } position++;
if (position >= nextLine.length()) { isPriorEndLine = true; return ' '; }
return nextLine.charAt(position); }
/** * @return the position of the character just read in */ public int getPosition() { return position; }
/** * @return the line number of the character just read in */ public int getLineno() { return lineno; }
@Override public String toString() { return builder.toString(); } } //Symbol.java
package lexer;
import java.util.HashMap;
/** * The Symbol class is used to store all user strings along with * an indication of the kind of strings they are; e.g. the id "abc" will * store the "abc" in name and Sym.Tokens.Identifier in kind */ public class Symbol { private String name; // token kind of symbol private Tokens kind;
private Symbol(String n, Tokens kind) { name = n; this.kind = kind; }
// symbols contains all strings in the source program private static HashMap
public String toString() { return name; }
public Tokens getKind() { return kind; }
/** * Return the unique symbol associated with a string. * Repeated calls to symbol("abc") will return the same Symbol. */ public static Symbol symbol(String newTokenString, Tokens kind) { Symbol s = symbols.get(newTokenString);
if (s == null) { // bogus string so don't enter into symbols if (kind == Tokens.BogusToken) { return null; }
//System.out.println("new symbol: "+u+" Kind: "+kind); s = new Symbol(newTokenString, kind); symbols.put(newTokenString, s); }
return s; } }
//Token.java
package lexer;
/** *
* The Token class records the information for a token: * 1. The Symbol that describes the characters in the token * 2. The starting column in the source file of the token and * 3. The ending column in the source file of the token **/ public class Token { private int leftPosition, rightPosition; private Symbol symbol;
/** * Create a new Token based on the given Symbol * * @param leftPosition is the source file column where the Token begins * @param rightPosition is the source file column where the Token ends * @param sym */ public Token(int leftPosition, int rightPosition, Symbol sym) { this.leftPosition = leftPosition; this.rightPosition = rightPosition; this.symbol = sym; }
public Symbol getSymbol() { return symbol; }
public String toString() { return symbol.toString(); }
public int getLeftPosition() { return leftPosition; }
public int getRightPosition() { return rightPosition; }
/** * @return the integer that represents the kind of symbol we have which * is actually the type of token associated with the symbol */ public Tokens getKind() { return symbol.getKind(); } }
//Tokens.java
package lexer;
/** * This file is automatically generated * - it contains the enumeration of all of the tokens */ public enum Tokens { BogusToken, Program, Int, BOOLean, If, Then, Else, While, Function, Return, Identifier, INTeger, LeftBrace, RightBrace, LeftParen, RightParen, Comma, Assign, Equal, NotEqual, Less, LessEqual, Plus, Minus, Or, And, Multiply, Divide, Comment }
//TokenType.java
package lexer;
/** * This file is automatically generated * it contains the table of mappings from token * constants to their Symbols */ public class TokenType { public static java.util.HashMap
public TokenType() { tokens.put(Tokens.Program, Symbol.symbol("program", Tokens.Program)); tokens.put(Tokens.Int, Symbol.symbol("int", Tokens.Int)); tokens.put(Tokens.BOOLean, Symbol.symbol("boolean", Tokens.BOOLean)); tokens.put(Tokens.If, Symbol.symbol("if", Tokens.If)); tokens.put(Tokens.Then, Symbol.symbol("then", Tokens.Then)); tokens.put(Tokens.Else, Symbol.symbol("else", Tokens.Else)); tokens.put(Tokens.While, Symbol.symbol("while", Tokens.While)); tokens.put(Tokens.Function, Symbol.symbol("function", Tokens.Function)); tokens.put(Tokens.Return, Symbol.symbol("return", Tokens.Return)); tokens.put(Tokens.Identifier, Symbol.symbol(" //TokenSetup.java package lexer.setup; import java.util.*; import java.io.*; /** * TokenSetup class is used to read the tokens from file tokens * and automatically build the 2 classes/files TokenType.java * and Sym.java * Therefore, if there is any change to the tokens then we only need to * modify the file tokens and run this program again before using the * compiler */ public class TokenSetup { // token type/value for new token private String type, value; private int tokenCount = 0; private BufferedReader in; // files used for new classes private PrintWriter table, symbols; public static void main(String args[]) { new TokenSetup().initTokenClasses(); } TokenSetup() { try { System.out.println( "User's current working directory: " + System.getProperty("user.dir") ); String sep = System.getProperty("file.separator"); in = new BufferedReader(new FileReader("lexer" + sep + "setup" + sep + "tokens")); table = new PrintWriter(new FileOutputStream("lexer" + sep + "TokenType.java")); symbols = new PrintWriter(new FileOutputStream("lexer" + sep + "Tokens.java")); } catch (Exception e) { System.out.println(e); } } /** * read next line which contains token information; * each line will contain the token type used in lexical analysis and * the printstring of the token: e.g. *
*/ public void getNextToken() throws IOException { try { StringTokenizer st = new StringTokenizer(in.readLine()); type = st.nextToken(); value = st.nextToken(); } catch (NoSuchElementException e) { System.out.println("***tokens file does not have 2 strings per line***"); System.exit(1); } catch (NullPointerException ne) { // attempt to build new StringTokenizer when at end of file throw new IOException("***End of File***"); }
tokenCount++; }
/** * initTokenClasses will create the 2 files */ public void initTokenClasses() { table.println("package lexer;"); table.println(" "); table.println("/**"); table.println(" * This file is automatically generated "); table.println(" * it contains the table of mappings from token"); table.println(" * constants to their Symbols"); table.println("*/"); table.println("public class TokenType {"); table.println(" public static java.util.HashMap
while (true) { try { getNextToken(); } catch (IOException e) { break; }
String symType = "Tokens." + type;
table.println(" tokens.put(" + symType + ", Symbol.symbol(\"" + value + "\"," + symType + "));");
if (tokenCount % 5 == 0) { symbols.print(", " + type); } else { symbols.print("," + type); } }
table.println(" }"); table.println("}"); table.close(); symbols.println(" }"); symbols.close();
try { in.close(); } catch (Exception e) { } } }
//Tokens
Program program Int int BOOLean boolean If if Then then Else else While while Function function Return return Identifier
Step by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
Database Processing Fundamentals Design And Implementation
Authors: KROENKE DAVID M.
1st Edition
8120322258, 978-8120322257