

Question
In this problem, we will be examining the performance of the instruction cache on the MIPS assembly program shown on the next page. The first
In this problem, we will be examining the performance of the instruction cache on the MIPS
assembly program shown on the next page. The first column shows the instruction address for
each instruction. Note that these addresses are byte addresses. The value of r1 is initially 64,
meaning that there are 64 iterations in the loop. In this problem, we will be considering the
execution of this loop with a direct-mapped instruction cache microarchitecture with eight
cache lines, and each cacheline is 16B. This means each cache line can hold four instructions
and the bottom four bits of an instruction address are the block offset. Hint: The first
instruction in the code segment (i.e., addiu r1, r1, -1), is in the middle of a cache line
with starting address 0x100.
For this problem, the instruction cache hit time is two cycles, but it is fully pipelined. Tag
check occurs in the first cycle, and if it is a hit, the instruction is read in the second cycle.
Essentially, this creates a six-stage pipelined processor with the following stages: instruction
cache tag check (F0), instruction cache data access (F1), decode (D), execute (X), memory
(M), and write-back (W). This also implies the data cache hit time is one cycle.
Assume that jumps are resolved in the decode stage and that branches are re- solved in the execute stage. Assume the miss penalty is three cycles so on a
cache miss the pipeline will stay in F0 for a total of three cycles, go into F1 for
one cycle, and then continue as normal. You should assume that in every other
way, the processor pipeline follows the classic fully-bypassed five-stage pipeline.
Assume that the processor does not include a branch delay slot. Assume the
processor speculatively predicts all jumps and branches are not taken.
1.
Draw a pipeline diagram illustrating the first iteration of the loop assuming there are no
instruction cache misses. Remember that there are two fetch stages (F0 and F1). Show stalls
by simply repeating the pipeline stage character (e.g., D) for multiple consecutive cycles.
Use a dash (-) to indicate pipeline bubbles caused by killing instructions (pipeline flushes).
You should show all instructions in the first iteration of the loop and the first instruction of
the second iteration that you can properly draw the control dependency for the backwards
branch.
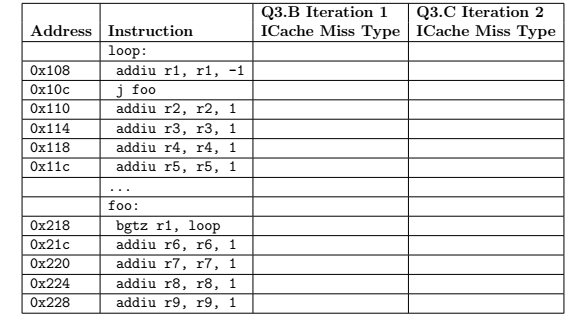
2. First Iteration of the Loop
Fill in the table above. In the appropriate column, write compulsory, conflict, or capacity next
to each instruction which misses in the instruction cache to indicate the type of instruction
cache misses that occur in the first iteration of the loop. Assume that the instruction
cache is initially completely empty. Now draw a pipeline diagram illustrating the first
iteration of the loop including instruction cache misses. Clearly indicate the number of cycles
it takes to execute the first iteration.
3. Second Iteration of the Loop and overall CPI
Continue to fill in the table above. Write compulsory, conflict, or capacity next to each
instruction which misses in the instruction cache to indicate the type of instruction caches
misses that occur in the second iteration of the loop. Now draw a pipeline diagram illustrating
the second iteration of the loop. Clearly indicate the number of cycles it takes to execute the
second iteration. Calculate the CPI for this processor executing all 64 iteration of the loop
(Note: The CPI calculation should not include instructions that are fetched but
then later squashed).
Step by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
Database Processing
Authors: David J. Auer David M. Kroenke
13th Edition
B01366W6DS, 978-0133058352